Intelligent Database Insights With Agentic AI for YugabyteDB Metadata
February 26, 2025
Data is the lifeblood of modern applications. Distributed SQL databases like YugabyteDB deliver unparalleled scalability and resilience, but also need to overcome complex challenges when managing and optimizing the vast quantities of metadata required in today’s fast-paced digital landscape.
Imagine an AI-powered assistant that can understand your database’s schema, performance metrics, indexes, constraints, and even suggest optimizations-all through natural language queries. Welcome to Agentic AI for YugabyteDB Metadata. This is where cutting-edge AI meets the robust, PostgreSQL-compatible foundation of YugabyteDB to deliver actionable insights at lightning speed.
In this blog, we discuss how Agentic AI for YugabyteDB Metadata transforms how organizations interact with their distributed SQL database by providing intelligent, real-time insights through natural language queries.
Instead of manually analyzing performance metrics, indexes, and schema structures, AI-driven automation suggests optimizations, detects anomalies, and streamlines metadata management. Developers can instantly diagnose slow queries, data engineers can optimize workloads, business analysts can retrieve insights without writing SQL, and IT teams can proactively address performance issues.
By bridging the gap between technical and non-technical users, this AI-powered approach enhances database efficiency, reduces operational overhead, and ensures that YugabyteDB runs at peak performance to deliver scalability and resilience without complexity.
Why YugabyteDB’s PostgreSQL 15 Compatibility is Key
A cornerstone of this solution is YugabyteDB’s compatibility with PostgreSQL 15. This compatibility isn’t just about supporting familiar SQL syntax-it extends to system catalogs, extensions, and performance metrics. Here’s why this matters:
- Seamless Metadata Access: YugabyteDB’s PostgreSQL 15 compatibility allows it to use standard system views (like
information_schema.tables,pg_indexes, andpg_constraint) without modifications. This ensures that the rich metadata needed for our AI agent is readily available. - Consistent Performance Monitoring: Features such as
pg_stat_statementsandpg_stat_activitywork out of the box, providing performance metrics that are critical for identifying slow queries and tuning performance. - Familiar Ecosystem: DBAs and developers can leverage the vast ecosystem of PostgreSQL tools and best practices. This minimizes the learning curve and enables faster adoption of the AI-powered solution.
- Scalability with Modern Workloads: YugabyteDB’s distributed nature combined with PostgreSQL 15 features means that even as your data grows, the system remains robust and efficient. This makes it the perfect foundation for an AI agent that scales alongside your business.
Architectural Overview
YugabyteDB’s Agentic AI architecture is designed to bridge the gap between raw database metadata and intelligent, natural language insights. Here’s a high-level overview:
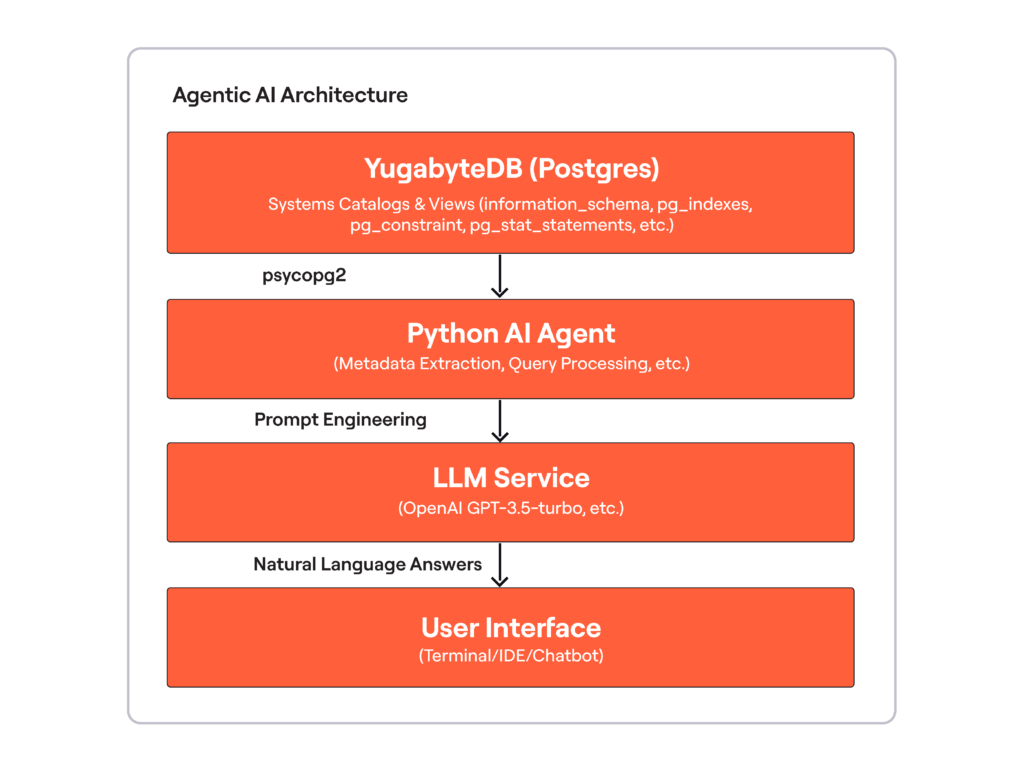
How It Works:
- Connection and Metadata Harvesting
The Python AI agent connects to YugabyteDB usingpsycopg2and executes queries against PostgreSQL’s system catalogs to retrieve information about tables, columns, indexes, and constraints. This data is merged into a full metadata JSON object. - Query Routing and Processing
When a user enters a natural language query (e.g., “List the table in product schema that has the most indexes”), the agent analyzes the query, determines the relevant branch (schema request, performance query, index analysis, etc.), and crafts a detailed prompt. - LLM Integration
The prompt is sent to an LLM service (initially OpenAI’s GPT-3.5-turbo), which processes the prompt and returns a clear, actionable response. This response is then presented to the user. - Continuous Interaction
The system operates in a continuous loop, allowing users to ask follow-up questions or explore different aspects of the database in real-time
Python AI Agent Code Walkthrough: Bringing Intelligence to Metadata
Refer to this complete code snippet to implement the solution. This code includes:
- Metadata extraction for columns, indexes, and constraints
- Performance metric retrieval
- Query processing that supports multiple branches (e.g., schema requests, index analysis, performance queries)
- LLM integration for generating natural language responses
Example Prompts
Here are some example queries you can try with this system:
- Schema and Table Overviews
- “List all table names in the database.”
- “How many tables are there in the database?”
- “Provide an overview of the database schema.”
- Schema-Specific Counts
- “How many tables are in the package schema?”
- “How many tables are in the product schema?”
- Detailed Schema Requests
- “What is the schema of ‘product.version_mgmt_log’ table?”
- “Show me the schema for ‘package.session_active_mast’ table.”
- Performance Queries
- “Identify the top 10 slowest queries based on average execution time.”
- “List the most frequently slow queries.”
- Index-Related Queries
- “List the table in the product schema that has the most indexes.”
- “List a table in the package schema that has zero indexes.”
- Combined Queries
- “Based on index data, which table in the product schema has the highest index count and what are your recommendations for optimization?”
- “Show me the constraints for ‘package.account’ table.”
Future Integrations and Open-Source LLM Opportunities
While our initial implementation of Agentic AI for YugabyteDB leverages OpenAI’s GPT-3.5-turbo, the landscape of LLMs is evolving rapidly, and there are exciting possibilities for future integrations:
- Hugging Face Transformers
Leverage models such as GPT-Neo or GPT-J from Hugging Face to run LLM inference on-premise. This offers cost benefits, data privacy, and customization by fine-tuning your own YugabyteDB metadata. - LLaMA & GPT4All
Meta’s LLaMA models and community-driven initiatives like GPT4All provide robust, open-source alternatives that can be deployed locally. These options can reduce latency and enhance data security by keeping sensitive metadata on-site. - Custom Fine-Tuning
With open-source LLMs, you can fine-tune the model on historical performance logs, schema documentation, or indexing patterns specific to your YugabyteDB cluster. This ensures the AI agent offers highly tailored recommendations. - Real-Time Monitoring and Alerts
Future integration could include a real-time monitoring system that continuously analyzes performance metrics and automatically alerts DBAs when slow queries or missing indexes are detected.
Key Benefits for YugabyteDB (PostgreSQL 15) Users
- Enhanced Database Visibility
The integration provides immediate, natural language access to rich database metadata, reducing the time needed for manual analysis. - Proactive Performance Tuning
By combining performance metrics (frompg_stat_statementsandpg_stat_activity) with structural metadata, the agent offers targeted recommendations to optimize query performance and indexing. - Scalability and Flexibility
YugabyteDB’s compatibility with PostgreSQL 15 ensures that all advanced features-system catalogs, extensions, and performance views-are available, making the AI agent’s insights directly applicable without additional configuration. - Data Privacy and Cost Efficiency
Open-source LLM options provide the flexibility to run models on-premise, ensuring that sensitive metadata remains within your secure environment while avoiding recurring API costs. - Accelerated Onboarding and Debugging
New team members and DBAs can quickly obtain a comprehensive overview of the database, understand complex schemas, and identify performance bottlenecks through conversational queries.
Conclusion
This new, powerful, agentic AI for YugabyteDB Metadata brings the power of natural language processing to your database management workflow.
With rich metadata extraction that includes columns, indexes, constraints, and performance metrics, and the integration of advanced LLMs, you can ask complex questions like:
- “List the table in the products schema that has more indexes.”
- “Identify the top 10 slowest queries based on average execution time.”
…And you can receive concise, actionable insights in seconds!
The future of database administration is here-intelligent, conversational, and completely agentic.
Embrace this transformative approach and empower your team to interact naturally with your YugabyteDB database and unlock hidden performance optimizations and schema insights quickly and easily.


