Analyze YugabyteDB Change Data Capture Data with Azure Synapse Analytics
May 2, 2023
Yugabyte has collaborated with Microsoft to create a powerful solution to stream YugabyteDB Change Data Capture (CDC) data into an Azure Synapse Analytics workspace. With this robust yet easy-to-deploy solution, organizations can gain valuable insights into their CDC data in near real-time.
Reference Architecture
The diagram below shows how to move YugabyteDB Anywhere CDC data to an Azure Synapse Analytics workspace.
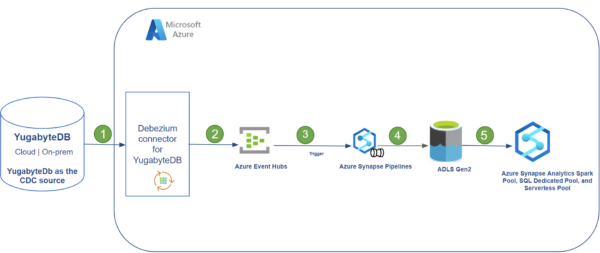
The components used are:
- YugabyteDB Anywhere- Yugabyte’s self-managed DBaaS for deploying YugabyteDB at scale that includes YugabyteDB’s self-managed, stateless CDC functionality with support for Confluent’s Kafka Connect. A pull-based model is used to report changes from the database’s Write-Ahead-Log (WAL). Learn more about the implementation of CDC on the YugabyteDB’s documentation site.
- YugabyteDB Debezium Connector- Pulls data from YugabyteDB, publishes it to Kafka, and runs in a Microsoft Azure Virtual Machine.
- Azure Event Hubs– Azure’s big data streaming platform and event ingestion service.
- Azure Synapse Pipelines
- An ADLS Gen2 Storage account.
- Azure Synapse workspace– Azure’s integrated platform service that merges the capabilities of data lakes, data integrations for ETL/ELT pipelines, analytics tools, and services.
Here’s how the data flows through each of these components.
| Step | Tool or Service | Purpose |
|---|---|---|
| 1 | Debezium YugabyteDB Kafka Connect | Stream the changed data sets requested from the source YugabyteDB Anywhere YSQL tables. |
| 2 | Azure EventHubs | Stream messages from Kafka to different targets. |
| 3 | Azure Synapse Analytics Pipeline | Used to schedule data-driven workflows that can ingest data from Azure Event Hubs to an Azure Data Lake Storage (ADLS) Gen 2 account. |
| 4 | ADLS Gen2 | CDC data from the Azure Event Hub is saved to ADLS Gen2 in Parquet format. |
| 5 | Azure Synapse workspace | Azure SQL Pools and Spark Pools can be used to analyze the CDC data from Yugabyte in near real time. |
Getting Started
Prerequisites. To get started, you’ll need to have:
- a YugabyteDB Anywhere database with CDC enabled
- an Azure Event Hubs instance
- an Azure Synapse Analytics workspace with SQL Pools and Spark Pools. Tables can be created in the SQL Pools to house the CDC data.
- an Azure Data Lake Storage Gen2 account. The Yugabyte CDC data resides in this Storage account and can be queried using external tables in Synapse SQL Pools.
Step 1: Create an Event Hubs namespace and Event Hubs
Azure Event Hubs will be used to capture the CDC data from YugabyteDB. To create Event Hubs namespace and Event Hubs, we have provided a link to the quickstart instructions. Save the Event Hubs connection string and fully qualified domain name (FQDN) for later use. For instructions, see Get an Event Hubs connection string.
Step 2: Create a YugabyteDB CDC Connector
Now that you have created Event Hubs in Azure, you need to create a YugabyteDB CDC Connector that will capture the changes in the Yugabyte database and send them to Event Hubs. Follow these steps to create a YugabyteDB CDC Connector:
- Add data and tables to YugabyteDB. Once this is done, create the CDC Stream ID using the yb-admin command.
- Download Apache Kafka.
- Configure your event hub to connect and receive data from the Debezium Connector for Yugabyte. You can create an Azure Event Hub configuration file that will be saved locally on the machine, for example you can save the config file as “eventhub.config” in the Kafka bin directory. The sample available in the Kafka Connect for Event Hubs documentation will help with this configuration.
- Download the debezium-connector-yugabytedb-1.9.5.y.15.jar file from from Yugabyte’s Github repo. Save this jar file in your Kafka libs folder (e.g. /home/azureuser/kafka_2.12-3.2.0/libs).
- Navigate to the Kafka bin directory(e.g. /home/azureuser/kafka_2.12-3.2.0/bin) on your machine and run the following command ./connect-distributed.sh<Event Hub configuration file> to start YugabyteDB Debezium Kafka Connect.
- Create a Kafka Connector. Run the following commands to do so.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
localhost:8083/connectors/ \
-d '{
"name": "ybconnector",
"config": {
"connector.class": "io.debezium.connector.yugabytedb.YugabyteDBConnector",
"database.hostname":"'$IP'",
"database.port":"5433",
"database.master.addresses": "'$IP':7100",
"database.user": "yugabyte",
"database.password": "yugabyte",
"database.dbname" : "yugabyte",
"database.server.name": "",
"table.include.list":"public.",
"database.streamid":",
"snapshot.mode":"never"
}
}'
Note: Replace the StreamID and database details as needed. Don’t forget to also replace the $IP variable with your YugabyteDB address or DNS Name.
Step 3: Configure the YugabyteDB CDC Connector
Once you have created the YugabyteDB CDC Connector, you must configure it to send CDC data to Azure Event Hubs. To connect the CDC Connector to Event Hubs, edit the config.yaml file in the directory where you created the YugabyteDB CDC Connector, with the following parameters:
- dest_conf: Connection string for the event hub. You can find this connection string in the Azure portal by navigating to Event Hubs and clicking on “Shared access policies”. Then click on “RootManageSharedAccessKey” and copy the “Connection string – primary key”.
- batch_size: Maximum number of events that can be sent in a single batch.
- batch_timeout_ms: Maximum time (in milliseconds) that can elapse before a batch is sent, even if it is not full.
- consumer_threads: Number of threads that the CDC Connector will use to consume events from YugabyteDB. Set this value based on the number of cores on your machine.
- poll_interval_ms: Interval (in milliseconds) at which the CDC Connector will check for new events in the Yugabyte database.
Step 4: Run the YugabyteDB CDC Connector
Start the YugabyteDB CDC Connector, run the following commandsql $ yb-connect-cdc start –cdc_dir <directory> and replace <directory> with the directory you used when creating the YugabyteDB CDC Connector.
The CDC Connector will start capturing changes from the Yugabyte database and sending them to Azure Event Hubs.
Step 5: Pull Events From Azure EventHubs
You have several options to move data from Azure Event Hubs to a Synapse workspace, including a simple option which uses Azure Synapse Pipelines.
An Azure Synapse Pipeline, which subscribes to changes in Event Hubs via a custom trigger, can be used to move CDC data into an ADLS Gen 2 account. One option to accomplish this is to create a Spark Notebook from Azure Synapse Studio which connects to Event Hubs for the specific topic(s) and stores the data in an ADLS Gen2 folder.
Sample code for a PySpark Notebook for an IoT management application, which pulls data from each of the event hubs every five minutes for analysis, is shared below. This Python code will pull the messages from the event hub and persists them in ADLS Gen2.
# Event Hub Connection String with the topic name as db
ehConf = {}
connectionString ="Endpoint=sb://.servicebus.windows.net/;SharedAccessKeyName=xxxxxx;SharedAccessKey=xxxx;EntityPath="
ehConf['eventhubs.connectionString'] = connectionString
# Add consumer group to the ehConf dictionary
ehConf['eventhubs.consumerGroup'] = "$Default"
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql.functions import unbase64,base64
from pyspark.sql.functions import *
from pyspark.sql.types import *
import json
# ADLS Gen2 Folder Name
checkpointpath = '/mnt/delta/source//_checkpoints'
write_path ='/mnt/delta/source/'
# Start from beginning of stream
startOffset = "-1"
# End at the current time. This datetime formatting creates the correct string format from a python datetime object
#endTime = dt.now().strftime("%Y-%m-%dT%H:%M:%S.%fZ")
startingEventPosition = {
"offset": startOffset,
"seqNo": -1, #not in use
"enqueuedTime": None, #not in use
"isInclusive": True
}
conf = {}
conf["eventhubs.connectionString"] = sc._jvm.org.apache.spark.eventhubs.EventHubsUtils.encrypt(connectionString)
conf["eventhubs.consumerGroup"] = "$Default"
conf["eventhubs.startingPosition"] = json.dumps(startingEventPosition)
df = spark \
.readStream \
.format("eventhubs") \
.options(**conf) \
.load()
df = df.withColumn("body", df["body"].cast("string")
df1= df.select(get_json_object(df['body'],"$.payload.before.eventid.value").alias('beforeeventid'), get_json_object(df['body'],"$.payload.after.eventid.value").alias('eventid'),get_json_object(df['body'],"$.payload.after.sensor_uuid.value").alias('sensor_uuid'),get_json_object(df['body'],"$.payload.after.humidity.value").alias('humidity'),get_json_object(df['body'],"$.payload.op").alias('Operation'))
df2=df1.select(eventid','sensor_uuid','humidity','operation', when(df1.Operation =='d',df1.beforeeventid).otherwise(df1.eventid).alias('eventid'))
#Save the data in Delta Format
query = (df2.writeStream.format('delta') \
.option('checkpointLocation',checkpointpath) \
.option("path", write_path) \
.outputMode("append") \
.start()
)
Save and execute this code snippet in the Azure Synapse Analytics Workspace using a Spark Pool with Pyspark as the language after making changes as appropriate. You can analyze the data in the ADLS Gen2 account using Spark pools as described in here, Query captured data in Parquet format with Azure Synapse Analytics Spark Pools
Step 6: View CDC Data in Azure Synapse Dedicated SQL Pools or Spark Pools
You can choose to view the CDC data stored in the ADLS Gen 2 account using either Synapse SQL Dedicated or Serverless Pools. For this, follow the steps in the Synapse SQL documentation for external tables or Query captured data in Parquet format with Azure Synapse Analytics Serverless SQL
And that’s it!
With these six steps, you can connect the YugabyteDB CDC Connector to Azure Event Hubs and ingest data into Azure Synapse Analytics for analysis.
Interested in finding out more? Join our active Slack community of users, experts, and enthusiasts for live and interactive discussions on YugabyteDB and distributed SQL databases.
Learn more About Yugabyte and Microsoft Azure Synapsis:
Yugabyte Joins the Microsoft Intelligent Data Platform Partner Ecosystem


