Background Compactions in YugabyteDB: An Exploration of File-Level Optimization
February 1, 2023
YugabyteDB uses DocDB, a highly-customized document store built on RocksDB, as its internal persistent data storage. RocksDB’s data compaction algorithms come with this data storage. While compactions are mostly kept behind the scenes for invisible bookkeeping, there are scenarios where it is beneficial to understand how they work for the purposes of performance and space optimization.
In this first in a two-part series of posts, we’ll explore the function and implementation of compactions, as well as the behavior and prioritization of background compactions. Our second blog will describe the merits of full compactions, and how they can be scheduled to improve performance in some workloads. So check back for that!
RocksDB provides a variety of compaction tuning options. This post will exclusively focus on the details and configurations that are relevant to YugabyteDB. For more in-depth information about RocksDB compactions, please consult the RocksDB documentation on Github.
What is a Data Compaction?
To understand compactions, we first need to look at how RocksDB stores data on disk. For the purposes of this article, you can think of a RocksDB instance and a YugabyteDB tablet peer to be synonymous. For more details, check out the YugabyteDB persistence documentation.
As key/value pairs are written to the database, the data is first stored in MemTables (i.e. in-memory storage). Periodically, each MemTable is flushed to a disk into a new SST file, where it is persisted. Data is always flushed into a new SST file, meaning that these files will accumulate. In some cases, they accumulate very quickly.
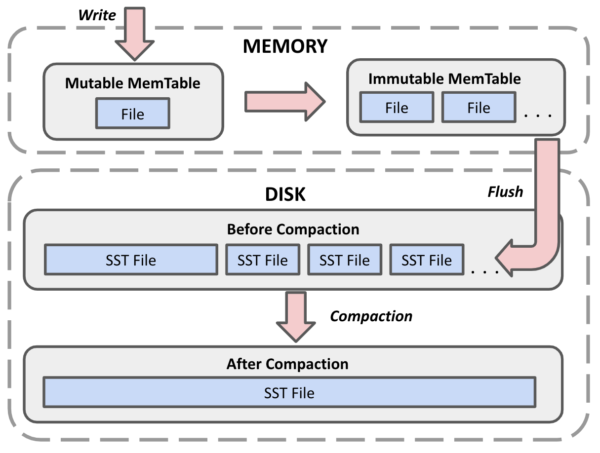
In DocDB, compactions are the process by which a subset of SST files are merged into a single file. To accomplish this, a process iterates over every key/value pair in each original file, and copies each (still relevant) data item into a new, more compact SST. Once the new file is complete, the originals are deleted.
Compactions are important to make reads more performant over time and to minimize space amplification.
Improve Read Performance
Imagine you’re looking up a particular key in the database. It is going to incur an IO cost for every file it needs to read to find the K/V pair. Without periodic compactions to minimize the number of possible files, a single RocksDB instance could very quickly produce hundreds (or even thousands) of SSTs. While bloom filters limit the number of files that need to be accessed to find each key, read latency increases with each file accessed beyond the ideal of “one”. Similarly, if a key has been rewritten with an update or delete, each version that is still stored also adds read latency even though only one version is relevant.
Minimize Space Amplification
During compaction, if a K/V pair is detected as having been deleted or overwritten and is no longer needed for history retention, it will be skipped rather than copied. As a result, once the output file is complete, unnecessary data is purged from the disk when the input files are deleted, serving as a form of garbage collection. This becomes especially relevant for full compactions (which can serve a similar function to vacuuming in PostgreSQL), which are discussed in the next article.
DocDB-Flavored RocksDB Compactions
As mentioned earlier, RocksDB features a variety of compaction types and algorithms. DocDB exclusively uses Level-0 Universal Compactions, chosen to optimize for write performance.
“Level-0” indicates that the compaction file structure is flat. There is only one tier, so new compacted files are treated identically as freshly-flushed files. RocksDB uses the term “sorted run”, which is effectively just a single SST file in DocDB since it uses Level-0. For the purposes of this article, “file” is used rather than “sorted run” in order to simplify the explanation.
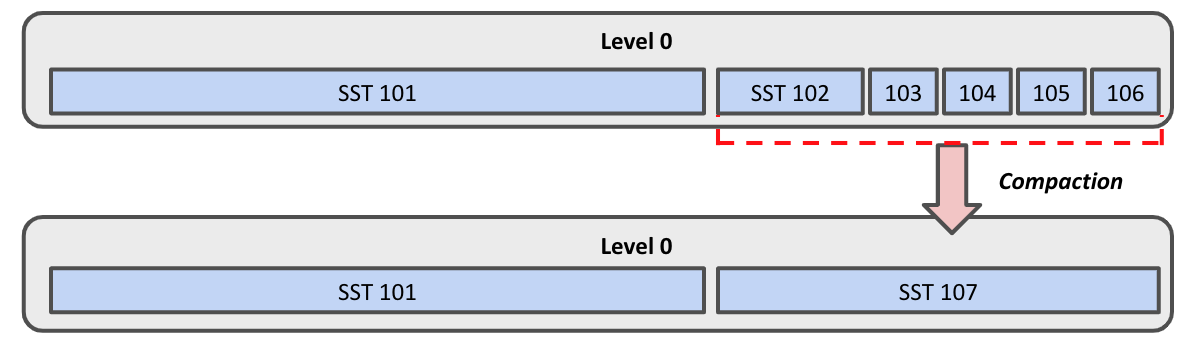
Files involved in a single compaction must be an unbroken chain of files with consecutive time ranges. Files do not overlap in their time ranges, and after compaction, this still holds true.
Background compaction algorithms opt for frequent small compactions rather than fewer large compactions (detailed in the next section). This minimizes the impact of compactions on overall runtime performance.
Taken together over time, the effect of the previous rules is that the data in each tablet peer / RocksDB instance will typically be structured as one large SST file with the earliest-written data, followed by files of decreasing sizes and ages. In the extreme (but optimal) case of a full compaction, all data of a RocksDB instance—at time of compaction—will be stored in a single SST file.
Types of Background Compactions
On active tablets with writes and updates, compactions happen behind the scenes on a regular basis. They tend to be optimized to create many compactions on smaller files to spread resource needs over time. Compaction need is determined according to two algorithms: size amplification and read amplification.
Both algorithms require a minimum number of files to be present in order to trigger the compaction. By default, this number of files is 5, but it can be modified using the rocksdb_level0_file_num_compaction_trigger TServer flag (not recommended in most cases).

For the following examples, we’ll assume a set of files 1 through N, with 1 being the oldest (and largest) and N being the most recent and smallest. Note that the numbering is in the opposite order as the official RocksDB documentation, but is used here to better represent the numbering scheme of actual SST files. In this example, SST 1 is not “the first SST ever written” to this database, but is the oldest file being considered and the result of multiple compactions.
Algorithm #1: Size Amplification
To minimize size amplification of newer files, a compaction of N files will be triggered once the estimated space amplification of the latest N-1 files to the estimated space of the earliest 1 file reaches a certain threshold. From the RocksDB documentation:
size amplification ratio = (size(RN) + size(RN-1) + ... size(R2)) / size(R1)

By default, the threshold ratio is set to 2x (value of 200). For Yugabyte’s purposes in each group of N files, what this means is that once the N-1 newest files reach a combined size of 200% of the oldest file in the group of files, these files will be compacted together.
Algorithm #2: Read Amplification
Compactions based on read amplification are similar to that of size amplification. For a group of N consecutive files, a compaction will take place if the combined sizes of the latest N-1 files are less than or equal to a predefined percentage (size_ratio_trigger) of the size of the earliest included file 1. The algorithm will start at the latest candidate (RLatest) and continue adding N files to the compaction while the following ratio holds true:
read amplification ratio = size(RLatest-N) / (size(RLatest-(N+1)) … size(RLatest-1) + size(RLatest))
The compaction must contain a minimum number of files (default of 4, set via the rocksdb_universal_compaction_min_merge_width TServer flag). The size ratio threshold defaults to 120% (rocksdb_universal_compaction_size_ratio set to 20 by default).
size ratio threshold = (100 + rocksdb_universal_compaction_size_ratio) / 100
IF read amplification ratio <= size ratio threshold AND
number of files (N) >= rocksdb_universal_compaction_min_merge_width
THEN compact
The goal is to compact as many consecutive files as possible with combined size within the given threshold of the final file in the compaction.
YugabyteDB TServer Compaction Resources
Now that we’ve seen how compactions work at the RocksDB level, let’s zoom in and examine what this means for YugabyteDB on a more macro scale. A single TServer in a YugabyteDB cluster will likely contain many tablets, each of which has its own RocksDB instance (or two RocksDB instances in the case of YSQL—one Regular and one Intents). On tablets with active write workloads, background compactions are running very frequently. This means that the same node resources will be in contention across multiple tablets.
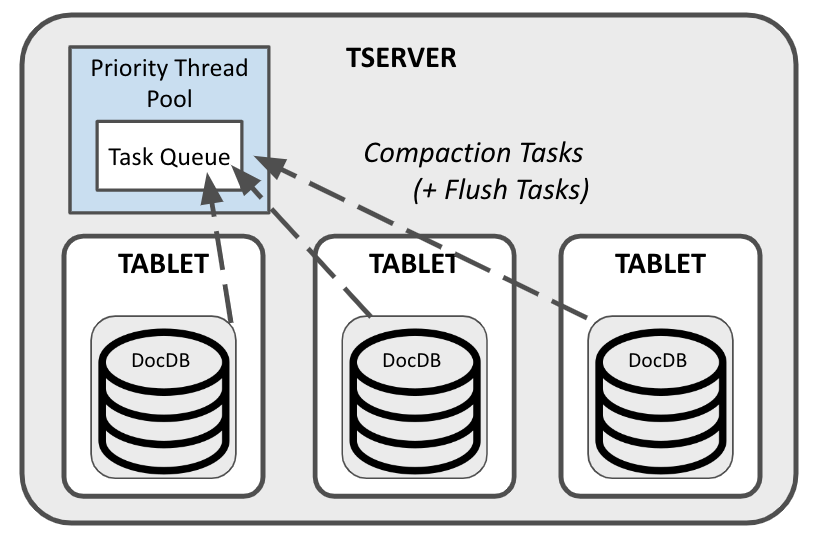
To manage resources across tablets, each TServer uses a single priority thread pool for compactions (and flushes) across all of its tablet peers. By default, the number of threads assigned to this thread pool scales with the number of CPUs available on the node. However, this can be modified using the priority_thread_pool_size TServer flag.
By default, smaller compactions (in terms of total disk size) are prioritized over larger compactions, since falling behind on compactions of small files can result in decreased read performance and can eventually lead to the throttling of writes. Similarly, compactions involving a large number of files tend to be prioritized over those with fewer files.
While background compactions can be tuned via TServer flags, the defaults are strongly recommended. For compaction-related performance tuning, using the scheduled full compactions feature (detailed in the next article) should be considered first.
Some relevant TServer flags for tuning include:
priority_thread_pool_size– The maximum number of simultaneous running compactions allowed per TServer. Default: -1 (i.e. automatically scales per CPU)rocksdb_compact_flush_rate_limit_bytes_per_sec– The write rate limit for flushes and compactions per TServer. Default: 1 GB per secondrocksdb_compaction_size_threshold_bytes– The threshold beyond which a compaction is considered “large” versus “small”. Default: 2 GB.sst_files_soft_limit/sst_files_hard_limit– The soft and hard limits of the number of SSTs allowed per tablet (i.e. an indication that the tablet is behind on compactions). To help compactions catch up, writes will be throttled once the soft limit (24 by default) is reached, and will be stopped entirely once the hard limit (48 by default) is reached.
Full Compactions and the Benefits of Scheduling Them
This concludes the primer on compactions in YugabyteDB and the behavior of background compactions in tablets. In our next blog, we’ll explore full compactions and how they can be tuned to improve cluster performance.


