How to Build Low-Latency Global Applications with Google Apigee and YugabyteDB
August 12, 2024
YugabyteDB is a PostgreSQL-compatible distributed database, designed to deliver scale, availability, and enterprise-grade RDBMS capabilities for mission-critical transactional applications. It delivers a powerful cloud-native database that thrives in any cloud environment.
Apigee is Google Cloud’s API management platform, and enables the building, managing, and securing of APIs for any use case or environment. It delivers high-performance API proxies, ensuring a reliable interface for backend services with control over security, rate limiting, quotas, and analytics. Apigee supports REST, gRPC, SOAP, and GraphQL, offering versatile API architecture implementation.
The Benefits of Using Google Apigee with YugabyteDB
So, how do a distributed PostgreSQL database and an API management platform go together?
Developers have grown accustomed to load balancing user traffic across multiple application servers. Now, imagine you can deploy your entire application stack across cloud regions, while maintaining a baseline level of performance, availability, and compliance with data regulatory requirements.
Global applications using Apigee and YugabyteDB have several advantages:
- User requests are served with low latency from nearly anywhere in the world by proxying them through Apigee to backend services running in the same region, then executing them using locally accessed data.
- Many outages are tolerated better, including zone and region-level incidents. In the event of a cloud outage impacting the availability of Apigee, YugabyteDB, and application instances in the region, the remaining Apigee / YugabyteDB / application instances will continue serving user requests from other cloud regions. This eliminates business disruption.
- User data is pinned to required data centers, and Apigee will serve data from those locations to best comply with data regulator requirements.
Ideal Industries and Use Cases
A range of industries and use cases run global applications using Google Apigee and YugabyteDB. These include:
- Financial Services & Fintech: Enhance real-time payments processing, fraud detection, and customer analytics across global markets. By leveraging distributed databases and a high-performance API management platform, financial institutions can offer secure, seamless services while ensuring compliance and performance.
- Retail & eCommerce: Manage inventory, process transactions, and personalize customer experiences in real time, across global eCommerce and marketplace platforms. Retailers can scale operations during peak shopping seasons and scale back down without compromising speed or reliability.
- Gaming & Entertainment: Improve mobile game backends with a secure and scalable way to access user data, inventory, and achievements. Enhance collecting and exposing gaming and entertainment data for analytical purposes and customer-facing services that need fast, low latency data access. Simplified API management and geo-distributed, low-latency data access ensure an optimal customer experience.
These applications (and more) benefit from the hybrid cloud capabilities of YugabyteDB and Apigee by allowing for flexible deployments across cloud environments and on-premises data centers. By modernizing applications with these technologies, businesses can cater to global users’ needs, achieving unprecedented scalability, resilience, and agility.
Next we will explore how Apigee (and other Google Cloud services) can be used with YugabyteDB to build a global, low-latency movie recommendation service that is distributed across multiple cloud regions.
Introducing YugaMovies
Our example is a sample movie recommendation service, YugaMovies, targeting a global audience and built on several Google Cloud services, including Apigee, Artifact Registry, Kubernetes Engine, Vertex AI, Cloud Load Balancing, Cloud Storage Buckets and Virtual Private Cloud.
This application uses a multi-region YugabyteDB database cluster to achieve low latency reads and writes (across user locations) and to ensure resilience against zone and region level outages.
Backed by Vertex AI and the pgvector PostgreSQL extension, YugaMovies offers movie recommendations by performing a similarity search against the database.
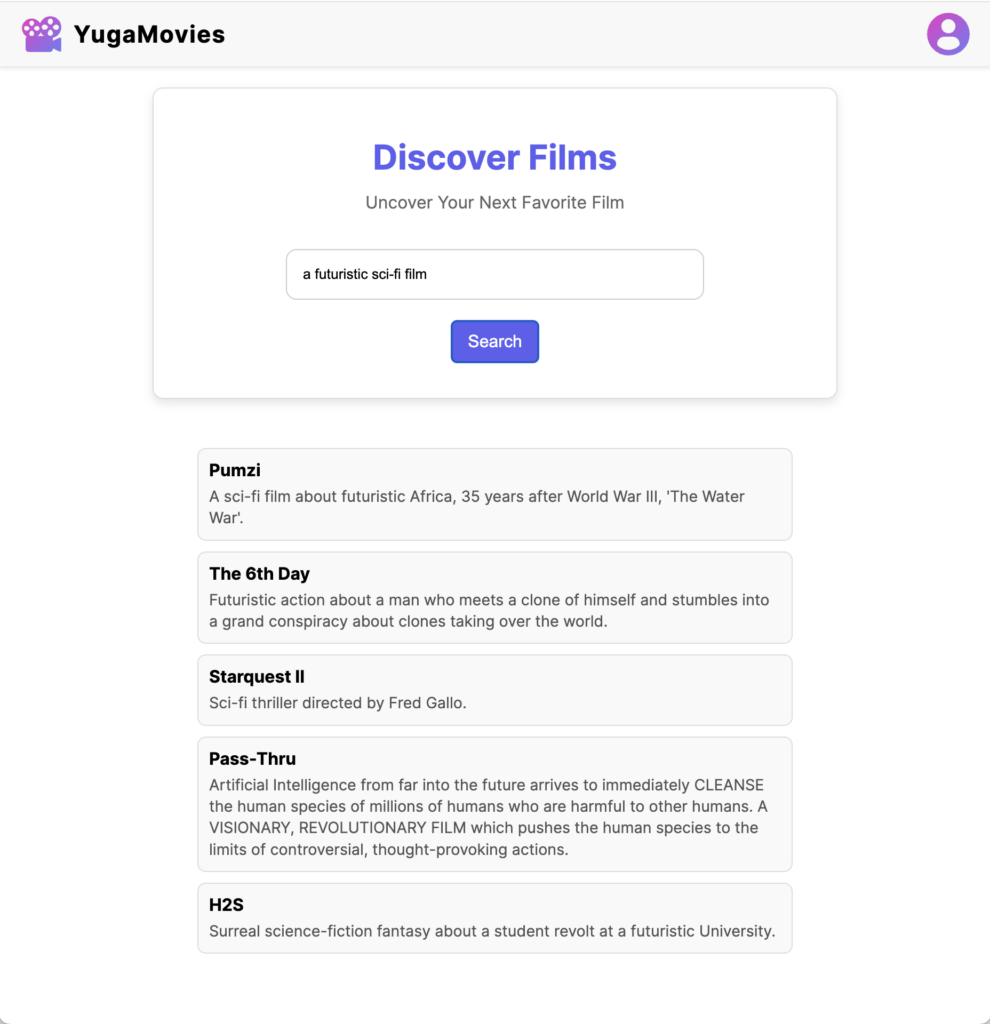
Vertex AI generates text embeddings for each movie’s title and description, stored in YugabyteDB for querying. When a search is executed, Vertex AI generates embeddings from user prompts, which are then compared to movie embeddings in the database using the pgvector extension for accurate matching.
Diving into the Application Architecture
Our movie recommendations service can function within a single cloud region or across several locations. We’ll explore a configuration that covers the US West, Central, and East regions.
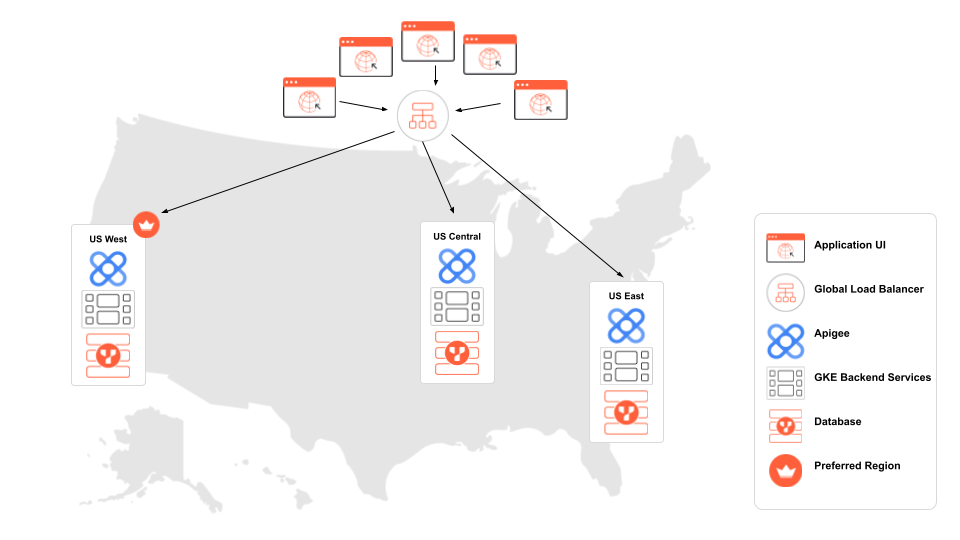
The primary components (see illustration above) are:
- Application UI: React.js UI receiving and initiating requests from end users.
- Global Load Balancer: Routes traffic from the React UI to the nearest Apigee instance.
- Apigee: Proxies traffic to backend services running in the same cloud region.
- GKE Backend Services: Node.js backend services running in Google Kubernetes Engine (GKE).
- Database: A multi-region YugabyteDB cluster is deployed to provide high availability and low latency.
- Preferred Region: The YugabyteDB region where tablet leaders (primary copies of the data) will reside.
Let’s see how this deployment processes user requests.
The movie recommendation service’s React UI sends API requests through a global load balancer, which are then routed to the nearest Apigee instance. Apigee serves as a reverse proxy to a GKE cluster in the same region. This provides the application with all the benefits of an API management service, including security and rate limiting, without exposing backend services directly to the user interface.
Once proxied through Apigee, user requests arrive to GKE, which hosts the application backend.
There are two backend services: one for user authentication and the other for movie recommendation requests. These services are exposed by GKE’s internal load balancer service, which allows Apigee to route requests to them on IP addresses internal to the VPC.
This is made possible using Private Service Connect, which allows traffic to be sent between networks without being exposed to the public internet.
The backend then executes these user requests on the database. VPC Network Peering allows the application’s VPC to connect to the database cluster’s VPC.
NOTE: With a multi-region database deployment in YugabyteDB, backend services can connect directly to nodes deployed in the same region to reduce latency.
Next, let’s look at how requests are handled by Apigee, and at the database level, to achieve low latency reads and writes.
Using Apigee Across Regions
Google Apigee can be used as a centralized API management platform for protecting, monitoring, and configuring API services. By deploying Apigee instances in the same cloud regions as backend services, the UI can route user traffic to the nearest Apigee instance without significant latency costs.
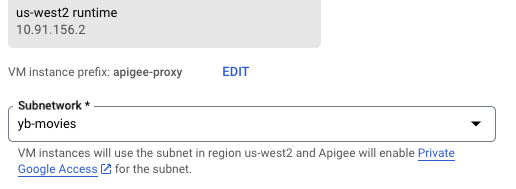
Apigee configures a private connection to the application VPC, allowing proxies to be created within the Google Cloud network.
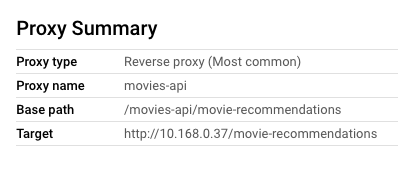
Once this proxy is deployed to Apigee, requests to APIGEE_URL/movies-api/movie-recommendations are proxied to the movies backend service in the same region, running in GKE, at http://10.168.0.37/movie-recommendations.
By connecting to a publicly-configured Apigee domain, we can abstract our backend services from the application.
Now, let’s explore how connecting these backend services to a multi-region database cluster can further improve application latency.
Deploying a Distributed PostgreSQL Database
Deploying a database cluster across multiple cloud regions in GCP is simple with a fully managed deployment of YugabyteDB.
YugabyteDB provides several design patterns for multi-region deployments. Many developers choose YugabyteDB to build applications that are tolerant to node, zone, or region outages, to achieve low latency regardless of the user location, and to comply with data regulations.
YugabyteDB shards data across all nodes and then distributes the load by having all the nodes process read and write requests. Transactional consistency is achieved using the Raft consensus protocol, which replicates changes synchronously among the cluster nodes.
To enhance performance, we utilized two design patterns for low latency across regions in our sample movie recommendations service.
- Global database with follower reads is employed to achieve low-latency reads from tablet followers in non-preferred regions on the movies table.
- Latency-optimized geo-partitioning pins data to a specific geographic region, reducing optimizing latency for both reads and writes on the users table.
Global Database with Follower Reads
End users expect fast reads on the entire movie dataset from all regions. By using a global database with follower reads, application instances can connect to database nodes in the same region to deliver low latency reads.
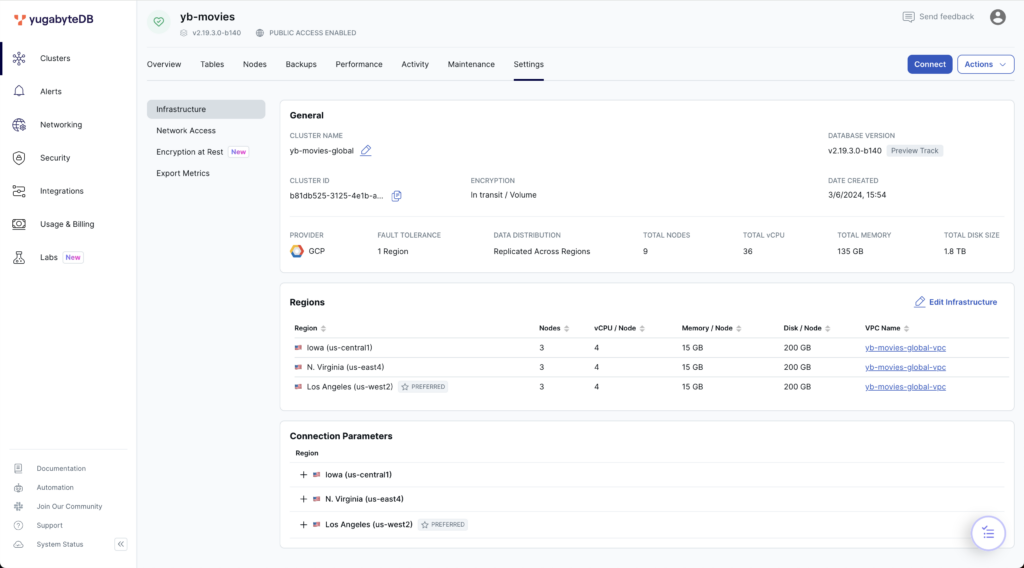
To distribute data across regions, we’ve deployed a globally-replicated YugabyteDB Managed cluster on GCP, selecting us-west2 as the preferred region.
After populating the movies table with the movies data set and associated text embeddings, we’re ready to begin testing the latency.
We begin testing by connecting to the database in the designated preferred region, us-west2, through the local Apigee endpoint and asking for movie recommendations:
GET US_WEST2_APIGEE_URL/movies_api/movie-recommendations
QUERY PARAMS
searchText=A classic adventure film
film genre=Adventure
voteAverage=7
RESPONSE
{
"data": [
{
"original_title": "Thief of Damascus",
"overview": "A young man assembles a band of adventurers to take on an evil sultan."
},
{
"original_title": "The Way",
"overview": "When his son dies while hiking the famed Camino de Santiago pilgrimage route in the Pyrenees, Tom flies to France to claim the remains. Looking for insights into his estranged child's life, he decides to complete the 500-mile mountain trek to Spain. Tom soon joins up with other travelers and realizes they're all searching for something."
},
{
"original_title": "Dances with Wolves",
"overview": "Wounded Civil War soldier, John Dunbar tries to commit suicide - and becomes a hero instead. As a reward, he's assigned to his dream post, a remote junction on the Western frontier, and soon makes unlikely friends with the local Sioux tribe."
},
{
"original_title": "Rogue One: A Star Wars Story",
"overview": "A rogue band of resistance fighters unite for a mission to steal the Death Star plans and bring a new hope to the galaxy."
},
{
"original_title": "Indiana Jones and the Temple of Doom",
"overview": "After arriving in India, Indiana Jones is asked by a desperate village to find a mystical stone. He agrees - and stumbles upon a secret cult plotting a terrible plan in the catacombs of an ancient palace."
}
],
"latency": 11,
}
The baseline latency for this deployment is 11 milliseconds since all tablet leaders will be stored in the preferred region. To test cross-regional latency, let’s connect to database nodes in us-east4 and us-central1 through backend services running in those same regions:
GET US_EAST4_BACKEND_SERVICE_URL/movie-recommendations
QUERY PARAMS
searchText=A classic adventure film
film genre=Adventure
voteAverage=7
RESPONSE
{
"data": [
...
],
"latency": 112,
}
GET US_CENTRAL1_BACKEND_SERVICE_URL/movie-recommendations
QUERY PARAMS
searchText=A classic adventure film
film genre=Adventure
voteAverage=7
RESPONSE
{
"data": [
...
],
"latency": 137,
}The latencies of 112 ms and 137 ms, while not excessively high, can be significantly improved by enabling follower reads. This is straightforward, achieved by setting the session properties on our database connections within the movies backend service.
pool.on("connect", async (c) => {
await c.query("set yb_read_from_followers = true;");
await c.query("set session characteristics as transaction read only;");
});Now, by executing the same API calls, our database nodes will read from tablet followers in their respective regions, eliminating the need to read from tablet leaders across regions.
GET US_EAST4_BACKEND_SERVICE_URL/movie-recommendations
QUERY PARAMS
searchText=A classic adventure film
film genre=Adventure
voteAverage=7
RESPONSE
{
"data": [
...
],
"latency": 11,
}
GET US_CENTRAL1_BACKEND_SERVICE_URL/movie-recommendations
QUERY PARAMS
searchText=A classic adventure film
film genre=Adventure
voteAverage=7
RESPONSE
{
"data": [
...
],
"latency": 11,
}Enabling follower reads allows us to attain low-latency reads in each region by connecting directly to closest database nodes. While reading from followers can introduce data lag, the entire data set on the followers always remains in a consistent state.
YugabyteDB ensures data consistency through its transactional sub-system and the Raft consensus protocol, which replicates changes synchronously across the entire multi-region cluster. As the movies table is updated infrequently, data lag is no issue for this application use case.
| US West App Instance | US Central App Instance | US East App Instance | |
| Global Database Reads From the Preferred Region | 11 ms | 112 ms | 137 ms |
| Follower Reads | N/A | 11 ms | 11 ms |
Latency-Optimized Geo-Partitioning
Geo-partitioning is a popular design pattern for applications facing data regulatory requirements like GDPR in the EU or DPDPA in India, as well as for those seeking low latency reads and writes. By pinning data to specific regional tablespaces, applications can connect directly to the closest nodes, significantly reducing latency.
To use a geo-partitioned table in YugabyteDB, begin by creating regional tablespaces:
CREATE TABLE IF NOT EXISTS
users (
id SERIAL,
first_name VARCHAR(50),
last_name VARCHAR(50),
username VARCHAR(255),
password VARCHAR(255) NOT NULL,
geo VARCHAR(10)
)
PARTITION BY
LIST (geo);
-- West partition table
CREATE TABLE IF NOT EXISTS
us_west PARTITION OF users (id, geo, PRIMARY KEY (id HASH, geo)) FOR
VALUES
IN ('west') TABLESPACE us_west2_ts;
-- Central partition table
CREATE TABLE IF NOT EXISTS
us_central PARTITION OF users (id, geo, PRIMARY KEY (id HASH, geo)) FOR
VALUES
IN ('central') TABLESPACE us_central1_ts;
-- East partition table
CREATE TABLE IF NOT EXISTS
us_east PARTITION OF users (id, geo, PRIMARY KEY (id HASH, geo)) FOR
VALUES
IN ('east') TABLESPACE us_east4_ts;With tablespaces created, we can create users and pin their data to a particular region with low latency within each region:
POST US_WEST2_APIGEE_URL/auth_api/users
BODY {"firstName": "jane", "lastName": "doe", "username": "janedoe", "password": "abc123", "geo": "west"}
RESPONSE
{
"status": "Created user successfully.",
"latency": 6
}
POST US_CENTRAL1_BACKEND_SERVICE_URL/auth_api/users
BODY {"firstName": "tim", "lastName": "thompson", "username": "timthompson", "password": "abc123", "geo": "central"}
RESPONSE
{
"status": "Created user successfully.",
"latency": 5
}
POST US_EAST4_BACKEND_SERVICE_URL/auth_api/users
BODY {"firstName": "bob", "lastName": "roberts", "username": "bobroberts", "password": "abc123", "geo": "east"}
RESPONSE
{
"status": "Created user successfully.",
"latency": 5
}After inserting a few users, we can use the ysqlsh CLI to verify that we have one user in each region:
yugabyte=> select * from users; id | first_name | last_name | username | password | geo 1 | jane | doe | janedoe | HASHED_PW | west 2 | tim | thompson | timthompson | HASHED_PW | central 3 | bob | roberts | bobroberts | HASHED_PW | east
Let’s now execute a REST call to the Apigee /login endpoint from the US West to measure read latency:
POST US_WEST2_APIGEE_URL/auth_api/login
BODY {"username": "janedoe", "password": "abc123"}
{
"token": "eyJhbGc...",
"latency": 2
}The authentication service can retrieve the user in just 2 milliseconds by querying for users within the same region as the deployed backend service. The same latency is achieved within the US Central and US East regions when you authenticate users in those respective regions:
POST US_CENTRAL1_BACKEND_SERVICE_URL/auth_api/login
BODY {"username": "timthompson", "password": "abc123"}
{
"token": "eyJdqRbc...",
"latency": 2
}
POST US_EAST4_BACKEND_SERVICE_URL/auth_api/login
BODY {"username": "bobroberts", "password": "abc123"}
{
"token": "eyJLmrQ...",
"latency": 2
}Now, suppose the user from US West travels to the US East and needs to authenticate with the movie recommendations service:
POST US_EAST4_BACKEND_SERVICE_URL/auth_api/login
BODY {"username": "testuser2", "password": "password123"}
{
"token": "eyJhbGc...",
"latency": 91
}In this scenario, an increase in latency is expected when user data is accessed from a distant region.
So, now let’s see what happens if this user decides to update their password from the US East region:
PUT US_EAST4_BACKEND_SERVICE_URL/auth_api/users
BODY {"username": "janedoe", "password": "newpass123"}
RESPONSE
{
"status": "Updated user successfully.",
"latency": 72
}Again, the increase in latency is predictable since the record is written to a node residing ~65 ms from the application server.
| US West App Instance | US Central App Instance | US East App Instance | |
| Geo-partitioning reads within region | 2 ms | 2 ms | 2 ms |
| Geo-partitioning writes within region | 6 ms | 6 ms | 5 ms |
| Geo-partitioning reads across regions | 113 ms | 74 ms | 91 ms |
| Geo-partitioning writes across regions* | 72 ms | 48 ms | 71 ms |
* Maximum reported latency based on cluster regions
Summary
This blog shows how simple it is to deploy a high-performance multi-region application on Google Cloud! By leveraging Apigee to proxy requests to local backend services, and using YugabyteDB for data distribution, we’ve demonstrated how you can deliver a low-latency experience across multiple cloud regions.
Next Steps:
- Discover more about YugabyteDB
- Manage APIs with Apigee


