Building an Autonomous AI Agent with LangChain and PostgreSQL pgvector
May 27, 2024
In this blog, we’ll create a fully autonomous AI travel agent, capable of finding listings and managing bookings. This OpenAI tools agent uses LangChain, OpenAI, PostgreSQL and pgvector, with YugabyteDB as the underlying database.
Why You Should Use an AI Agent
AI agents have knowledge of the environment in which they operate, which allows them to perform specific tasks to achieve their goals. By providing an agent with custom tools, we can build a system that is robust within a particular domain.
Large language models (LLMs) are able to provide text outputs from a message prompt, by predicting the next word or sentence based on those preceding. However, an LLM’s knowledge base is limited to what it was trained on. An LLM cannot inherently answer prompts that require up-to-date or proprietary information. However, by providing an LLM with tools that can interface with active data sources, through the use of an AI agent, new goals can be achieved.
Building Blocks
Before diving into the code, let’s first outline the role that each component plays in creating an effective agent.
LangChain: A framework for constructing AI applications, with the ability to create sequential chains of actions, or in the case of agents, autonomous actions with ordering based on logical reasoning. LangChain provides multiple agent types based on application needs.
OpenAI: The LLM of choice, with many models to choose from based on the application’s needs. These models can be used to generate responses to prompts, and also to create text embeddings to perform queries, such as similarity search.
PostgreSQL: The general-purpose relational database for a wide array of applications, equipped with extensions for storing and querying vector embeddings in AI applications.
pgvector: A PostgreSQL extension for handling vector similarity search.
Tools: Interfaces that the agent can use to perform specific tasks. For instance, a weather tool could provide the agent with the ability to fetch the current weather forecast.
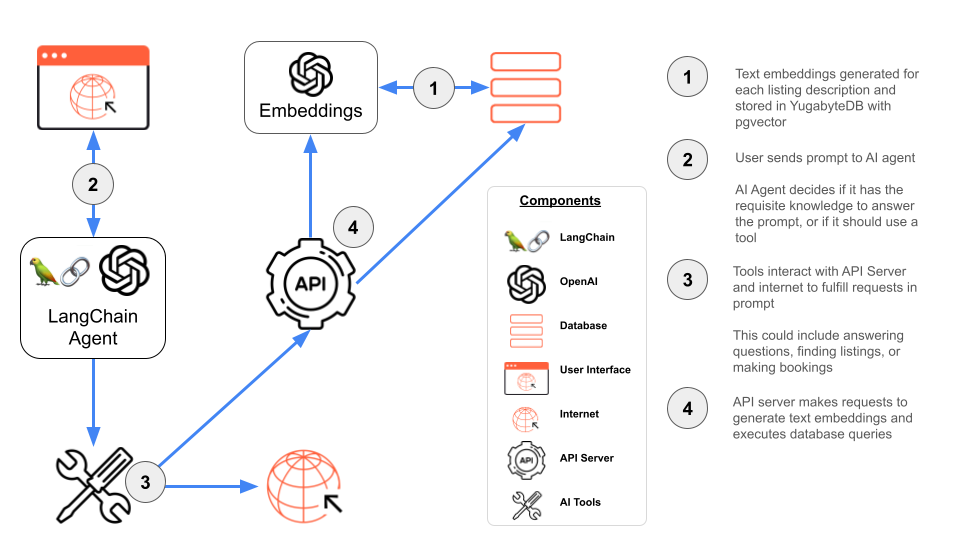
Now that we’ve covered the foundational components, let’s begin building our autonomous agent.
Creating an AI Agent with Internet Search Functionality
We begin by walking through the steps required to create our first AI agent in LangChain. Many LLMs are supported, such as those by Google, Anthropic, and Mistral, but we’ll default to using OpenAI in this example.
- Install dependencies.
pip install -qU langchain-openai
- Create an OpenAI API Key and store it as an environment variable.
OPENAI_API_KEY=sk-...
- Select an OpenAI model to use with the ChatOpenAI interface. This interface provides user-friendly methods for building chatbot related applications.
from langchain_openai import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
- Create a tool for searching the web from the agent. Tavily is a search engine optimized for use in AI applications.
from langchain_community.tools.tavily_search import TavilySearchResults tools = [TavilySearchResults(max_results=1)]
- Create and run the agent.
from langchain.agents import AgentExecutor, create_tool_calling_agent from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Make sure to use the tavily_search_results_json tool for information.", ), ("placeholder", "{chat_history}"), ("human", "{input}"), ("placeholder", "{agent_scratchpad}"), ] ) # Construct the Tools agent agent = create_tool_calling_agent(llm, tools, prompt) # Create an agent executor by passing in the agent and tools agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "What is the weather in San Francisco?"}) # Output > Entering new AgentExecutor chain... Invoking: `tavily_search_results_json` with `{'query': 'weather in San Francisco'}` [{'url': 'https://www.weatherapi.com/', 'content': "{'location': {'name': 'San Francisco', 'region': 'California', 'country': 'United States of America', 'lat': 37.78, 'lon': -122.42, 'tz_id': 'America/Los_Angeles', 'localtime_epoch': 1713832009, 'localtime': '2024-04-22 17:26'}, 'current': {'last_updated_epoch': 1713831300, 'last_updated': '2024-04-22 17:15', 'temp_c': 17.8, 'temp_f': 64.0, 'is_day': 1, 'condition': {'text': 'Partly cloudy', 'icon': '//cdn.weatherapi.com/weather/64x64/day/116.png', 'code': 1003}, 'wind_mph': 12.5, 'wind_kph': 20.2, 'wind_degree': 320, 'wind_dir': 'NW', 'pressure_mb': 1010.0, 'pressure_in': 29.81, 'precip_mm': 0.0, 'precip_in': 0.0, 'humidity': 70, 'cloud': 25, 'feelslike_c': 17.8, 'feelslike_f': 64.0, 'vis_km': 16.0, 'vis_miles': 9.0, 'uv': 5.0, 'gust_mph': 17.8, 'gust_kph': 28.7}}"}]The current weather in San Francisco is partly cloudy with a temperature of 64.0°F (17.8°C). The wind speed is 20.2 km/h coming from the northwest direction. The humidity is at 70%, and the visibility is 9.0 miles. > Finished chain.
With the addition of the TavilySearchResults tool, the AI agent is able to access the internet to retrieve up-to-date information, rather than simply relying on the knowledge base on which the LLM was trained.
This simple example displays the power of enhancing core LLM chat functionality with additional tools. Now, let’s examine how we can set up a PostgreSQL database to further enhance our AI agent’s functionality for use in a sample travel booking application.
Vector Embeddings in PostgreSQL
LangChain can be used to query SQL databases directly, by gaining knowledge of the database schema and executing the appropriate queries to respond to a particular prompt. However, this functionality can be extended with the use of pgvector and vector embeddings in PostgreSQL.
For instance, when building a travel booking application, the listing_description_embeddings column of the listings table could hold a vector representation of the listing description. This column could then be used for similarity search.
Here’s how the pgvector extension can be used in PostgreSQL.
- Install the extension.
CREATE EXTENSION IF NOT EXISTS vector;
- Include a column of type vector in the database schema. The number of dimensions varies based on the model. OpenAI’s text-embedding-3-small model contains 1536 dimensions.
CREATE TABLE listings ( id SERIAL PRIMARY KEY, listing_name varchar(255), listing_description text, price DECIMAL(10,2), neighborhood varchar(255), listing_description_embeddings vector (1536), );
- Generate text embeddings for each listing description.
from langchain_openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings(model="text-embedding-3-small") cursor.execute("SELECT listing_description from listings") listings = cursor.fetchall() for listing in listings: listing_description = listing[0] # OpenAI's model will return a vector array with 1536 dimensions to be added to the database as embeddings text_embeddings = embeddings.embed_query(listing_description) - Add records to the database.
query = "INSERT INTO listings(listing_name, listing_description, price, neighborhood, listing_description_embeddings) VALUES (%s, %s, %s, %s, %s)" cursor.execute(query, (listing_name, listing_description, price, neighborhood, text_embeddings, )) db_connection.commit()
- Test the database using similarity search. In this example, we order results using the cosine distance between vectors (text embeddings).
SELECT * FROM listings ORDER BY listing_description_embeddings <=> '[3,1,2,...]' LIMIT 5;
After generating embeddings and storing the appropriate data, we’re ready to create a tool to query our PostgreSQL database.
Adding Tools for Database Interaction
There are many ways to connect to a SQL database from LangChain. For direct access, users can access the LangChain SQL database toolkit, which provides functionality to ingest the database schema, query the database, and recover from any potential errors. However, this toolkit is in active development and does come with some issues. For instance, do we really want to give a SQL agent direct access to create and delete records in our database?
An alternative approach is to create custom tools for database interaction. These tools will handle specific tasks and can even make calls to external services to further abstract the agent from our data, while providing the same end-user experience.
Querying the Database with an AI Agent
Here’s an example of how we can augment our existing agent to interact with the listings table.
- Create a REST server with endpoints for querying the database.
from dotenv import load_dotenv from flask import Flask, request, jsonify import psycopg2 from psycopg2.extras import RealDictCursor import json import os # Load environment variables from .env file load_dotenv() def get_env_vars(*args): return [os.getenv(arg) for arg in args] DB_HOST, DB_NAME, DB_USERNAME, DB_PASSWORD, DB_PORT = get_env_vars('DB_HOST', 'DB_NAME', 'DB_USERNAME', 'DB_PASSWORD', 'DB_PORT') conn = psycopg2.connect( dbname=DB_NAME, user=DB_USERNAME, password=DB_PASSWORD, host=DB_HOST, port=DB_PORT ) from langchain_openai import ChatOpenAI, OpenAIEmbeddings embeddings = OpenAIEmbeddings(model="text-embedding-3-small") def get_embedding(embedding_text: str): response = embeddings.embed_query(embedding_text) return response app = Flask(__name__) def create_listings_select_query(filters, embedding): query_base = "SELECT listing_name, listing_description,price,neighborhood FROM airbnb_listings" # [ LOGIC TO CONSTRUCT FULL QUERY FROM FILTERS AND TEXT EMBEDDINGS... ] return {"query": query, "params": params} @app.route('/api/listings', methods=['POST']) def get_listings(): data = request.get_json() cur = conn.cursor(cursor_factory=RealDictCursor) embedding = None if 'embedding_text' in data: embedding = get_embedding(data["embedding_text"]) query_and_params = create_listings_select_query(data.get("query_params", {}), embedding) cur.execute(query_and_params["query"], query_and_params["params"]) rows = cur.fetchall() rows_json = json.dumps(rows, default=str) cur.close() return jsonify({"data": rows_json}) if __name__ == '__main__': app.run(port=8000, debug=True)Note: If embedding_text is sent in the request payload, the get_embedding function will be called to generate embeddings from OpenAI. These embeddings will then be used in a similarity search with pgvector.
- Create a new tool which calls this API service.
from langchain.tools import StructuredTool class GetListingsInput(BaseModel): data: object = Field(description="has two keys, 'query_params' and 'embedding_text'") def get_listings(data): """this function makes an API call to a REST server to search listings. """ # The URL for the API endpoint url = 'http://localhost:8000/api/listings' # Making a POST request to the Flask API response = requests.post(url, json=data) if response.status_code == 200: data = response.json() return data else: print("Failed to retrieve data from API") get_listings_tool = StructuredTool.from_function( func=get_listings, name="GetListings", description="retrieves listings from an API call", args_schema=GetListingsInput ) tools = [ TavilySearchResults(max_results=1), get_listings_tool ] - Update the system message with more detailed instructions to include in the chat prompt.
formatted_system_message = """You are a friendly travel agent. You are helping customers book travel accomodations. Below is the database schema: CREATE TABLE listings ( id SERIAL PRIMARY KEY, listing_name varchar(255), listing_description text, bedrooms NUMERIC(3,1), price NUMERIC(10,2), neighborhood varchar(255), listing_description_embeddings vector (1536), ); If a user asks to find listings on their behalf, use the get_listings_tool and respond accordingly. Return results in JSON format with 'summary' and 'results_to_display' keys. """ prompt = ChatPromptTemplate.from_messages([ SystemMessage(formatted_system_message), MessagesPlaceholder(variable_name="chat_history", optional=True), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad") ]) - Execute the agent to verify the database is being queried from the API server to respond appropriately.
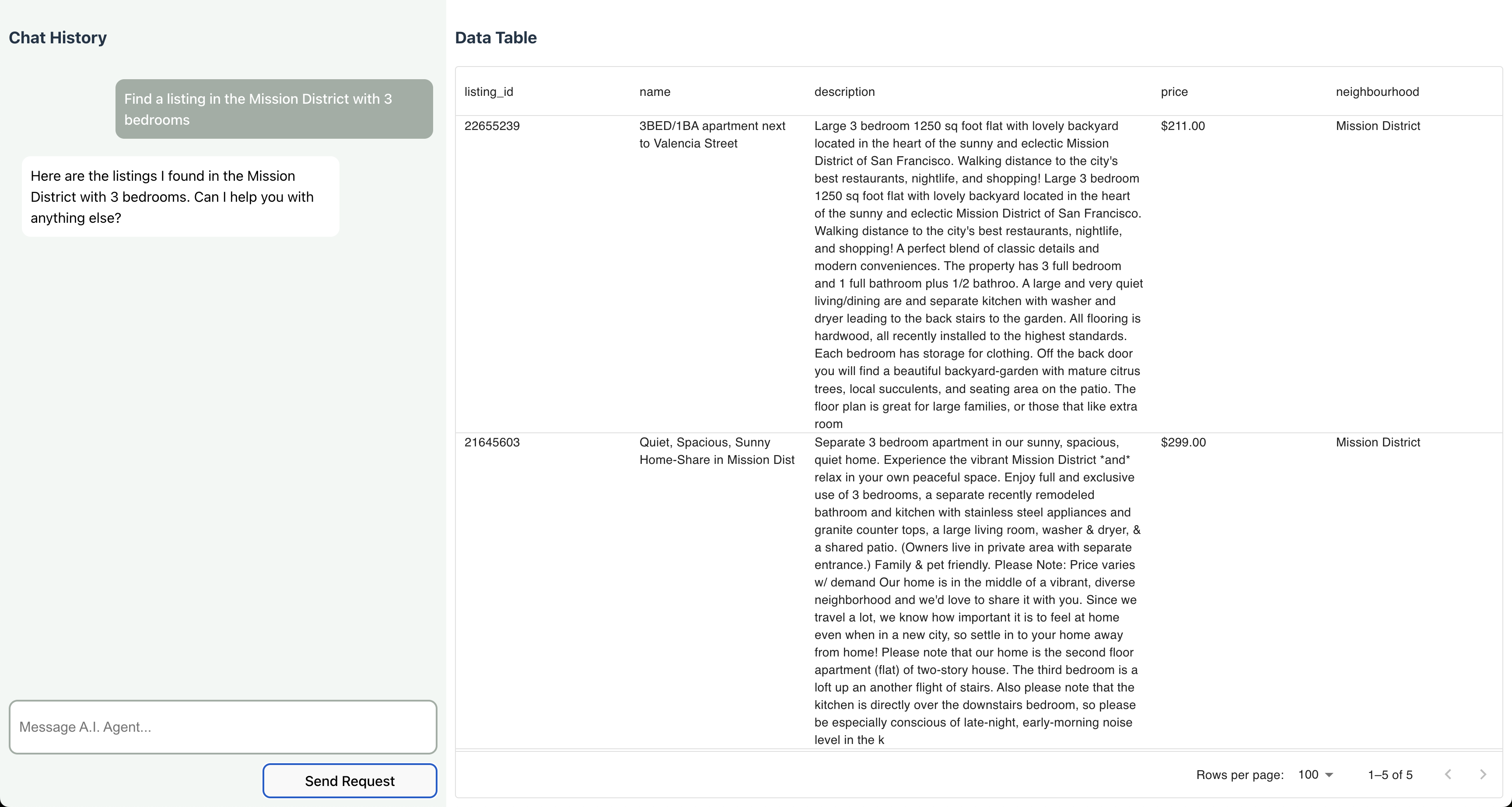
Here, we can see that the agent invokes the GetListings tool, which responds with relevant listings based on the user prompt.agent_executor.invoke({"input": "Find listings in The Mission District with enough space for a large family."}) > Entering new AgentExecutor chain... Invoking: `GetListings` with `{'data': {'query_params': {'neighbourhood': {'value': 'Mission', 'type': 'text'}, 'bedrooms': {'value': 3, 'type': 'number', 'symbol': '>='}}, 'embedding_text': 'spacious place for a family getaway.'}}` {'data': '[{"listing_id": 26638684, "name": "Big Bright House Sleeps 9 W/D BBQ Parking", "description": "Cheerful and warm, this spacious two-story house features large common areas with loads of space and privacy, and is ideal for groups and families. Sleeps nine people with lots of elbow-room indoors and out. Enjoy a BBQ and a ping-pong game or two in the large, private back yard. Easy street parking with one spot in front guaranteed. Lovely, quiet neighborhood. Nearby parks, dining, retail and public transit. Welcome home to generous rooms filled with light and a formal floor plan which allows for privacy. Features include a living room with fireplace, piano and cityscape views; fully equipped chef\'\'s style kitchen that opens to dining room with seating for ten; three full bathrooms with tubs and showers; and private backyard with BBQ grill, plenty of seating, and ping pong table. Sofabed available to allow to sleep nine people total. The Main level includes bedroom with three twin beds and adjacent full bath, plus the master suite with a king-sized bed and full bath. The Lower level f", "price": "$250.00 ", "neighbourhood": "Mission Terrace"}, {"listing_id": 19872447, "name": "New building luxury 3BR/2BTH-near Mission St", "description": "My place is good for couples, solo adventurers, business travelers, families(with kids), and big groups. The building was construted in 2008, updated electrical and plumbing, fresh paint. lights fill in every rooms. you will have the 2nd floor for your own privacy.", "price": "$275.00 ", "neighbourhood": "Mission Terrace"}, ...]', 'status': 'this is the response from the get listings endpoint'} {"summary": "Here are the results I found. Can I help you with anything else?", "results_to_display": [{"listing_id": 26638684, "name": "Big Bright House Sleeps 9 ‚≠ê∂∏é W/D ‚≠ê∂∏é BBQ ‚≠ê∂∏é Parking", "description": "Cheerful and warm, this spacious two-story house features large common areas with loads of space and privacy, and is ideal for groups and families. Sleeps nine people with lots of elbow-room indoors and out. Enjoy a BBQ and a ping-pong game or two in the large, private back yard. Easy street parking with one spot in front guaranteed. Lovely, quiet neighborhood. Nearby parks, dining, retail and public transit. Welcome home to generous rooms filled with light and a formal floor plan which allows for privacy. Features include a living room with fireplace, piano and cityscape views; fully equipped chef's style kitchen that opens to dining room with seating for ten; three full bathrooms with tubs and showers; and private backyard with BBQ grill, plenty of seating, and ping pong table. Sofabed available to allow to sleep nine people total. The Main level includes bedroom with three twin beds and adjacent full bath, plus the master suite with a king-sized bed and full bath. The Lower level f", "price": "$250.00 ", "neighbourhood": "Mission Terrace"}, {"listing_id": 19872447, "name": "New building luxury 3BR/2BTH-near Mission St", "description": "My place is good for couples, solo adventurers, business travelers, families(with kids), and big groups. The building was construted in 2008, updated electrical and plumbing, fresh paint. lights fill in every rooms. you will have the 2nd floor for your own privacy.", "price": "$275.00 ", "neighbourhood": "Mission Terrace"}, ...]} > Finished chain.
After retrieving results from the API via the GetListings function, the AI Agent is able to autonomously synthesize the results and return them in the appropriate format defined in the system message.
Writing to the Database with an AI Agent
Let’s add another tool to autonomously create bookings on the user’s behalf.
# agent.py def create_booking(data): """this function makes an API call to a REST server to create a booking for a single listing""" # The URL for the API endpoint you want to call url = 'http://localhost:8000/api/bookings' # Making fa POST request to the Flask API to create booking response = requests.post(url, json=data) return response.json() class CreateBookingInput(BaseModel): data: object = Field(description="has 4 keys,'listing_id' and 'customer_id', 'start_date' and 'end_date'") create_booking_tool = StructuredTool.from_function( func=create_booking, name="CreateBooking", description="creates a booking for a single listing", args_schema=CreateBookingInput, )
The tool calls an API endpoint to insert records into the bookings table on behalf of the user.
# api.py
@app.route('/api/bookings', methods=['POST'])
def create_booking():
data = request.get_json()
cur = conn.cursor(cursor_factory=RealDictCursor)
query = "INSERT INTO bookings (listing_id, customer_id, start_date, end_date) VALUES(%s, %s, %s, %s) RETURNING *"
cur.execute(query, [data["listing_id"], data["customer_id"], data["start_date"], data["end_date"]])
rows = cur.fetchone()
rows_json = json.dumps(rows, default=str)
conn.commit()
cur.close()
return jsonify({"data": rows_json, "status": "this is the response from the bookings endpoint"})
Now, we can run the agent to create a booking.
> User Message: Create a booking for 3BED/1BA apartment next to Valencia Street
from 10/15 to 10/20.
> Entering new AgentExecutor chain...
Invoking: `CreateBooking` with `{'data': {'listing_id': 22655239, 'customer_id': 1, 'start_date': '2024-10-15', 'end_date': '2024-10-20'}}`
{'data': '{"booking_id": 101, "listing_id": 22655239, "customer_id": 1, "start_date": "2024-10-15", "end_date": "2024-10-20", "status": "Processing", "created_at": "2024-05-02 17:31:19.204569"}', 'status': 'this is the response from the bookings endpoint'}{"summary": "Your booking for the \"3BED/1BA apartment next to Valencia Street\" from 10/15/2024 to 10/20/2024 has been successfully created. Is there anything else you need assistance with?"}
> Finished chain.
After running the agent, we can verify that the booking was successfully written to the database.
select * from bookings;
booking_id | listing_id | customer_id | start_date | end_date | status | created_at
101 | 22655239| 1 | 2024-10-15 | 2024-10-20 | Processing | 2024-05-02 17:31:19.204569
This functionality can be augmented by equipping the agent with additional tools to edit and delete bookings, as well as a number of other tasks.
Scaling the Agent With Distributed PostgreSQL
We’ve discovered the power of building an AI agent backed by PostgreSQL. Now, let’s explore how we can leverage distributed SQL to make our applications more scalable and resilient.
Here are some key reasons that AI applications benefit from distributed PostgreSQL databases, such as YugabyteDB:
- Embeddings consume a lot of storage and memory. For instance, an OpenAI model with 1536 dimensions takes up ~57GB of space for 10 million records. Scaling horizontally provides the space required to store vectors.
- Vector similarity search is very compute-intensive. By scaling out to multiple nodes, applications have access to unbound CPU and GPU limits.
- Service interruptions won’t be an issue. The database will be resilient to node, data center or regional outages, meaning AI applications will never experience downtime due to the database tier.
YugabyteDB is a distributed SQL database built on PostgreSQL. It’s feature and runtime compatible with Postgres, allowing you to reuse the libraries, drivers, tools and frameworks that were created for the standard version of Postgres.
YugabyteDB has pgvector compatibility, and provides all of the functionality found in native PostgreSQL. This makes it ideal for those looking to level-up their AI applications.
Here’s how you can run a 3-node YugabyteDB cluster locally in Docker.
- Create a directory to store data locally.
mkdir ~/yb_docker_data
- Create a Docker network
docker network create custom-network
- Deploy a 3-node cluster to this network.
docker run -d --name yugabytedb-node1 --net custom-network \ -p 15433:15433 -p 7001:7000 -p 9001:9000 -p 5433:5433 \ -v ~/yb_docker_data/node1:/home/yugabyte/yb_data --restart unless-stopped \ yugabytedb/yugabyte:latest \ bin/yugabyted start \ --base_dir=/home/yugabyte/yb_data --background=false docker run -d --name yugabytedb-node2 --net custom-network \ -p 15434:15433 -p 7002:7000 -p 9002:9000 -p 5434:5433 \ -v ~/yb_docker_data/node2:/home/yugabyte/yb_data --restart unless-stopped \ yugabytedb/yugabyte:latest \ bin/yugabyted start --join=yugabytedb-node1 \ --base_dir=/home/yugabyte/yb_data --background=false docker run -d --name yugabytedb-node3 --net custom-network \ -p 15435:15433 -p 7003:7000 -p 9003:9000 -p 5435:5433 \ -v ~/yb_docker_data/node3:/home/yugabyte/yb_data --restart unless-stopped \ yugabytedb/yugabyte:latest \ bin/yugabyted start --join=yugabytedb-node1 \ --base_dir=/home/yugabyte/yb_data --background=false - Visit the database UI at http://localhost:7001 to verify all nodes are up and running.

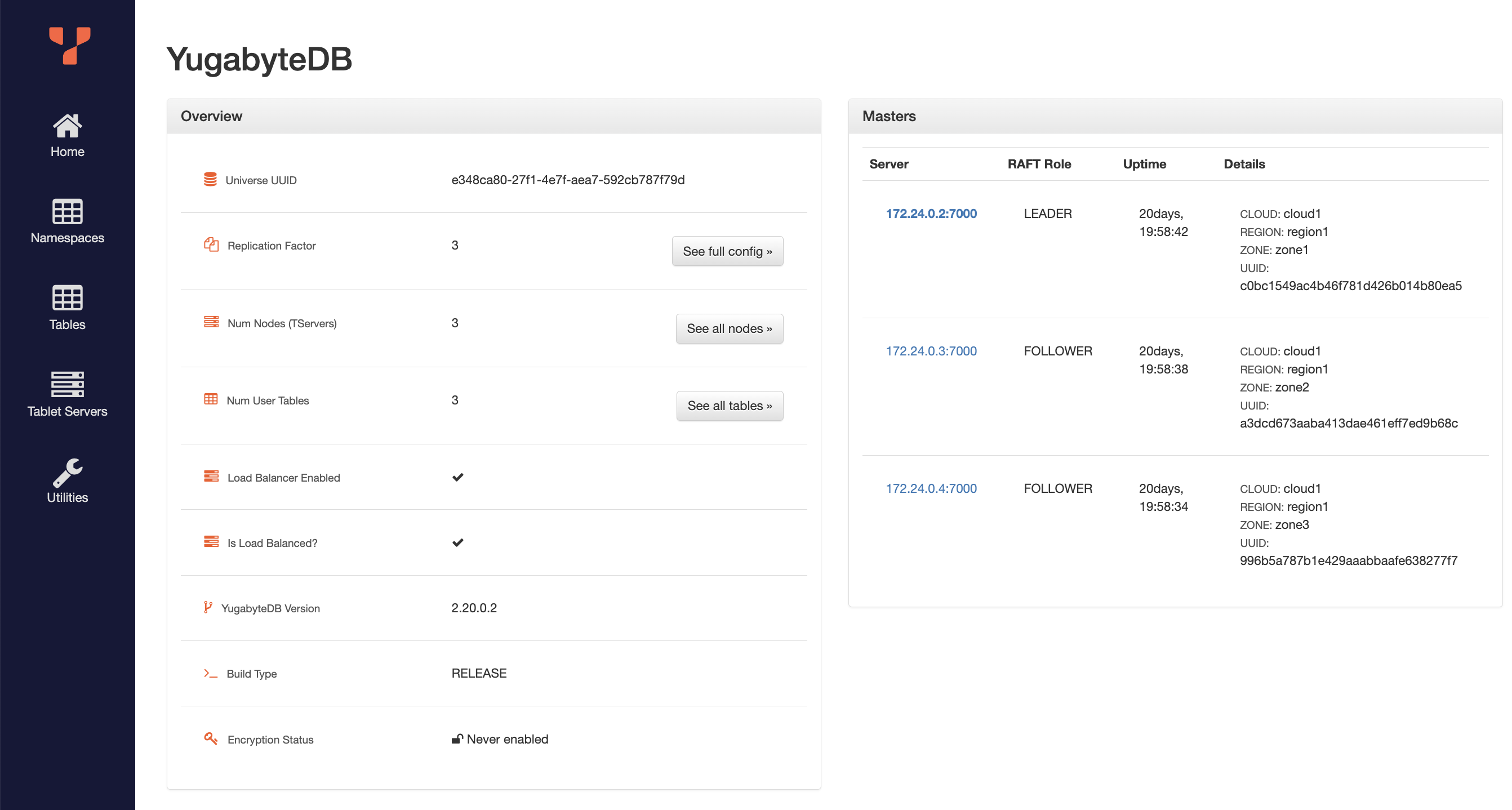
With YugabyteDB running locally, we can now run the travel booking agent application, pointing to this database instead of native PostgreSQL.
# .env DB_HOST=127.0.0.1 DB_NAME=yugabyte DB_USERNAME=yugabyte DB_PASSWORD=yugabyte DB_PORT=5433
By visiting the UI and interacting with the AI agent, we can verify that the switch to YugabyteDB was a success!
Conclusion
Building an AI agent backed by PostgreSQL is easy with the components now available in today’s ecosystem.
By using tools to either directly or indirectly interface with the database, we can build robust agents, capable of autonomously acting on our behalf. With the help of pgvector, it’s easy to store and query text embeddings for similarity search. Additionally, by moving our data to YugabyteDB, we can add scalability and resilience without sacrificing the familiar PostgreSQL syntax.
If you’d like to learn more about building AI applications with YugabyteDB, check out some of our AI tutorials.
If you’re interested in building this project on your own, check out the application on GitHub.


