Building Resilient GraphQL Apps and Scaling Them to 1M Subscriptions
January 26, 2021
GraphQL provides a query language for APIs, giving UX developers autonomy over querying APIs and the database.
The advantages of using GraphQL for UX applications are well understood. GraphQL clients can retrieve only the data needed in the UI application. GraphQL provides a strong type system that avoids manual code parsing and data filtering that takes up precious processing cycles when rendering the UI to users. Additionally, GraphQL increases UX development’s velocity, and the feedback cycles needed for designing API responses are minimized.
For cloud native API developers, factors like GraphQL query performance, handling infrastructure outages, and scalability of GraphQL applications are as important as the ease of use GraphQL provides. In enterprise application development, developers cannot send applications into production without addressing the enterprise’s scaling and resilience needs.
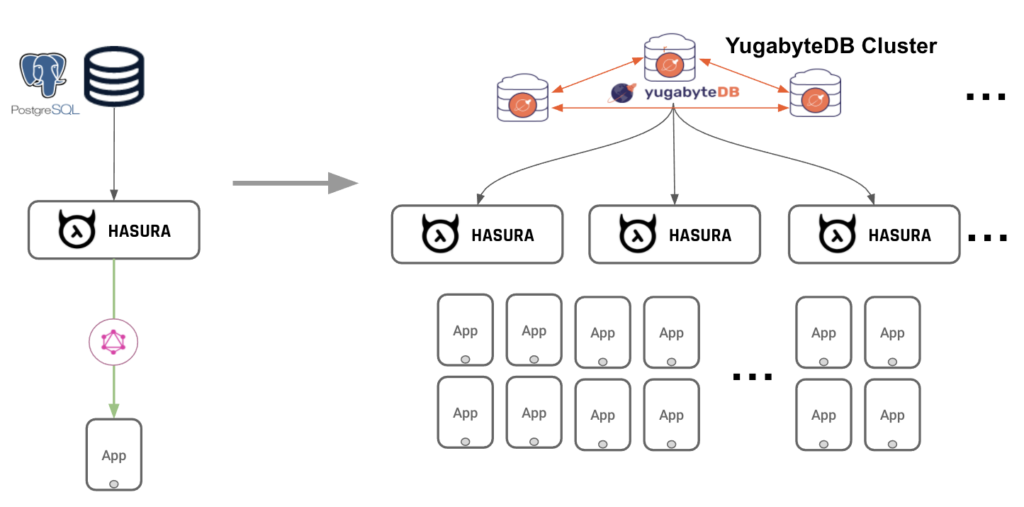
Figure 1: Scaling GraphQL Apps Using Distributed SQL
This blog post will explore the details on scalable and resilient GraphQL apps with distributed SQL databases (Figure 1).
We will show how all of the GraphQL architecture components – GraphQL clients, GraphQL servers, and the database used to serve the GraphQL queries – can scale linearly without any downtime. In order to test the scalability and resilience of GraphQL apps, we benchmarked GraphQL subscriptions using Hasura GraphQL Engine connecting to YugabyteDB.
GraphQL Subscriptions
GraphQL subscriptions are used to fetch data in real time, when new mutations are happening on the database (Figure 2).
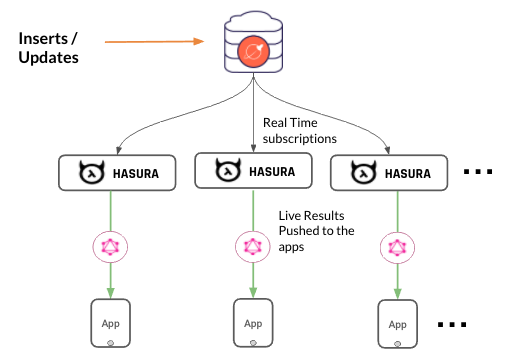
Figure 2: GraphQL Subscriptions
In Hasura GraphQL Engine, GraphQL subscriptions are implemented as live queries, which are nothing but querying the database at regular time intervals (1 sec). As the number of subscriptions increases, the query load on the database also increases.
Scaling Linearly to 1M Subscriptions
The subscription performance tool was designed to test the linear scalability of GraphQL subscriptions using a distributed SQL database. The benchmark setup is modeled to simulate a real world e-commerce user order management system. Benchmark components are explained in detail in the setup section of the blog post.
The table below provides the details on the resources used for the scalability tests and these results are obtained by running the GraphQL subscription perf tool on a Kubernetes cluster where the resources of Hasura GraphQL Engine and YugabyteDB cluster are scaled linearly to handle the increase in user traffic from 25K subscribers to 1 million subscribers. Detailed observations of the results can be found in the git repo here.
The results obtained by running the benchmarks on a Kubernetes cluster where GraphQL subscriptions are scaled from 25K subscriptions to 1 million subscriptions linearly without any downtime are as follows:
| No. of Subscriptions | YugabyteDB: Number of vCPUs | Hasura: Number of vCPUs |
|---|---|---|
| 25K | 8 | 4 |
| 50K | 16 | 12 |
| 100K | 32 | 20 |
| 1M | 320 | 200 |
Note: All the components of this benchmark were containerized and deployed on a Kubernetes cluster.
High Availability: Impact of a Database Pod Failure on GraphQL Subscriptions
This scenario simulates the result of a database pod failure while new orders are being placed, and these orders are being consumed by the GraphQL client applications using subscriptions.
The Hasura GraphQL Engine is stateless, and the loss of a pod in the Hasura service can easily be mitigated by rerouting the query to another pod. The YugabyteDB service is stateful, and hence this section measures the impact of losing a YugabyteDB pod. Note that the YB-TServer service in the YugabyteDB cluster is responsible for serving all application queries, and hence is the pod that is being killed.
The following results were observed as a result of killing a YugabyteDB T-server pod with 100K subscription setup.
| Database Operations | Observed Behavior |
|---|---|
| Read Transactions |
|
| Update Transactions |
|
| Data loss |
|
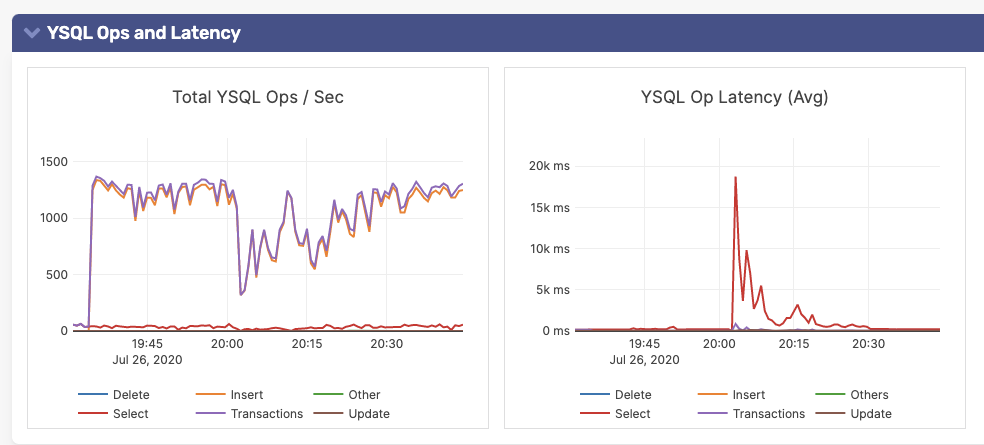
Figure 3: YugabyteDB Metrics Observed During T-server Pod Failure
Detailed observations of the metrics under different failure scenarios can be found in the git repo here.
The Setup for Scale and Resiliency Tests
GraphQL Subscriptions – The Sample Application
To benchmark GraphQL Subscriptions, we created a sample application, the application being modeled as a user order tracking service. Users place orders, which need to be delivered. These orders are tracked, and a notification is posted in real-time to kick off the order fulfillment.
Database Schema
Two tables are used to model this scenario. The user_account table has information about the user, while the user_orders table has the list of orders placed by any user. The schema of these tables is shown below.
CREATE TABLE user_account ( userID BIGINT NOT NULL , accountName VARCHAR , givenName VARCHAR , middleName VARCHAR , familyName VARCHAR , userGender VARCHAR , userAge INT, Dob TIMESTAMP, address1 VARCHAR , address2 VARCHAR , city VARCHAR , zip VARCHAR , email VARCHAR , homePhone VARCHAR , mobilePhone VARCHAR , country VARCHAR , company VARCHAR , companyEmail VARCHAR , active BOOLEAN , PRIMARY KEY (userID HASH) ); CREATE INDEX user_fname ON user_account (givenName) ; CREATE INDEX user_lname ON user_account (familyName) ;
CREATE TABLE user_orders ( userID BIGINT NOT NULL , orderID VARCHAR NOT NULL , orderTotal VARCHAR NOT NULL , orderDetails VARCHAR NOT NULL , deliveryStatus VARCHAR NOT NULL , orderTime TIMESTAMP NOT NULL , PRIMARY KEY (userID HASH, orderID ASC) );
GraphQL Subscriptions
The following GraphQL query, which lists the most recent orders by a given user, is used for benchmarking subscriptions using Hasura GraphQL Engine and YugabyteDB.
subscription ($id: bigint!) {
user_account (where: {userid: {_eq: $id}}) {
accountname
givenname
familyname
city
user_orders(order_by: {orderid: desc}) {
orderid
ordertotal
orderdetails
ordertime
deliveryStatus
}
}
}
Benchmark Setup on Kubernetes
The entire setup runs inside Kubernetes. Below are the main components:
- A YugabyteDB cluster running natively inside k8s
- A Hasura k8s service
- The sample application which consists of:
- A load generator which generates user orders
- A GraphQL application which subscribes to incoming orders
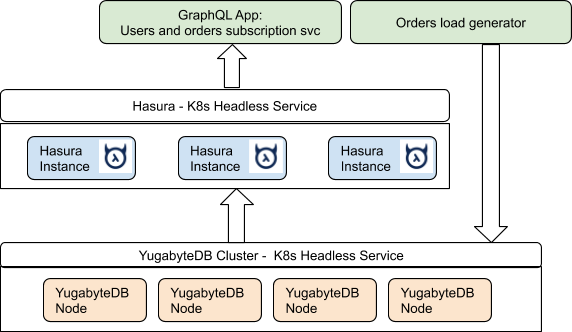
Figure 4: Benchmark Setup
The benchmark setup is shown diagrammatically above (Figure 4). Detailed steps for the benchmark setup can be found in the git repo here.
As you can see from the benchmark architecture, all the components of the GraphQL architecture can be scaled independent of each other and components are highly available against infrastructure failures.
Conclusion
As more and more UX developers start embracing the use of GraphQL APIs for accessing databases, the stateless nature of GraphQL servers makes it essential for databases to handle the scale and resiliency needs of GraphQL apps. This blog post provided detailed observations on how native support for linear scaling and high availability of the YugabyteDB distributed SQL database are well suited for building scalable and resilient GraphQL apps.


