Change Data Capture (CDC) Using a Spring Data Processing Pipeline
May 26, 2022
Change Data Capture (CDC) is a technique to capture changes in a source database system in real-time. The goal is to stream those changes as events through a data processing pipeline for further processing.
CDC enables many use cases, especially in modern microservices-based architecture that involves a lot of bounded services. It is the de-facto choice for use cases such as search indexes, in-memory data cache, real-time notifications, data sync between sources, and fraud detection.
In this post, we’ll explore YugabyteDB’s pull-based CDC API introduced in version 2.13 alongside a practical business case using a Spring Data processing pipeline.
Business case: Flight operations API with a Spring data processing pipeline
In our business case, a flight operations API will capture the flight schedule change events in real-time from the source system using CDC. From there, it will send it to a processing pipeline that applies a specific set of business rules. These rules are based on the arrival and departure time delay to send notifications to the appropriate internal servicing units such as ground-ops and crew-ops. Similarly, we can extend it to other source events to build the complete flight-ops real-time notification data processing pipeline using CDC.
But we need the following components to build this use case, as illustrated in the below diagram.
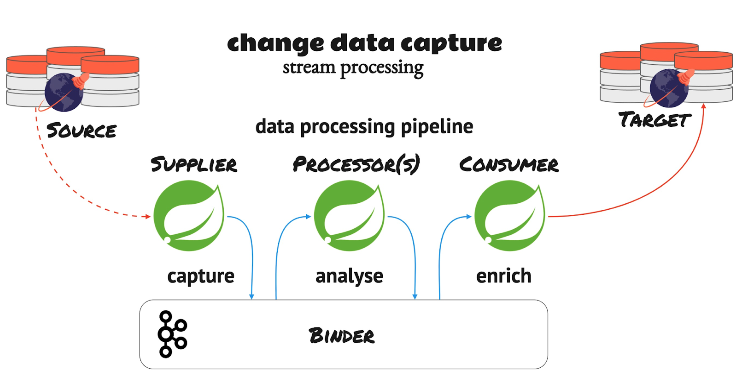
- A source database system
- A supplier service to capture the flight schedule changes through CDC from the source database system
- A processor service to apply the flight delay business rule
- A consumer service to generate the notification events
- A target database system to store the notification events
- Message binders to move the events through the pipeline
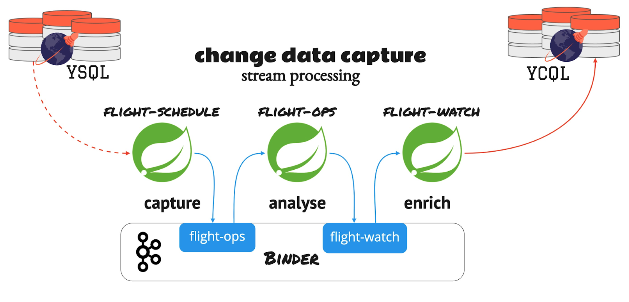
Data source and sink
We’ll use YugabyteDB’s YSQL as the source database for the flight schedule. We’ll also use YugabyteDB’s YCQL as the target database to keep the notification events. We can have a different target system as well. But in this example, we’ll explore how we can leverage the newly-introduced CDC API to move the data between these two APIs.
Spring data processing pipeline
We’ll use Spring Cloud Stream to build the data processing pipeline. Spring Cloud Stream builds message-driven services with Spring Boot and Spring Integration libraries to create production-grade services. More specifically, it provides a consistent and quick getting started experience to implement various integration patterns.
However, we can run these stream services as individual applications or deploy them using Spring Cloud Dataflow, which provides the necessary tools to manage the lifecycle efficiently. We can also quickly deploy these stream services with data flow like a Unix-style processing pipeline: “flight-schedule | flight-ops | flight-watch.” It follows the same Unix philosophy of “do one thing; do it well” and gives a much-needed bounded abstraction.
We can then easily link these pipelines through a binder infrastructure. This infrastructure provides out-of-the-box integration with well-known binders such as RabbitMQ, Kafka, and Google Pub/Sub. As developers, the focus is on the business logic, whereas the framework provides the link to the binder infrastructure.
Message binder and bindings
Binders are the extended components of the framework that provide the necessary configuration and boilerplate code to facilitate interactions with the external systems. Its minimalistic integration philosophy requires developers to provide less information like binder type and topic/queue name. Additionally, the integration “heavy lifting” is taken care of automatically by the framework. For this business case, we’ll use Apache Kafka as the messaging infrastructure to bind the data processing stream services, as illustrated below.
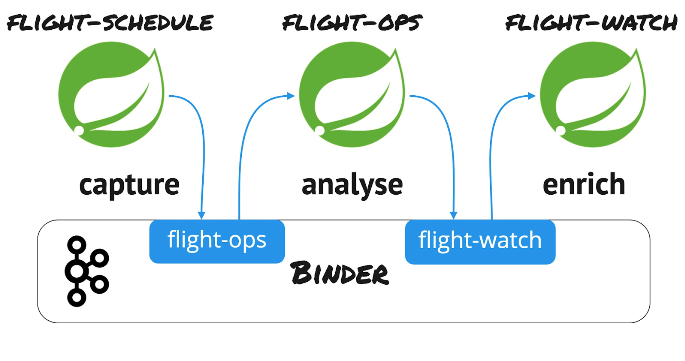
Flight schedule: Supplier
We’ll build the flight-schedule supplier API based on the Debezium CDC Source. This API automatically captures and streams events from various databases. It also supports MySQL, PostgreSQL, and other databases. As YugabyteDB is code compatible with PostgreSQL, we can quickly get started with minimal customization.
Since the underlying CDC technique is different between PostgreSQL and YugabyteDB, we have published our Debezium connector to tap the source changes using the same Debezium infrastructure. The supplier service uses this connector instead of the PostgreSQL connector to tap the changes from the relational YSQL source for the flight schedule change events. Additionally, please refer to this link for the “flight-schedule” supplier source code.

The API doesn’t require any source code change other than the above configuration updates. We still use the connector type as PostgreSQL, but we override the connector class with YugabyteDB’s Debezium connector implementation.
With these updates, the “flight-schedule” supplier does the following:
- Through the connector implementation, it captures the flight schedule changes from the YugabyteDB YSQL source (flight_schedule table) through the CDC API.
- Through the binder-based bindings, it also streams the schedule change events to a Kafka topic (flight_ops).
Flight ops: Processor
The flight-ops is a function that applies the flight delay business rule to the input “flight-schedule” change events from the “flight-ops” topic. It accepts the “flight-schedule” change event as the input, applies the business rule, and produces the “flight-watch” events. The flight-watch events are populated appropriately with the notification service units based on the defined “flight-delay” business rule. However, the “flight-delay” business rules are hard-coded in the same service for brevity. This information in a real-world use case is usually dynamic and populated through external feeds.

In summary, the “flight-ops” processor function does the following:
- Through the binder-based bindings, it consumes the “flight-schedule” change events from the Kafka topic (flight_ops).
- It runs the “flight-delay” business rule.
- It populates the “flight-watch” notification event.
- Through the binder based bindings, it streams the “flight-watch” events to a Kafka topic (flight_watch).
Flight watch: Consumer
The “flight-watch” consumer is a function that terminates this data processing pipeline. It receives the “flight-watch” events with the notification information. It is then persisted in the YugabyteDB target database using the YCQL API. The same event can be pushed down to other downstream systems as well.

In summary, the “flight-watch” consumer function does the following:
- Through the binder-based bindings, it consumes the “flight-watch” events from the Kafka topic (flight_watch).
- The “flight-watch” events are persisted in the target database through the YCQL API to notify the appropriate servicing units.
This completes our data processing pipeline.
Spring data processing pipeline: Try it yourself
You can find the complete source code in this repo. To produce a better getting started experience, we have added Gitpod support so you can try this out with a single click. You don’t need to make any of the infrastructure components. All you need is to fork the source repo and launch the Gitpod terminal using the browser plugin.
Conclusion
In this blog, we looked at how to leverage the newly introduced CDC API in YugabyteDB to quickly build a Spring data processing pipeline using Debezium and Spring Cloud Stream.
Finally, please review our documentation to learn more about YugabyteDB’s CDC feature.
Have questions about YugabyteDB? Join our vibrant Community Slack channel to chat with over 5,500 developers, engineers, and architects.


