Embracing Chaos: Testing Resiliency and Consistency in YugabyteDB
September 13, 2024
It has been a while since we posted our last Jepsen update, and we know many are eager to hear the latest news. This new blog provides the latest updates, as well as sharing information on additional in-house built frameworks for resiliency and consistency testing that go far beyond Jepsen.
Resiliency and consistency testing is more than just another set of metrics for our engineering team. We say that YugabyteDB is distributed Postgres that scales and never fails, and we evidence this by building and using the most advanced testing frameworks.
The frameworks shared in this blog are designed to try to bring the database down by simulating failures we hope nobody ever experiences in production. Seeing that YugabyteDB can tolerate even the most unlikely major incidents gives us confidence that our open source users and customers are getting the most reliable distributed version of Postgres available.
Below we start with Jepsen, then do a deep dive into our chaos testing framework. We finish by discussing how we test the resiliency of the operating system, hardware, and various deployment environments.
Jepsen Testing
We want to start by thanking Jepsen and its dedicated owner, Kyle Kingsbury, for their continuous efforts in evolving and refining this invaluable testing framework.
Since 2019, our QA and engineering teams have been diligently upgrading our testing environment to take advantage of Jepsen’s latest enhancements. We’ve expanded our test suite significantly, adding new scenarios and advancing existing ones with features that push the boundaries of distributed database testing.
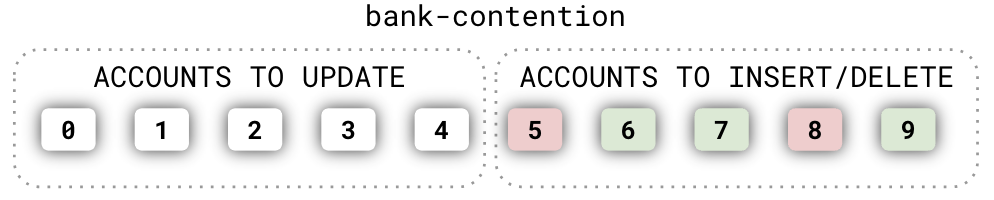
- Expanded Scenarios: We’ve introduced the bank-contention scenario to address the original bank workload’s limited INSERT/DELETE coverage. As the figure below shows, this extended scenario uses two key spaces: one for updates and another for insert/delete operations. We’ve also enhanced the append scenario by incorporating READ COMMITTED and REPEATABLE READ isolation levels, geo-partitioning, and random row-level locking for read operations.

- New Feature Coverage: Our Jepsen tests now include a wide range of YugabyteDB features, including:
- Read Replicas: integrated follower-read operations using read-replicas into bank workloads for comprehensive read-operation testing.
- Wait-On-Conflict: the concurrency control mode was added to both bank and append tests, simulating real-world concurrency scenarios.
- Snapshot (Repeatable Read) & Read Committed: incorporated these isolation levels into append tests (thanks to the elle), ensuring robust isolation level testing.
- Cross-Geo Transactions: expanded the append suite of tests to cover geographically distributed transactions.
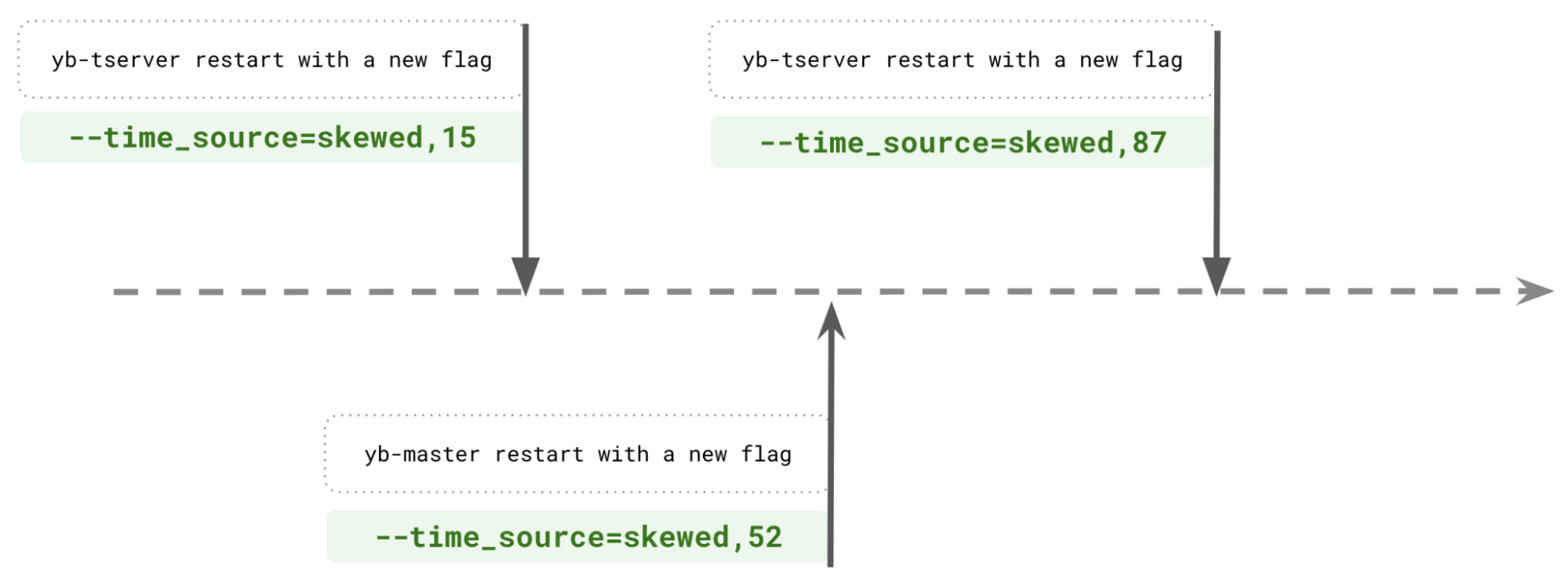
- Software Clock Skew: randomly introduce clock skew on restarts using a gflag, simulating real-world clock synchronization challenges.
For example, the figure below shows a timeline and test with yb-master and yb-tserver restarts; each new restart changes the time_source gflag to a random value.
- Colocation: randomly activated colocation capability in YSQL tests, adding another layer of complexity and realism.
This is just a taste of our ongoing Jepsen journey. Check out our technical documentation to learn more about various testing scenarios.
Embracing Chaos
While Jepsen provides an invaluable foundation for verifying transactional consistency, a truly distributed transactional database requires a much broader testing approach.
Performance, functionality, and above all, resilience under chaotic conditions are paramount, especially in the world of distributed systems. That is why we have gone beyond the Jepsen framework, embracing chaos engineering as a core principle in our quest to build the most resilient distributed PostgreSQL database.
Our journey beyond Jepsen began with the realization that we needed to push YugabyteDB to its absolute limits and simulate a wider range of failures than standard Jepsen scenarios typically cover. This led us to develop a specialized chaos testing framework that injects various Jepsen-inspired failures directly into our YugabyteDB clusters.
This framework is now deeply integrated into our development process. We subject every new feature to rigorous chaos testing before it reaches our users.
Let’s review some areas our chaos testing framework covers.
Additional Transactional Consistency Checks
Even within the realm of transactional consistency, we felt the need to go beyond the standard Jepsen bank workload.
This workload is a simple yet powerful tool for validating transactional consistency, using only update operations by default. However, this leaves gaps in coverage, which we aim to improve. To address this, we’ve enhanced the workload significantly:
- Multi-Table Workloads: recognizing that real-world applications rarely operate on a single table in isolation, we introduced workloads that span multiple tables with multiple indexes. This adds a much needed layer of complexity to our tests, letting us to find concurrency issues that might arise from interactions between different tables.
- Rolling Segment Keys: instead of focusing solely on updates and separate insert/delete key spaces, we implemented a rolling segment key strategy. As the picture below shows, ‘delete’ targets keys at the beginning of the dataset, while ‘insert’ adds new keys at the end. This not only simplifies debugging but also eliminates the need for in-memory validation. This simplifies our test setup and provides an additional layer of verification by directly checking data integrity at the storage level.
- Row-level Locks: to simulate the complexities of high-contention environments, we incorporated row-level locks into our test scenarios. By simulating row-level locking, we can effectively identify potential deadlocks and other concurrency issues that could occur in real-world deployments.

To show you how different datatypes coverage works, here are some example CREATE TABLE and SELECT statements used to check balances:
CREATE TABLE bank_i (id INT, balance INT); SELECT balance FROM bank_i WHERE id = ? FOR KEY SHARE; CREATE TABLE bank_j (id INT, balance JSON); SELECT (SUBSTRING((%s->'content'->>'value') FROM ':(.*?)(:|$)'))::bigint AS balance FROM bank_j WHERE id = ?; CREATE TABLE bank_v (id INT, balance VARCHAR); SELECT (SUBSTRING(%s FROM ':(.*?)(:|$)'))::bigint FROM bank_v WHERE id = ? FOR SHARE; CREATE TABLE bank_t (id INT, balance TIMESTAMP); SELECT EXTRACT(MILLISECONDS FROM %s) AS epoch_days FROM bank_t WHERE id = ?; ...
A Universe of Workloads: Simulating Real-World Chaos
While the Jepsen’s enhanced bank workload provides a robust foundation, our chaos testing extends far beyond this single scenario.
New features often demand custom workloads designed to target specific behaviors and push the boundaries of YugabyteDB’s capabilities.
We’ve developed a diverse suite of workloads, some designed to saturate the system with data at extreme rates, while others meticulously simulate the complex and long-running transactions common in real-world applications. This constant expansion of our workloads helps YugabyteDB prepare for any challenge a distributed database might face in production.
Below is a code snippet from our test code focused on testing connections. We aim to run a connection-intensive workload to collect statistics on process memory usage, connection creation time, and various other small data points. There are several parameters involved, so let’s walk through them briefly.
self.sample_app.run_workload(
SampleAppWorkloads.SQL_DATA_LOAD_WITH_DDLS,
target_addresses,
run_on_hosts=[self.config.meta.client_public_hosts[0]],
properties={
WorkloadProperty.NUM_WRITES: -1,
WorkloadProperty.NUM_THR_WRITE: 600,
WorkloadProperty.NUM_THR_READ: 600,
WorkloadProperty.NUM_READS: -1,
WorkloadProperty.NUM_UNIQUE_KEYS: 300_000_000_000,
WorkloadProperty.NUM_INDEXES: 5,
WorkloadProperty.NUM_FRG_KEYS: 5,
WorkloadProperty.USE_DATATYPES: "true",
WorkloadProperty.NUM_VALUE_COLUMNS: 50,
WorkloadProperty.USE_HIKARI: "true",
WorkloadProperty.DDL_OPERATIONS: "INSERT_ROW,ADD_COLUMN,DROP_COLUMN",
WorkloadProperty.TRACE_CONNECTION_CREATION_TIME: "true",
WorkloadProperty.OUTPUT_JSON_METRICS: True,
}
)First, we define the unlimited number of writes and reads (NUM_WRITES and NUM_READS), the number of threads (NUM_THR_WRITE and NUM_THR_READ), unique keys (NUM_UNIQUE_KEYS), foreign keys (NUM_FRG_KEYS), and indexes (NUM_INDEXES).
Next, we include 50 columns (NUM_VALUE_COLUMNS) with different data types (USE_DATATYPES), and yes, we’re using HikariCP in this test (USE_HIKARI).
We’re also outputting JSON metrics (OUTPUT_JSON_METRICS) to gather information about connection creation throughput and latency (TRACE_CONNECTION_CREATION_TIME). Additionally, there’s an option to call DDL operations (DDL_OPERATIONS) in parallel.
Cloud Chaos Testing and Other Deployments
We don’t just test in pristine, isolated settings. Our chaos testing spans a variety of cloud platforms and Kubernetes setups, mirroring the diverse deployments our users rely on.
When we say chaos, we mean it! Here’s a glimpse of the havoc we unleash:
- Cloud API Mayhem: we leverage the power of cloud APIs (such as those provided by AWS) to trigger a range of disruptions, including node restarts, unexpected shutdowns, and volume detachments.
- YugabyteDB-specific Chaos: we go beyond simulating external failures by injecting chaos directly into the core of YugabyteDB. Using tools like yb-admin, we introduce targeted failures in critical components like yb-master and yb-tserver processes, rigorously testing their recovery mechanisms and ensuring the database can withstand internal turbulence.
- OS-level Havoc: we simulate a wide array of real-world infrastructure problems, including clock strobes, network partitions, DNS failures, network slowdowns, and storage disruptions, ensuring YugabyteDB can weather the storms that often disrupt production environments.
- Stress-ng Torture: we push the limits of both hardware and software by employing stress-ng to overload memory, CPUs, networks, I/O operations, and the OS scheduler. This allows us to uncover bottlenecks and ensure YugabyteDB can easily handle extreme resource contention.
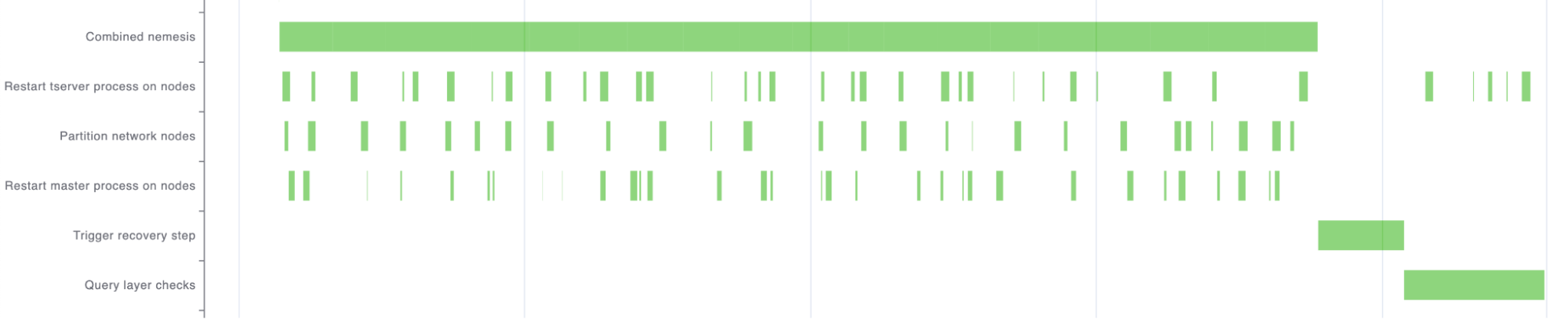
Let’s briefly demonstrate how our fault injector code works in practice. The nemesis randomly determines the time intervals for invocation and recovery. Typically, the calls and recoveries involve a single line of code, triggering an existing API or executing a remote SSH command.
In the graph below, you can observe the combined nemesis behavior during the test.
Simple API, Powerful Insights
Our chaos testing framework is built on the principle of “simple to use, powerful in its insights.” Our nemesis API makes injecting failures and monitoring database recovery straightforward. Most tests rely on predefined settings for common failure scenarios, simplifying the testing process without sacrificing depth or rigor.
Built-in checks and validations ensure test reliability, and we adhere to a strict “no crashes or FATAL errors” policy. Data integrity is fundamental, so we go beyond generic checks, incorporating data-specific validations to guarantee that even under extreme chaos, data remains consistent and accurate.
Let’s illustrate this with another example: tablet splitting tests.
In our stress scenarios, we don’t just enable tablet splitting; we push the system to its limit, forcing almost every insert to trigger a split. And we don’t stop there. As the code snippet below shows, we simultaneously inject node restarts, network slowdowns, and use a “large keys” flag to extend certain varchar columns to 100+ times their normal size with pseudo-random, yet deterministic data. This creates a perfect storm for our database to weather, helping us uncover even the most subtle edge cases in our tablet splitting logic.
self.stress_tablet_splitting(
YugabyteApi.YSQL,
large_keys=True,
nemesis_list=[
NodeRestartNemesis(self.config, self.yb, self.reporter,
node_type=YugabyteNodeType.TSERVER),
NodeRestartNemesis(self.config, self.yb, self.reporter,
node_type=YugabyteNodeType.MASTER),
NetworkPartitionNemesis(self.config, self.yb, self.reporter),
],
scenario_exceptions=self.nemesis_exceptions)The cornerstone of our data validation approach in this scenario is the utilization of pseudo-random data.
The code below shows that every single row in our tables can be reconstructed using its row-key number and a predefined UUID. This might seem random at first glance, but it’s entirely deterministic, allowing us to invest heavily in thorough data validation, ensuring the integrity of every bit of data, even under the most intense splitting and simulated failures.
public static String defaultValueStringRepresentation(Long key) {
if (largeValuesMultiplier > 1) {
return String.format("%s:%s:seed:%s", keyUUID, keyLong,
getPseudoRandomSeed(largeValuesMultiplier, keyPrefix, key));
} else {
return String.format("%s:%s", keyUUID, keyLong);
}
}To learn more about our chaos testing adventures, check out our blog post, A Behind-the-Scenes Look at Chaos Testing.
The Journey Continues
Building a resilient distributed PostgreSQL database involves continuous improvement and rigorous testing. Our existing Jepsen tests and chaos-driven testing framework plays a crucial role in identifying and addressing vulnerabilities.
However, for cloud-native applications and distributed systems, traditional testing methods fall short. Chaos testing, once niche, is now essential for every database. It reveals critical vulnerabilities requiring immediate attention. The unpredictable nature of modern infrastructures demands this approach.
Embracing chaos is essential for building modern applications (and databases) that scale and never fail.


