Creating Standard Patterns to Load Data into YugabyteDB with Apache Airflow
March 25, 2021
At this year’s Distributed SQL Summit Asia 2021, Viraj Parekh and Pete DeJoy from Astronomer presented the talk, “Creating Standard Patterns to Load Data in YugabyteDB with Apache Airflow.”
Apache Airflow is an open source workflow orchestrator that is used by data teams of all sizes. Airflow is trusted by organizations like Marriott, RBC, Zapier, and Sonos. Given its flexible nature, Airflow is used to interact with everything from legacy on-prem systems to distributed, Kubernetes-native applications. As organizations undergo digital transformations, users responsible for data workloads are often tasked with coordinating these legacy and cloud native systems concurrently. The growing number and complexity of these workloads forces teams to adopt standardization around maintainability, reusability, and extendability.
In this talk, Viraj and Pete showcase how data platform engineers can provide a standard template for users to perform business-specific actions with Apache Airflow to replicate Postgres data to a distributed YugabyteDB instance. They conclude with a brief overview of the Airflow Provider framework. Below are the highlights from the talk.
What Is Airflow?
Pete kicked things off by orienting us with what Airflow and Astronomer are, plus the basic concepts of building data pipelines. The Apache Airflow project is a Python-based open source platform to programmatically author, schedule, and monitor data pipelines. It was originally developed inside of Airbnb in 2015 and graduated to a top-level Apache project in 2019. Since its launch, Airflow has amassed 20k GitHub stars, is downloaded well over 600k times per month, and boasts over 1000 enterprise data teams using it for their projects. Another way to think about Airflow is that it is an “Orchestrator of Data Pipelines-as-Code.”
What Is Astronomer?
Astronomer is the company behind Airflow. In the same way that Databricks is to Spark, and Confluent is to Kafka, Astronomer is to Airflow.
How Data Pipelines Work in Airflow
In Airflow, a data pipeline encodes the series of sequential steps you want to perform in a data processing task. Event triggers and schedules are common reasons you might want to kick off the execution of a data pipeline. As you can imagine, extracting, transforming, and loading (ETL) jobs are often found in data pipelines. Note, that you do also have the option of executing these steps in parallel.
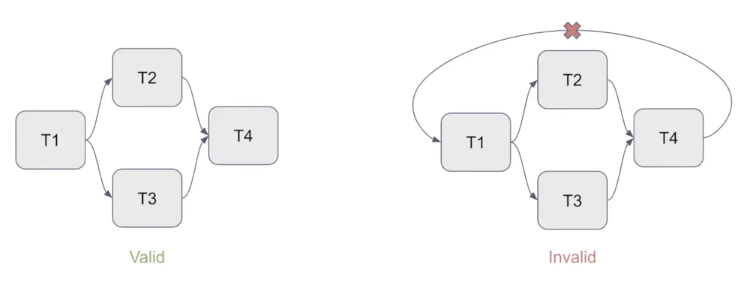
These data pipelines are expressed in Airflow as Directed Acyclic Graphs (DAGs). Below is a visualization of a DAG with sequential steps, including one that happens in parallel.
Working with the Airflow Ecosystem
Data is everywhere, which means that you’ll need a variety of connectors and integrations to wire everything up in your data pipelines. Airflow accomplishes this by providing Python-based abstractions over third-party APIs, including:
Hooks establish connections to third-party data stores like YugabyteDB, PostgreSQL, Hadoop, and Spark, but also popular services available on the public clouds of Google, Amazon, and Microsoft.
Operators perform predefined logic tailored to specific use cases including:
- Actions – encapsulate some arbitrarily defined logic
- Transfers – move data from point A to point B
- Sensors – wait for some external trigger before kicking off some logic
Providers “wrap up” Hooks and Operators into Python packages that contain all the relevant modules for a specific service provider.
The Airflow Providers Framework
This plugin framework consists of a library of pre-built, open source components that handle third-party data service integration that enable you to connect, transfer, manipulate, and analyze your data. This framework is decoupled from the core Airflow project, which means you don’t have to wait for new releases of Airflow to make use of the latest and greatest integrations.
Use Cases for Airflow
In the next section of the talk, Viraj walked us through the data pipeline of an Airflow user.
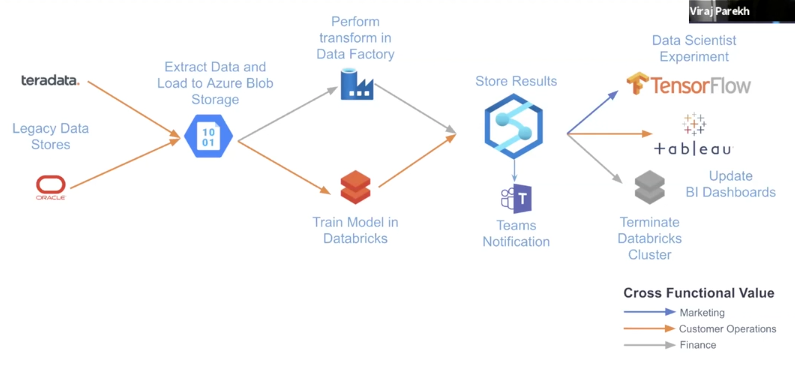
He also walked us through a hypothetical scenario:
“As a data platform engineer, I need my team to move data from my application’s MySQL backend to a distributed SQL database — YugabyteDB.”

He broke the task into three main steps:
1. Connect to MySQL – use Airflow’s MySQL hook to create the connection
2. Extract the Data to AWS S3 – use Airflow’s MySQL to AWS S3 transfer operator to extract and load the data into S3
3. Load the Data into Yugabyte Cloud – because YugabyteDB is PostgreSQL-compatible, we can use the Airflow’s PostgreSQL and S3 hooks. There is no need to build custom hooks in this scenario.
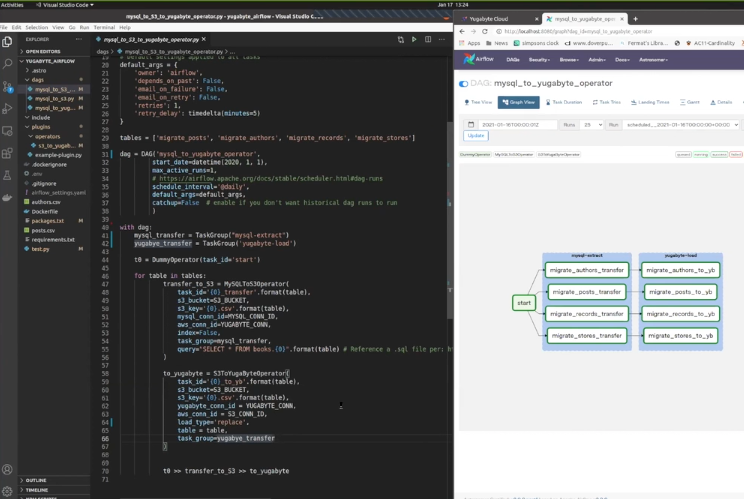
In the final section of the talk, Viraj showed a live demo of the above data pipeline in action.
What’s Next?
To view this talk, plus all twenty-four of the talks from this year’s Distributed SQL Summit Asia event make sure to check out our video showcase for the event on our Vimeo channel.
Ready to start a conversation about how Distributed SQL can help accelerate your journey to cloud? Join us on the YugabyteDB Community Slack to get the conversation started.


