Creating a Powerful, Unified, Data Architecture With YugabyteDB and ClickHouse
April 2, 2025
PostgreSQL 15 compatible YugabyteDB allows for seamless integration of high-volume transactional workloads with real-time analytics. By combining distributed, PostgreSQL-compatible OLTP database YugabyteDB with high-performance OLAP engine ClickHouse, organizations can leverage the strengths of both systems.
In this blog, we showcase the integration of YugabyteDB and ClickHouse using the popular Yellow Taxi Data as an example and highlight the business value of enabling bi-directional communication between the two platforms.
Why Is This Integration Important?
Integrating YugabyteDB and ClickHouse creates a powerful, unified data architecture that optimizes performance, scalability, and real-time analytics. YugabyteDB ensures transactional consistency and high availability for OLTP workloads, while ClickHouse delivers lightning-fast analytical processing for OLAP workloads.
This seamless integration enables real-time data flow, ensuring that operational and analytical layers remain synchronized without duplication. By eliminating the need for manual ETL, it reduces complexity, maintenance costs, and data inconsistencies.
With each system handling what it does best, businesses can achieve high-performance transactions, real-time insights, and cost-efficient scalability. Unified reporting and bi-directional synchronization ensure that decision-making is always based on the most accurate, up-to-date data, empowering organizations to act swiftly and intelligently.
High-Level Data Flow:
The below diagram (Figure 1) shows the two‑way communication, helping to create a seamless data pipeline that:
- Bridges OLTP (transaction processing) and OLAP (analytical querying)
- Simplifies data management by eliminating redundant ETL processes
Figure 1 – YugabyteDB and Clickhouse Integration
Architecture:
- YugabyteDB stores detailed transactional data with PG15 compatibility. ClickHouse uses its MergeTree engine to quickly aggregate and analyze this data.
- Aggregated results are then pushed back into YugabyteDB via linked tables so that transactional systems or dashboards can use the summarized insights.
How it Works:
This conceptual diagram (Figure 2) represents the integration of YugabyteDB with ClickHouse using different methods:
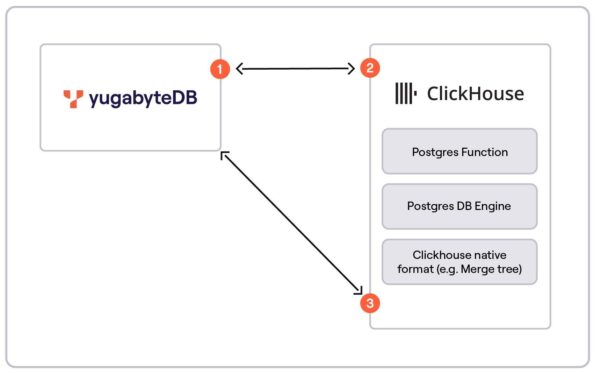
Figure 2 – Communication Flow between YugabyteDB and Clickhouse
| Data Flow Sequence | Operations/Tasks | Component Involved |
|---|---|---|
| 1 | YugabyteDB Objects needs to be created (e.g. Table or View) using YugabyteDB 2.25 Install YugabyteDB 2.25 using THIS link.Choose V2.25 (Preview) before downloading the binaries for your operating systems. | Native YugabyteDB Objects |
| 2 | Postgres Function: Creates a connection per query and streams data into ClickHouse. CREATE NAMED COLLECTION mypg AS host = 10.0.1.197, | Named Collection Reference HERE |
| 3 | PostgreSQL database engine. In this case, we mirror the entire database and can utilize all of its respective tables. This also allows us to execute DDL commands to modify and drop columns in tables in the underlying YugabyteDB instance. | PostgreSQL Database Engine Example: CREATE TABLE pg_table2 (sno UInt32) |
Overview of the Integration
Architecture:
- YugabyteDB stores detailed transactional data such as individual taxi trips (here we used NYC Yellow Taxi Trips data).
- ClickHouse uses its MergeTree engine to quickly aggregate and analyze this data.
- Aggregated results are then pushed back into YugabyteDB via linked tables so that transactional systems or dashboards can use the summarized insights.
Step 1: Loading Yellow Taxi Data into YugabyteDB
Begin by loading your detailed Yellow Taxi Data into YugabyteDB. For example, you might create a table for taxi trip details:
CREATE TABLE yellow_taxi_trips (
VendorID INT,
tpep_pickup_datetime TIMESTAMP,
tpep_dropoff_datetime TIMESTAMP,
passenger_count INT,
trip_distance NUMERIC(10,2),
RatecodeID INT,
store_and_fwd_flag CHAR(1),
PULocationID INT,
DOLocationID INT,
payment_type INT,
fare_amount NUMERIC(10,2),
extra NUMERIC(10,2),
mta_tax NUMERIC(10,2),
tip_amount NUMERIC(10,2),
tolls_amount NUMERIC(10,2),
improvement_surcharge NUMERIC(10,2),
total_amount NUMERIC(10,2),
congestion_surcharge NUMERIC(10,2)
);
CREATE TABLE yellow_taxi_trips_detail (
VendorID INT,
tpep_pickup_datetime TIMESTAMP,
tpep_dropoff_datetime TIMESTAMP,
passenger_count INT,
trip_distance NUMERIC(10,2),
RatecodeID INT,
store_and_fwd_flag CHAR(1),t
PULocationID INT,
DOLocationID INT,
payment_type INT,
fare_amount NUMERIC(10,2),
extra NUMERIC(10,2),
mta_tax NUMERIC(10,2),
tip_amount NUMERIC(10,2),
tolls_amount NUMERIC(10,2),
improvement_surcharge NUMERIC(10,2),
total_amount NUMERIC(10,2),
congestion_surcharge NUMERIC(10,2),
primary key (vendorid,tpep_pickup_datetime , pulocationid, dolocationid)
);
#Load the 24.6 Million trip records into Stage table (yellow_taxi_trips)
yugabyte=# \copy yellow_taxi_trips FROM '/Users/bseetharaman/Downloads/2020_Yellow_Taxi_Trip_Data.csv' WITH CSV HEADER;
COPY 24,648,499
#Update the records as 0 for the records with vendorid is NULL
yugabyte=# UPDATE yellow_taxi_trips SET vendorid = 0 WHERE vendorid IS NULL;
UPDATE 809568
#Delete the duplicate records which are having same vendorid,tpep_pickup_datetime , pulocationid, dolocationid
yugabyte-# DELETE FROM yellow_taxi_trips USING duplicates
WHERE yellow_taxi_trips.tpep_pickup_datetime = duplicates.tpep_pickup_datetime
AND yellow_taxi_trips.vendorid = duplicates.vendorid
AND yellow_taxi_trips.pulocationid = duplicates.pulocationid
AND yellow_taxi_trips.dolocationid = duplicates.dolocationid
AND duplicates.rn > 1;
DELETE 231880
#Insert cleansed records into yellow_taxi_trip_details table with right primary key (vendorid,tpep_pickup_datetime , pulocationid, dolocationid), it has 24.4Million records
INSERT INTO yellow_taxi_trips_detail
SELECT * FROM yellow_taxi_trips;
INSERT 0 24417553Import the data using \COPY command. This table forms the basis for our subsequent analysis.
Step 2: Establishing a Named Connection in ClickHouse
ClickHouse’s PostgreSQL table function allows you to access external PostgreSQL‑compatible databases like YugabyteDB. To simplify this process, create a named collection that stores your YugabyteDB connection details:
CREATE NAMED COLLECTION yellowtaxi AS host = '10.0.1.197', port = 5433, database = 'yugabyte', user = 'yugabyte', password = xxx; Output in clickhouse: CREATE NAMED COLLECTION yellowtaxi AS host = '10.0.1.197', port = 5433, database = 'yugabyte', user = 'yugabyte', password = 'xxx' Query id: ddc23fc8-d666-4652-910e-0edaec432abe Ok. 0 rows in set. Elapsed: 0.012 sec. :)
Using a named collection makes it easier to manage and reuse your connection parameters across multiple queries.
Step 3: Querying Detailed Data from YugabyteDB in ClickHouse
With the connection defined, you can pull the detailed taxi data into ClickHouse for analysis. For example:
SELECT * FROM postgresql(yellowtaxi, table='yellow_taxi_trips_detail'); Output in Clickhouse SELECT * FROM postgresql(yellowtaxi, table='yellow_taxi_trips_detail') limit 10; SELECT * FROM postgresql(yellowtaxi, `table` = 'yellow_taxi_trips_detail') LIMIT 10 Query id: 72add08c-5a89-4868-8638-9f3a77283dad Row 1: ────── vendorid: 2 tpep_pickup_datetime: 2020-03-06 17:01:03.000000 tpep_dropoff_datetime: 2020-03-06 17:03:57.000000 passenger_count: 1 trip_distance: 0.39 ratecodeid: 1 store_and_fwd_flag: N pulocationid: 79 dolocationid: 79 payment_type: 1 fare_amount: 4 extra: 1 mta_tax: 0.5 tip_amount: 1.66 tolls_amount: 0 improvement_surcharge: 0.3 total_amount: 9.96 congestion_surcharge: 2.5 Row 2: ────── vendorid: 2 tpep_pickup_datetime: 2020-08-26 13:23:55.000000 tpep_dropoff_datetime: 2020-08-26 13:31:55.000000 passenger_count: 1 trip_distance: 1.51 ratecodeid: 1 store_and_fwd_flag: N pulocationid: 162 dolocationid: 263 payment_type: 1 fare_amount: 7.5 extra: 0 mta_tax: 0.5 tip_amount: 2.16 tolls_amount: 0 improvement_surcharge: 0.3 total_amount: 12.96 .................
Step 4: Creating a Local Aggregated Table in ClickHouse
Next, create a ClickHouse table with the MergeTree engine to store aggregated data.
MergeTree is optimized for high‑performance analytical queries. For instance, create a table to hold daily taxi trip summaries:
CREATE TABLE taxi_summary ( trip_date Date, total_trips UInt64, total_fare Float64, total_tip Float64 ) ENGINE = MergeTree() ORDER BY trip_date;
This table is designed to store the aggregated daily summaries computed from the detailed Yellow Taxi data.
Step 5: Aggregating Data in ClickHouse
Aggregate the detailed data from YugabyteDB and insert the results into the local ClickHouse table. For example, calculate the total number of trips, total fare, and total tip amount per day:
INSERT INTO taxi_summary SELECT tpep_pickup_datetime AS trip_date, count(*) AS total_trips, sum(fare_amount) AS total_fare, sum(tip_amount) AS total_tip FROM postgresql(yellowtaxi, `table` = 'yellow_taxi_trips_detail') GROUP BY trip_date; Output: Query id: c9ad1213-541d-4404-aac2-39fa91c9d714 Ok. 0 rows in set. Elapsed: 48.234 sec. Processed 24.42 million rows, 634.86 MB (506.23 thousand rows/s., 13.16 MB/s.) Peak memory usage: 1.13 GiB. :)
This query leverages ClickHouse’s processing power to perform fast aggregations, storing the summarized results in taxi_summary.
Step 6: Sending Aggregated Data Back to YugabyteDB
To make the aggregated insights available for transactional systems or reporting in YugabyteDB, you can send the calculated data back using a linked table. First, create a corresponding summary table in YugabyteDB:
-- Execute on YugabyteDB: CREATE TABLE taxi_daily_summary ( trip_date DATE, total_trips BIGINT, total_fare DOUBLE PRECISION, total_tip DOUBLE PRECISION ); Output: yugabyte=# CREATE TABLE taxi_daily_summary ( trip_date DATE, total_trips BIGINT, total_fare DOUBLE PRECISION, total_tip DOUBLE PRECISION ); CREATE TABLE
Then, from ClickHouse, insert the aggregated data into the remote table using inline connection parameters:
INSERT INTO FUNCTION postgresql('10.0.1.197:5433', 'yugabyte', 'taxi_daily_summary', 'yugabyte', 'xxxxx') (trip_date, total_trips, total_fare, total_tip) SELECT
trip_date,
total_trips,
total_fare,
total_tip
FROM taxi_summary
Query id: 1b6db03d-4e48-4195-b218-03b678b4e3fa
Ok.
0 rows in set. Elapsed: 162.105 sec. Processed 11.75 million rows, 305.37 MB (72.45 thousand rows/s., 1.88 MB/s.)
Peak memory usage: 63.12 MiB.Output in YugabyteDB:
yugabyte=# select * from taxi_daily_summary limit 5; trip_date | total_trips | total_fare | total_tip ------------+-------------+------------+----------- 2020-12-18 | 2 | 17 | 5.86 2020-11-26 | 1 | 19.5 | 0 2020-03-10 | 4 | 46 | 5.01 2020-02-10 | 2 | 16.5 | 5.78 2020-11-11 | 2 | 33.5 | 10.59 (5 rows) yugabyte=#
This bi‑directional communication ensures that the latest aggregated insights are reflected in YugabyteDB for any further processing or visualization.
Points to Remember
- PostgreSQL Table Function in ClickHouse:
- This query directly fetches the data from YugabyteDB at the time of execution.
- There is no built-in replication or caching, so every time you run the query, it fetches the latest data.
Performance Factors:
- Query execution time: If the dataset is large, retrieval may take longer.
- Network latency: Since ClickHouse queries YugabyteDB live, it depends on how fast the network can fetch results.
- Indexing and optimization: Proper indexing in YugabyteDB can speed up query execution.
- How Quickly Is Aggregated Data Reflected in YugabyteDB?
- Using INSERT INTO PostgreSQL Table Function:
- Example: INSERT INTO TABLE FUNCTION postgresql(‘localhost:5433’, ‘yugabyte’, ‘taxi_daily_summary’, ‘yugabyte’, ‘yugabyte’)
SELECT * FROM taxi_summary- This operation immediately writes data to YugabyteDB.
- Once the insert is complete, the data is immediately available in YugabyteDB.Performance Factors:
- Write propagation and consistency model: YugabyteDB ensures strong consistency and linearizable writes across distributed nodes. While writes are fast, the time to persist and replicate the data can vary slightly depending on cluster size and replication settings.
- Network latency: If ClickHouse and YugabyteDB are running on separate servers or in different zones, network speed and bandwidth can impact data transfer time.
- Batch inserts: Performing bulk inserts instead of inserting row-by-row significantly improves performance, especially when sending large volumes of aggregated data.
Data Refresh Options
This table shows different options to refresh data between YugabyteDB and Clickhouse. The data refresh rate will vary depending on the methods that you choose.
| Direction | Method | Data Freshness | Notes |
| YugabyteDB → ClickHouse | Direct SELECT FROM postgresql(mypg, table='t1') | Real-time | Fetches fresh data on every query, but slower for large datasets. |
| YugabyteDB → ClickHouse | INSERT INTO MergeTree periodically | 5 seconds – few minutes | Requires scheduled job, but speeds up query performance. |
| ClickHouse → YugabyteDB | INSERT INTO TABLE FUNCTION postgresql() | Real-time | Writes immediately, limited by network and commit speed. |
| ClickHouse → YugabyteDB | Batch processing (ETL) | Few seconds – few minutes | Reduces network overhead, but updates less frequently. |
Conclusion
Integrating YugabyteDB and ClickHouse creates a modern, hybrid data architecture that leverages the best of both transactional and analytical worlds.
In our Yellow Taxi Data example, detailed trip data stored in YugabyteDB is immediately aggregated in ClickHouse and then sent back for further transactional use. This integration:
- Ensures real‑time data availability, allowing you to react swiftly to operational changes.
- Simplifies your data pipelines, reducing complexity and maintenance overhead.
- Enhances performance and scalability, optimizing resource utilization.
- Improves data consistency, leading to more reliable reporting and decision‑making.
Without this integration, organizations risk missing out on the efficiency, agility, and comprehensive insights that modern data-driven environments demand.
To find out more about innovations in YugabyteDB, check out our recent blog which details the latest PostgreSQL-compatible features available in YugabyteDB 2.25.
 from YugabyteDB CDC to ClickHouse")

