How to Architect a Robust Data Pipeline with Microsoft Fabric and YugabyteDB
September 16, 2024
In this blog, we will explore how to ingest data from YugabyteDB and process and store it in Microsoft Fabric Lakehouse using Microsoft Fabric’s Data Pipeline. Using the data pipeline feature, we will showcase both incremental and full data load to Lakehouse.
The Benefits of Integrating YugabyteDB and Microsoft Fabric
About Microsoft Fabric
Microsoft Fabric is a comprehensive platform designed to streamline data ingestion, processing, and analytics within an organization. From a data ingestion and pipeline perspective, it provides powerful tools to manage the end-to-end flow of data, from diverse sources to actionable insights.
Key Features:
- Data Ingestion: Microsoft Fabric supports both real-time and batch data ingestion from a variety of sources, including on-premises databases, cloud storage, IoT devices, and SaaS applications. This flexibility allows us to centralize data from multiple streams into a unified environment, ready for analysis.
- Data Pipelines: The platform offers advanced capabilities for designing and automating data pipelines. You can build workflows that manage the extraction, transformation, and loading (ETL/ELT) of data, ensuring it’s clean, enriched, and ready for use in analytics or business intelligence tools.
- Real-Time Processing: Fabric integrates with tools like Azure Stream Analytics, enabling real-time data processing. This is crucial for applications that require immediate insights, such as monitoring, operational intelligence, and real-time decision-making.
- Scalability and Resilience: Microsoft Fabric is built to handle large-scale data operations, automatically scaling resources based on workload demand. It also incorporates fault-tolerance features, ensuring that your data pipelines remain operational even in the event of failures.
- Automation and Monitoring: You can automate your data workflows end-to-end, with tools for scheduling, triggering, and monitoring pipelines. Fabric provides robust monitoring and alerting capabilities, allowing you to maintain the health and performance of your data processes.
About YugabyteDB
YugabyteDB is a high-performance, distributed SQL database designed for cloud-native applications. It combines the benefits of SQL’s relational model with the scalability and resilience of a distributed database. This makes it ideal for modern applications that require global data distribution, high availability, and strong consistency. Built on top of a highly scalable architecture, YugabyteDB can handle large amounts of data and high transaction volumes across multiple regions, all while maintaining low-latency access to data.
Key features:
- Multi-Cloud: Seamlessly operate across public, private, and hybrid clouds to ensure flexibility and avoid vendor lock-in
- Geo-Distribution: Globally distribute data using flexible design patterns that support synchronous or asynchronous replication
- Multi-API: Select a familiar PostgreSQL API or an enhanced Cassandra-inspired API
- Connection Management: Boost connection creation and support more connections with built-in connection pooling
- Observability: Real-time access to consolidated monitoring and alerts for database clusters on any cloud
- Native Security: Secure your data with end-to-end encryption, advanced authentication, and a security-first design
The Value of Integrating YugabyteDB and Microsoft Fabric
- YugabyteDB and Microsoft Fabric allow businesses to maintain the integrity and consistency of their transactional data while taking advantage of Fabric’s data processing and analytics capabilities. This integration can streamline data pipelines, ensuring that data flows smoothly from transactional systems to analytical platforms.
- Comprehensive HTAP solution: YugabyteDB handles the transactional data efficiently, while Microsoft Fabric can be used to offload and analyze this data. This provides advanced analytics and insights without affecting the performance of the transactional system
- This integration is critical for applications that require immediate insights from live transactional data, such as fraud detection, customer behavior analysis, and operational monitoring.
- Leverage the data lakehouse capabilities of Fabric to store, process, and analyze large datasets that originate from YugabyteDB transactions. This enables advanced analytics, machine learning, and AI workloads on data that is both current and historical.
- Optimize costs by efficiently utilizing both platforms. For example, transactional data can be processed in YugabyteDB and only moved to Microsoft Fabric for more resource-intensive analytical processing, avoiding unnecessary costs.
Key Use Cases
Integrating Microsoft Fabric with YugabyteDB CDC and incremental pulling offers a power-packed, end-to-end data intelligence platform that is unparalleled in its ability to handle complex, real-time business challenges.
This solution not only empowers businesses to make smarter, faster decisions but also drives innovation and competitive advantage. By leveraging the combined strengths of Fabric Lakehouse, Fabric Pipelines, data science capabilities, and the Real-Time Hub, organizations can transform their operations, delivering exceptional value and results in a rapidly changing market. The following use case examples illustrate the capabilities offered
Near Real-Time Credit Risk Management and Loan Approval
Challenge:
Lending institutions need to assess credit risk quickly and accurately to offer loans competitively while managing risk. Traditional methods often rely on outdated data, leading to either overly conservative lending or increased risk of default.
Solution:
By leveraging a pipeline with incremental pull from YugabyteDB into Microsoft Fabric, lenders can transform their credit risk management processes:
- Near Real-Time Data Integration: Financial data, including credit scores, income verification, spending patterns, and economic indicators, are captured in YugabyteDB and incrementally pulled into Fabric’s Lakehouse.
- Credit Risk Analysis: Fabric Pipelines process this data and feed it into machine learning models within the Fabric data science environment. These models evaluate creditworthiness based on both historical data and real-time changes, such as sudden income loss or market volatility.
- Instant Loan Decisions: The Real-Time Hub delivers immediate credit risk assessments, allowing loan officers to make instant approval or rejection decisions. This speeds up the loan approval process and ensures that decisions are based on the most current data.
- Dynamic Interest Rates: Depending on the real-time assessment, the system can adjust interest rates dynamically, offering competitive pricing while managing risk.
Business Impact:
- Faster Loan Approval: Real-time credit risk assessment speeds up the loan approval process, improving customer satisfaction and increasing conversion rates.
- Accurate Risk Management: Dynamic risk assessment ensures that loans are offered with an appropriate risk buffer, reducing defaults.
- Competitive Edge: The ability to offer instant loan decisions with dynamic pricing provides a significant competitive advantage in the lending market.
Real-Time Environmental Monitoring and Compliance
Challenge:
Oil and gas operations have a significant impact on the environment and companies must comply with strict regulations to minimize this. Real-time monitoring is essential to ensure compliance and prevent environmental incidents.
Solution:
Integrating a pipeline with incremental pull from YugabyteDB into Microsoft Fabric allows for real-time environmental monitoring:
- Data Collection: Environmental data, including air and water quality measurements, emissions levels, and waste disposal records, is captured in YugabyteDB and incrementally pulled into the Fabric Lakehouse.
- Compliance Monitoring: Fabric Pipelines process this data and compare it against regulatory standards, identifying any areas of non-compliance in real-time.
- Incident Response: The Real-Time Hub alerts environmental teams to any breaches in compliance, enabling immediate corrective actions to prevent environmental incidents.
- Sustainability Reporting: The system also supports sustainability initiatives by providing detailed Power BI reports on environmental performance, helping companies demonstrate their commitment to environmental stewardship.
Business Impact:
- Regulatory Compliance: Real-time monitoring ensures continuous compliance with environmental regulations, avoiding fines and legal issues.
- Risk Mitigation: Proactive incident response reduces the likelihood of environmental accidents, protecting the environment, and the company’s reputation.
- Sustainability Leadership: By enhancing environmental performance, companies can position themselves as leaders in sustainability, gaining a competitive edge in the market.
How to Integrate YugabyteDB With Microsoft Fabric Lakehouse Using Fabric’s Data Pipeline Feature
The data integration flow below shows the integration between YugabyteDB and the Microsoft Fabric ecosystem.
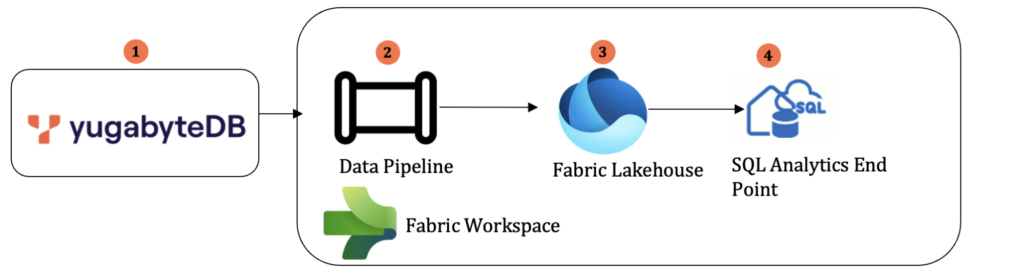
This architecture integrates YugabyteDB with Microsoft Fabric using a PostgreSQL connection.
The Fabric Data Pipeline facilitates incremental data loading from YugabyteDB to the Fabric Lakehouse, a unified platform for storing and analyzing both structured and unstructured data. Within the Lakehouse, Delta tables allow efficient querying using T-SQL, while the Fabric Semantic Data Model provides a business-friendly layer for deeper analysis.
This setup ensures seamless data flow, centralized storage, and robust analytics capabilities, enabling effective data-driven decision-making.
| Data flow seq# | Operations/Tasks | Component Involved |
|---|---|---|
| 1 | YugabyteDB is connected through the PostgreSQL connection type. | YugabyteDB |
| 2 | The Data Pipeline helps copy the data from YugabyteDB to Lakehouse incrementally | Fabric Data Pipeline |
| 3 | Fabric Lakehouse is the data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. | Fabric Lakehouse |
| 4 | Lakehouse provides the capability to analyze data in Delta tables using T-SQL language, save functions, generate views, and apply SQL security. | Fabric Lakehouse SQL Analytics End Point |
Prerequisites:
- Get your Fabric Account set up in Azure.
- Follow the instructions mentioned on this link.
Connection Establishment
YugabyteDB is connected to Microsoft Fabric via a PostgreSQL connection type, enabling seamless data flow between the two systems. YugabyteDB serves as the primary source database, where transactional data is stored and managed.
- Create a Data pipeline from your Microsoft Fabric Workspace

- Create Copy data using copy activity from the Data Pipeline wizard Click the source as shown above. Look for a PostgreSQL connection and enter the credentials and connection details mentioned in the below diagrams. Once the connection is established from Fabric, you can see the source connection and connection filled automatically. Note: as YugabyteDB is outside of the Azure Ecosystem, it needs to be connected with an on-premises data gateway which has to be installed from a Windows VM/Windows Client Machine, the detailed instructions are mentioned HERE.
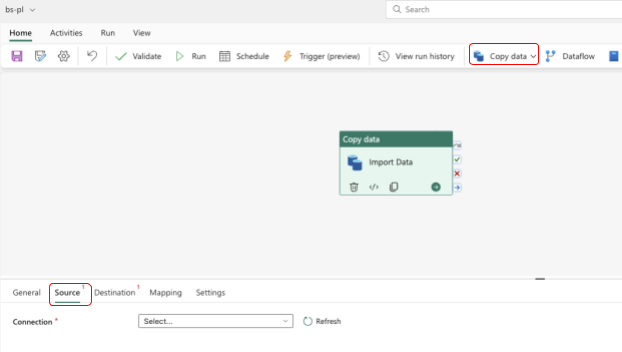
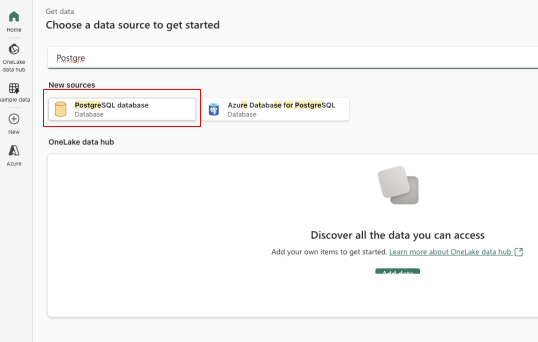
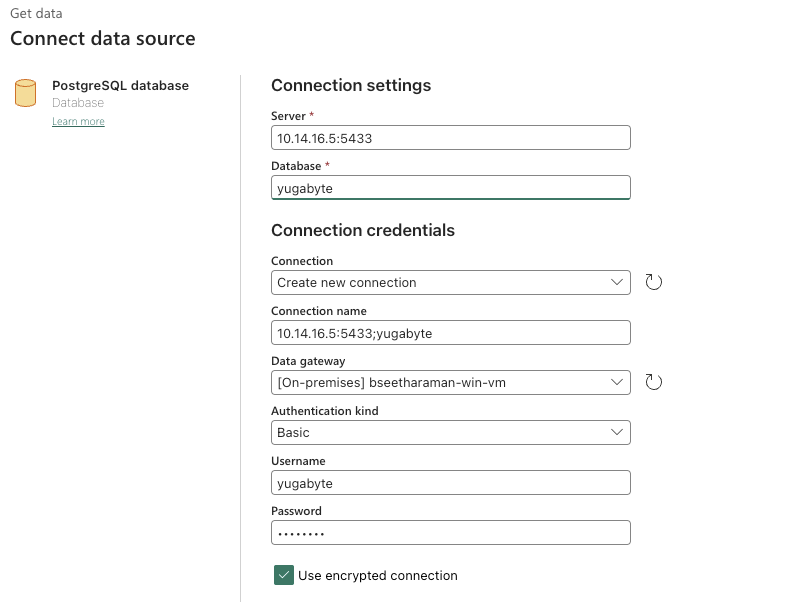 Once the connection is established from Fabric, you can see the source connection and connection filled automatically.
Once the connection is established from Fabric, you can see the source connection and connection filled automatically. 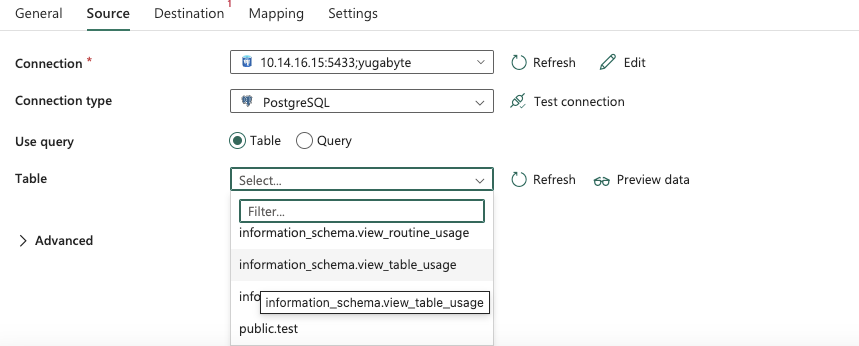 Note: as YugabyteDB is outside of the Azure Ecosystem, it needs to be connected with an on-premises data gateway which has to be installed from a Windows VM/Windows Client Machine, the detailed instructions are mentioned
Note: as YugabyteDB is outside of the Azure Ecosystem, it needs to be connected with an on-premises data gateway which has to be installed from a Windows VM/Windows Client Machine, the detailed instructions are mentioned Fabric Data Pipeline
The Fabric Data Pipeline plays a crucial role in copying data from YugabyteDB to the Fabric Lakehouse incrementally. This pipeline ensures that the data is transferred efficiently, maintaining synchronization between the source (YugabyteDB) and the destination (Lakehouse) without needing to repeatedly move the entire dataset.
Incremental Data Loading
Incremental data loading involves loading only the new data that has been added or updated since the last load. This is typically based on a timestamp or an incremental identifier (e.g., auto-incremented primary key).
Data Pipeline
The diagram below shows the data pipeline that we created in Fabric’s data engineering section to ingest the data incrementally from YugabyteDB to Fabric Lakehouse. This can be scheduled and monitored. Click HERE for further details. 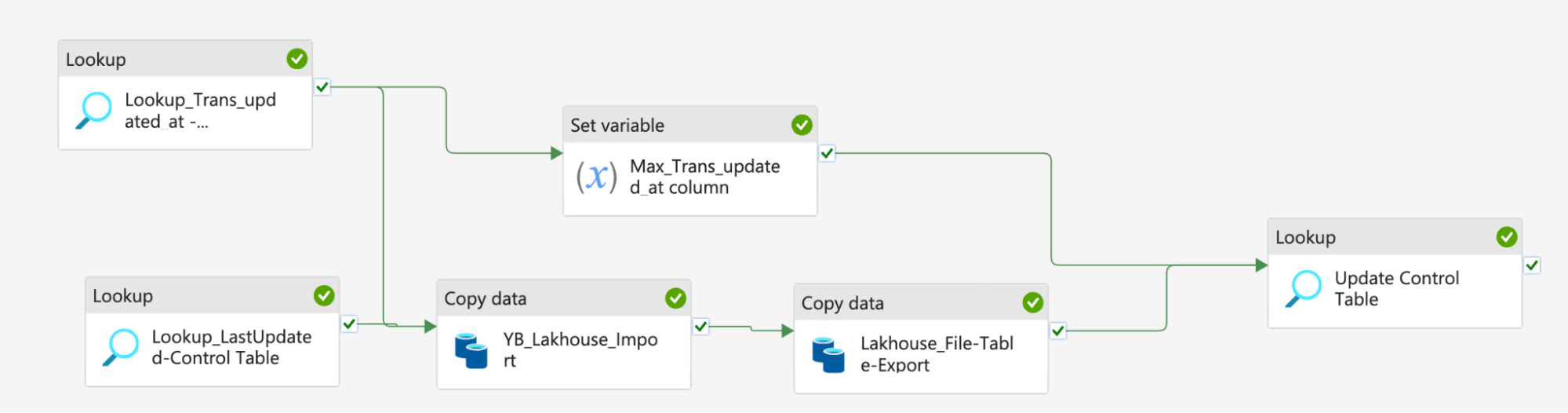
Here we detail the step-by-step activities involved in this pipeline.
- Lookup Activity(Lookup_LastUpdated-Control Table) – We have used
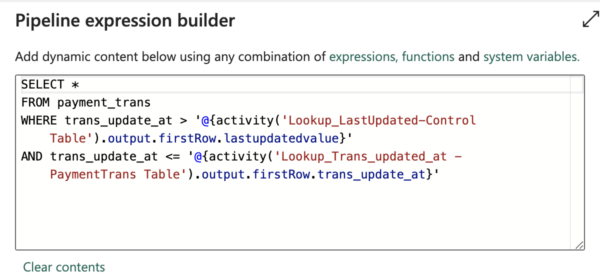
pipeline_table_configto control the incremental import from the YugabyteDB table - Lookup Activity(Lookup_Trans_updated_at – PaymentTrans Table) – From the above steps, we have identified the incremental column
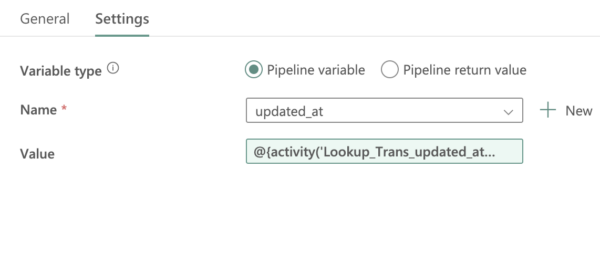
trans_update_atof one of thepayment_transtables. - We have used a session variable
“updated_at”for the Fabric Data Pipeline to set it with the Max value of thetrans_update_atfrom thepayment_transtable. This helps to update the control table pipeline_table_config after the import task is completed successfully. Value Used for updated_at (variable) - Import Data – Using copy task we will be importing data from YugabyteDB to Microsoft Fabric Lakehouse (Folder) as shown below. The source database is YugabyteDB, which is running in 10.14.16.15. The query tab shows the logic that we used to build the incremental import. Expansion of the above query (i.e. select * from payment_trans….)
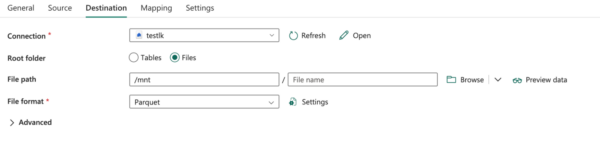
- Import Table – Using the copy task we will be importing data from a Lakehouse folder to a Fabric Lakehouse table. It can be configured either to be appended/overwritten to the table from files.
- Update the Control Table: we will be updating the pipeline control table (pipeline_table_confg), the lastupdatedvalue will be updated with pipeline variable captures the max. Transaction date of payments table.

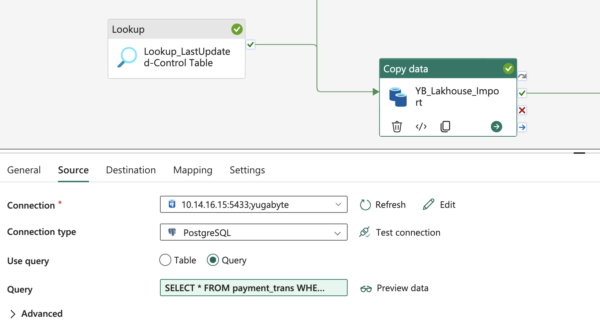
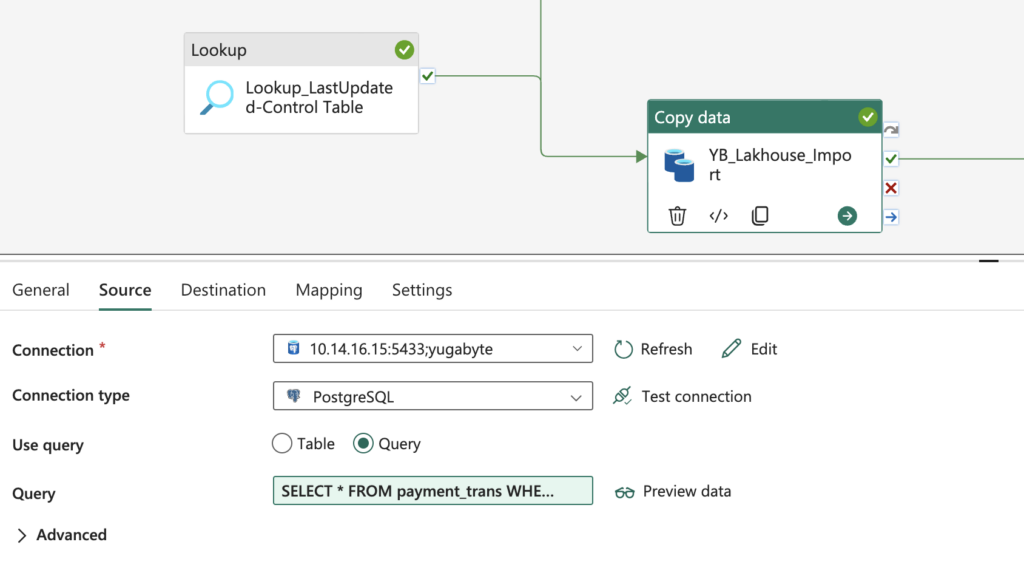

The below diagram shows the pipeline execution with the status of all the activities: 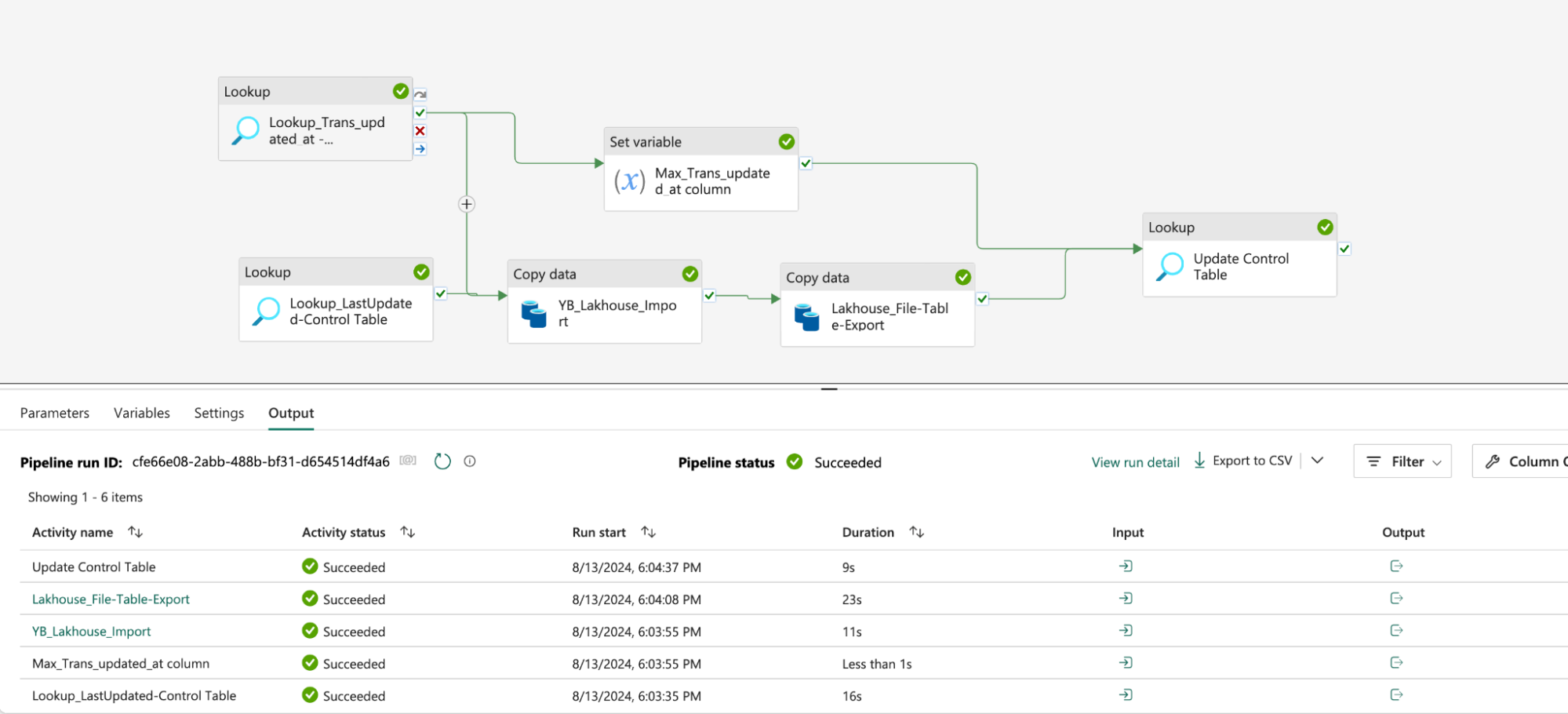
Fabric Lakehouse
The Microsoft Fabric Lakehouse is a unified data platform that combines the scalability of data lakes with the performance of data warehouses, enabling real-time analytics and advanced data management. It integrates seamlessly with Azure services and supports both structured and unstructured data, making it ideal for modern data-driven organizations.
The output of the above pipeline uses this destination Folder in Lakehouse – Here testlk is the Lakehouse Name and it is mounted under /mnt directory as mentioned in file path (above destination details diagram) 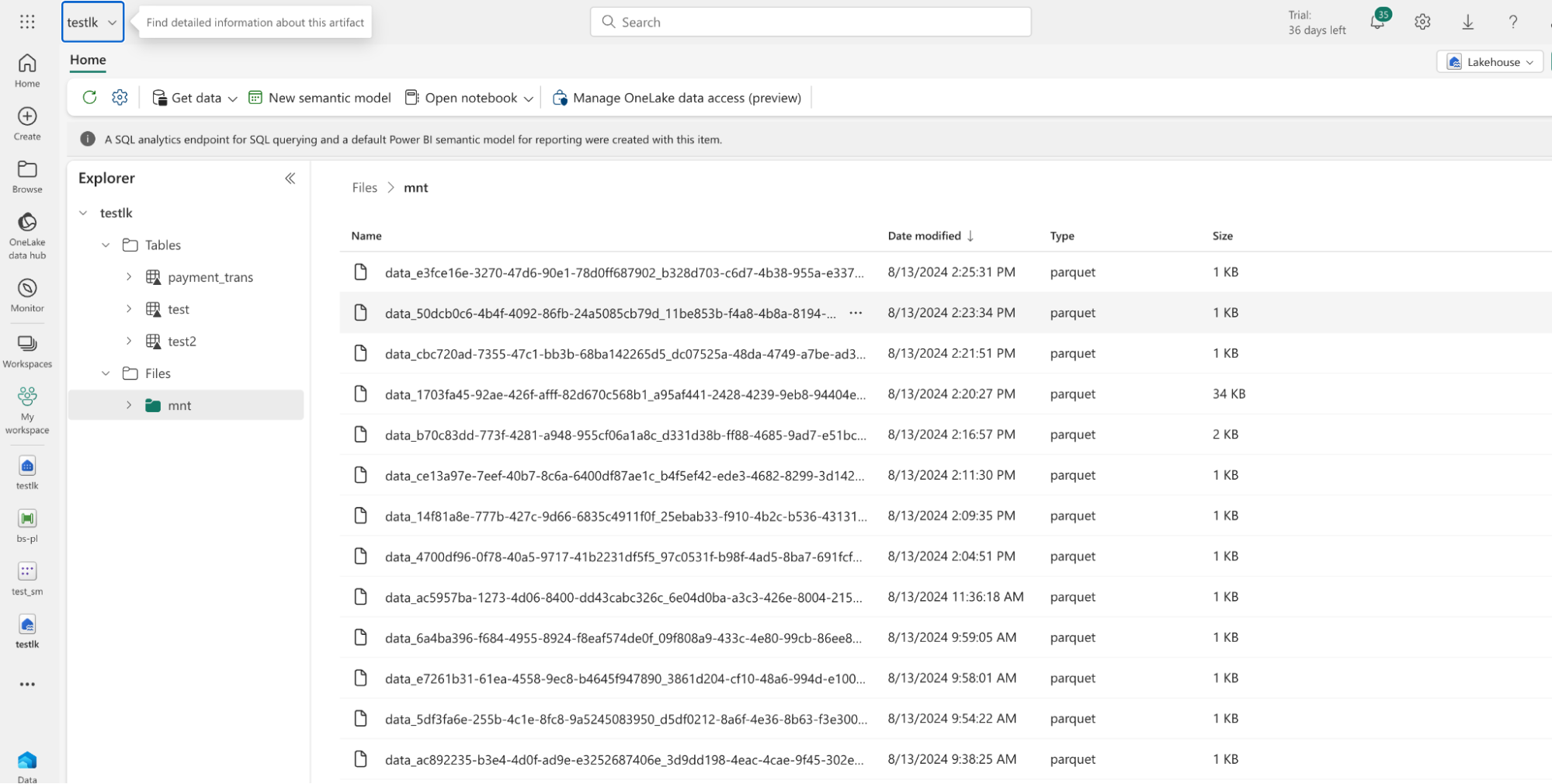
Lakehouse SQL Analytics End Point
Lakehouse SQL Analytics End point offers a powerful and efficient way to query and analyze data stored in a lakehouse, providing the flexibility of a data lake with the performance of a data warehouse. This combination enables organizations to derive insights from their data more quickly and cost-effectively while maintaining robust data governance and scalability.
An SQL analytics endpoint is automatically created for every Lakehouse. To get a SQL analytics endpoint, create a lakehouse and a SQL analytics endpoint will be automatically created for the Lakehouse.
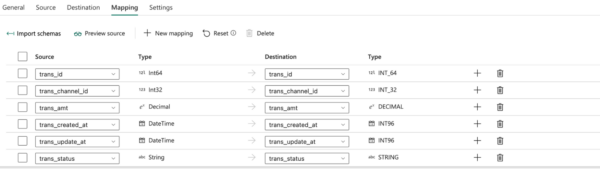
The below screenshot shows the payment_trans table that we ingested using the data pipeline in Lakehouse.
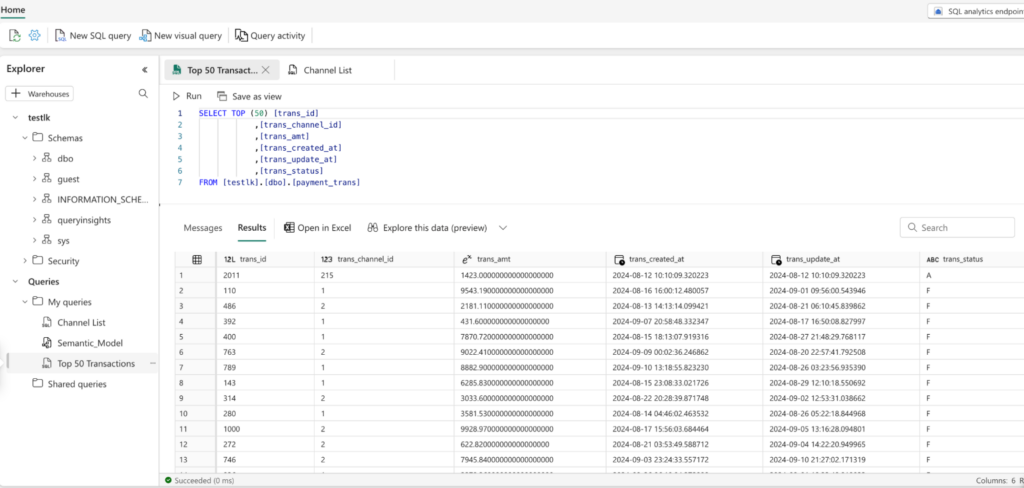
Conclusion
Integrating Microsoft Fabric Data Pipelines with YugabyteDB using incremental data loading is an efficient and scalable solution for managing large datasets.
By leveraging incremental updates, you can optimize data processing, reduce latency, and ensure your data pipeline remains responsive to real-time changes. This approach enhances performance and streamlines your data workflows, making it easier to maintain and scale our data infrastructure as the needs of the business grow.
Successful implementation underscores the value of combining robust data engineering tools with a powerful distributed database like YugabyteDB.


