Distributed Backups in Multi-Region YugabyteDB Clusters
November 19, 2018
Our post Getting Started with Distributed Backups in YugabyteDB details the core architecture powering distributed backups in YugabyteDB. It also highlights a few backup/restore operations in a single region, multi-AZ cluster. In this post, we perform distributed backups in a multi-region YugabyteDB cluster and verify that we achieve performance characteristics similar to those observed in a single region cluster.
We configured a 9 node cluster with 3 availability zones across 2 regions and repeated the benchmark introduced in the post. However, instead of loading data till 3.6 TB, we stopped at the 2 TB (230 GB/node) mark and initiated our backup.
Configure a backup store
YugabyteDB can be configured to have an Amazon S3 or an NFS endpoint as a backup store. In our example, we use an S3 bucket that’s been configured for the us-east-1 region (one of the regions where our YugabyteDB cluster will be created). Note that this backup store is now available to all clusters managed using the same YugabyteDB Enterprise Admin Console.
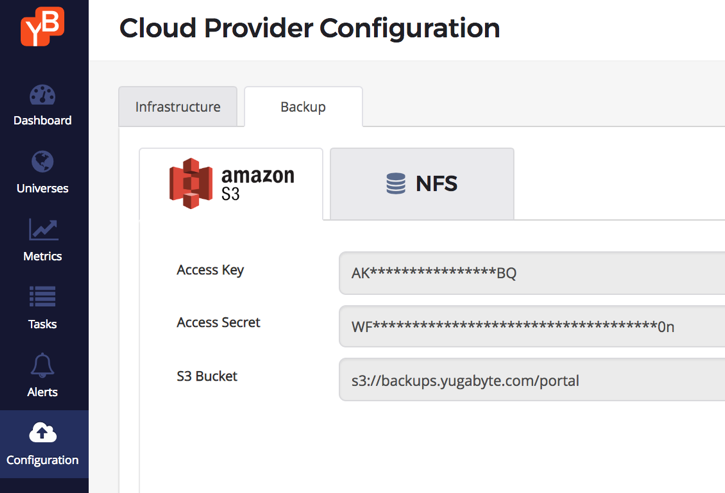
Create a source cluster
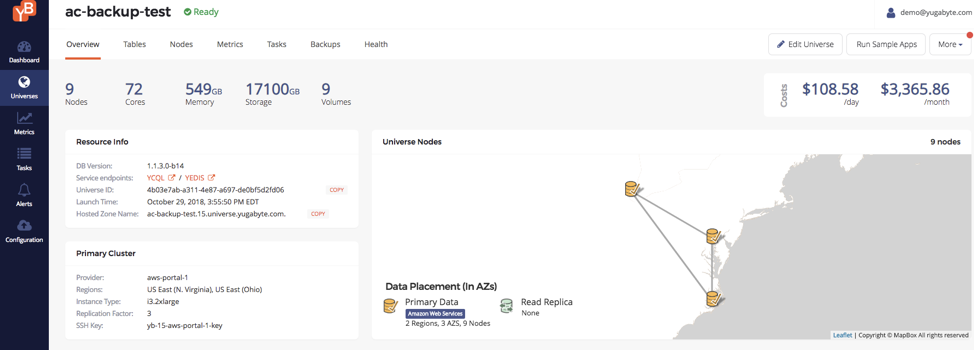
- Source Cluster Size: 9 nodes in AWS (ac-backup-test)
- Region: us-east1-e (Northern VA), us-east1-f (Northern VA), us-east2-b (Ohio)
- Node Type: i3.2xlarge (8-vcpus, 61 GB RAM, 1 x 1.9TB nvme SSD per node)
- Replication Factor: 3
- Latency time: 11ms (measured by ping between us-east1 and us-east2)
- Final Dataset: 2 TB data set across 9 nodes (about 230 GB per node)
- Key + Value Size: ~300 Bytes
- Key size: 50 Bytes
- Value size: 256 Bytes (deliberately chosen to be not very compressible)
- Final Logical Data Set Size: 2 Billion keys * 300 Bytes = 600 GB
- Final Expected Data Per Node: 2 TB / 9 = 230 GB
All other data parameters were unchanged other than the total number of records written.
Initialize a read-intensive workload
Once we loaded 2 billion records into the cluster, we ran the following read intensive workload.
$ java -jar yb-sample-apps.jar -workload CassandraKeyValue --nouuid --nodes $CIP_ADDR --value_size 256 --max_written_key 1999999999 -num_threads_write 8 --num_threads_read 128
Backup during the read-intensive workload with 2 TB data

At this stage, each node had about ~230GB of data. This meant that the total compressed on-disk data set was about 2 TB. Note that there is a “dead node” in the table below. This was actually done as a rebalance from 8 to 9 nodes and shifting load from 1 availability zone to another during the load period.

Impact of the backup on the workload
This backup ran from 10:39 AM to 11:39 AM, completing in 1 hour. During this time, we did not note any degradation in the user experience in terms of operations throughput. There was only a small spike in latency from 1.5ms to 2.2ms (on write operations) when the checkpoint was being taken at the start of the backup.
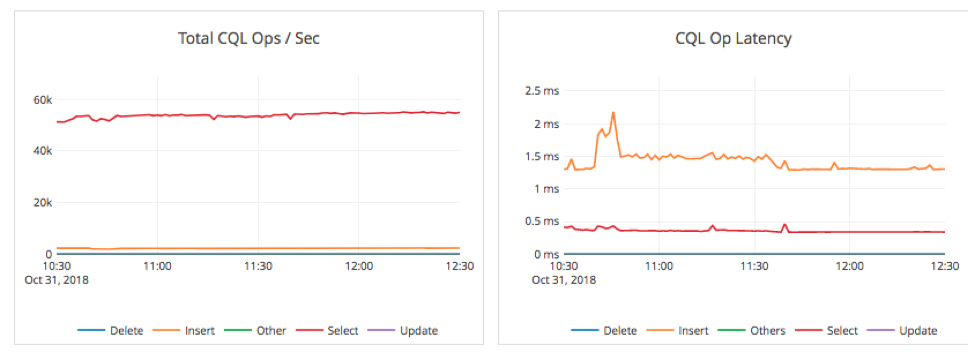
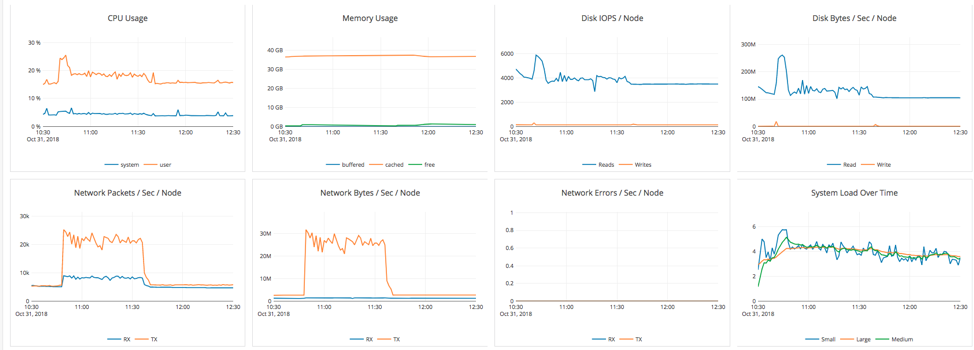
The stats above show the cluster performance during the backup. We notice an increase in CPU utilization during the backup, as well as increased IOPS and network traffic as the data files are being copied to S3. We can safely conclude from this test that there was no impact to operations from having a remote data center with a full copy of the data and executing a backup operation.
Summary
Distributed backups in YugabyteDB perform efficiently irrespective of whether the cluster is running in a single region or multi-region deployment. This is because backups are designed to copy data from only the shard leaders using LSM storage engine checkpoints without involving any of replicas at any time. This is an important design choice since replicas may be present in different regions in multi-region clusters and hence can introduce significant higher latencies in the backup process.
What’s Next?
- Read our post on how to get started with distributed backups in YugabyteDB.
- Install a local YugabyteDB cluster in minutes!
- Compare YugabyteDB to databases like Amazon DynamoDB, Apache Cassandra, MongoDB and Azure Cosmos DB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.
 Scenarios and the Multi-Tenancy Options That Support Them")

