Distributed SQL Tips and Tricks – Feb 7, 2020
February 7, 2020
Welcome to this week’s tips and tricks blog where we recap some distributed SQL questions from around the Internet. We’ll also review upcoming events, new documentation and blogs that have been published since the last post. Got questions? Make sure to ask them on our YugabyteDB Slack channel, Forum, GitHub or Stackoverflow. Ok, let’s dive right in:
Does YugabyteDB have an in-memory storage engine?
Because YugabyteDB is a distributed SQL database with strong consistency, continuous availability and long-term data persistence as fundamental design principles, having an in-memory storage engine wouldn’t align with the use cases YugabyteDB aims to serve. That being said, YugabyteDB leverages an in-memory block cache that delivers very good read performance (sub-millisecond latencies) even when the data set doesn’t fit entirely in RAM.
To learn more about YugabyteDB’s architecture and the various performance optimizations we’ve made to our storage layer, check out:
- “Extending RocksDB for Speed & Scale”, which describes some of this work done on YugabyteDB’s storage engine, DocDB, which is based on RocksDB.
- “Achieving Sub-ms Latencies on Large Datasets in Public Clouds”, which describes performance of random read workloads in public clouds where the entire data set does not fit in RAM.
What multi-region deployment options does YugabyteDB support?
YugabyteDB is a geo-distributed SQL database that can be easily deployed across multiple datacenters or cloud regions. There are two primary configurations for multi-DC deployments.
The first configuration uses a single cluster deployed across 3 or more data centers with data automatically sharded across all data centers. Replication across these data centers is synchronous and based on the Raft consensus protocol. This means writes are globally consistent and reads are either globally consistent or timeline consistent (when application clients use follower reads). Additionally, resilience against data center failures is fully automatic. This configuration does the potential to incur Wide Area Network (WAN) latency in the write path if the data centers are geographically located far apart from each other and are connected through the shared or unreliable Internet.
If your use case allows for it, this WAN latency can be eliminated altogether by deploying two or more independent, single-DC clusters which are connected through asynchronous replication based on Change Data Capture.
Does the YSQL API adhere to PostgreSQL’s error codes ?
YugabyteDB reuses the PostgreSQL’s upper half, and in almost all cases, the error codes are identical. Language layer error codes like syntax, semantic and even run-time errors like “duplicate primary key” and “divide by zero” will be reported as expected. In the cases of transaction related operations, conflicts or YugabyteDB system specific errors which do not have a functional equivalent in PostgreSQL, you can expect YugabyteDB specific error codes to be returned.
How long does YugabyteDB take to auto-recover from failures?
YugabyteDB is a consistent, high-performance and highly available database, in which tables are sharded into tablets, and tablets are replicated amongst nodes using the Raft distributed consensus protocol. Raft is also used to elect, for each tablet, one of the tablet’s peers as the leader.
In a typical deployment, a node will have many tablets, some of these will be “followers” and others “leaders”. If a node fails, tablets for which this node was the leader will experience a small amount of unavailability until new leaders are elected for those tablets. This leader (re)election is triggered when the followers of a tablet have not heard from their leader for a certain number of heartbeats.
If a follower doesn’t hear within 6 heartbeats from the leader, i.e. about 3 seconds, new leaders will get elected. The default heartbeat interval in YugabyteDB is 500ms.
It is possible to override these settings to reduce the failover time. However, care must be exercised as to not make this interval too aggressive, as that can cause leaders to unnecessarily ping/pong even for small network hiccups.
How can I view YugabyteDB tables in JetBrains DataGrip?
JetBrains DataGrip is a popular database visualization tool that works with multiple databases including PostgreSQL. However, using DataGrip’s PostgreSQL’s connection with YSQL leads to errors like the following:
[0A000] org.postgresql.util.PSQLException: ERROR: System column with id -3 is not supported yet. ERROR: System column with id -3 is not supported yet
The above error makes sense in the context of YSQL. DataGrip’s PostgreSQL connector is querying PostgreSQL’s system columns such as xmin, xmax, cmin, cmax, ctid for the above functionality. However, YSQL does not use these system columns given that these functions are handled by the DocDB storage engine of YugabyteDB. As documented in this JetBrains forum post, the solution here is to make DataGrip’s PostgreSQL connector use standard JDBC metadata as opposed to PostgreSQL specific metadata. All that needs to be done is to check the “Introspect using JDBC metadata” option as shown below.
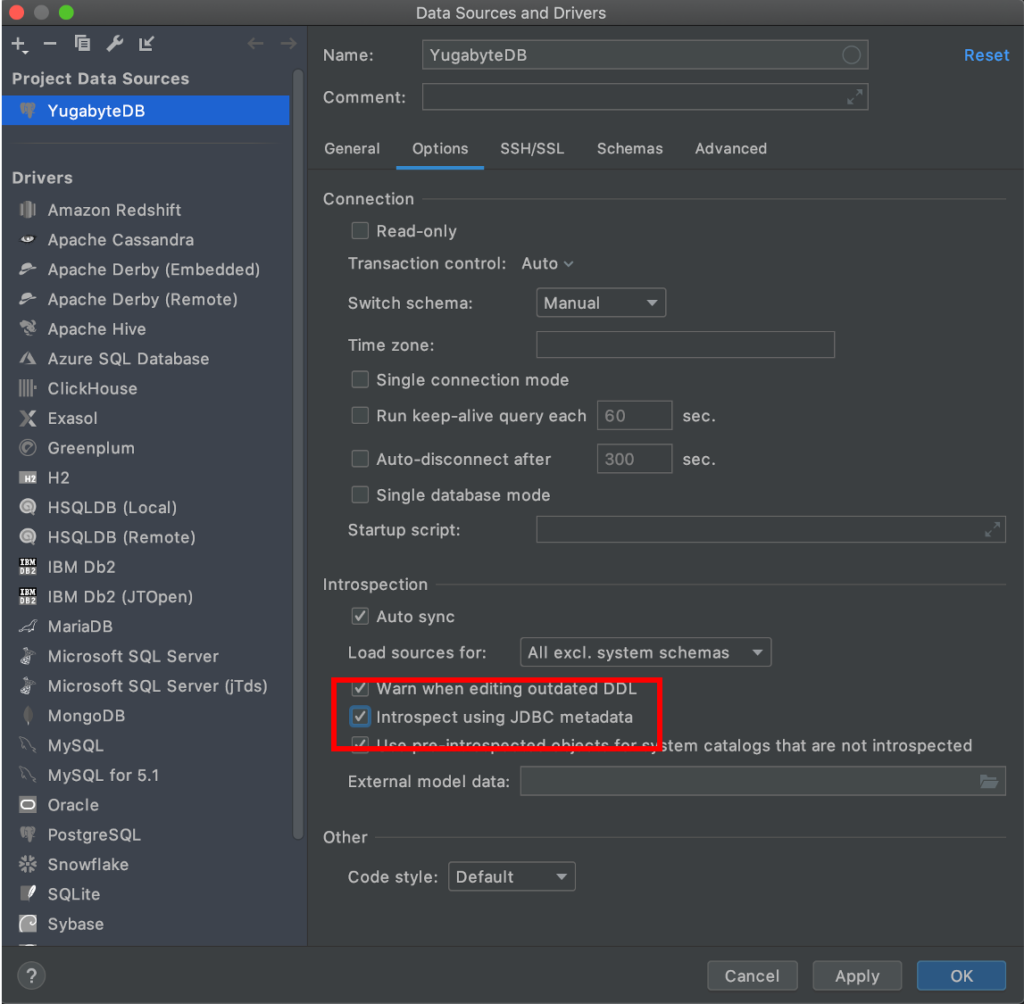
Once connected you can administer and browse YugabyteDB data using DataGrip just as if it was supported natively.
New Documentation, Blogs, Tutorials, and Videos
New Blogs
- YugabyteDB Engineering Update – Jan 29, 2020
- Distributed SQL vs. NewSQL
- How to Migrate the Sakila Database from MongoDB to Distributed SQL with Studio 3T
- Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database
New Videos
- Developing Microservices with the Google Hipster Demo, Istio and a Distributed SQL Database
- Developing Cloud-Native Spring Microservices with a Distributed SQL Backend
- How to Upgrade a Local YugabyteDB Cluster
- YugabyteDB Operational Best Practices
New and Updated Docs
- yb-ts-cli (a command line tool that can be used to perform an operation on a particular tablet server)
- Server-server encryption (updates to support YSQL)
Upcoming Meetups and Conferences
PostgreSQL Meetups
- Feb 20: Silicon Valley PostgreSQL Meetup
Distributed SQL Webinars
Conferences
- Postgres Conference, March 23-27, 2020, New York
- KubeCon + CloudNativeCon Europe, March 30 – April 2, 2020, Amsterdam
- Google Cloud Next, April 6-8, 2020, San Francisco
- Red Hat Summit, April 27-29, 2020, San Francisco
Get Started
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


