Distributed SQL Tips and Tricks – December 16th, 2021
December 16, 2021
Welcome back to our tips and tricks blog series! I have the distinct pleasure of recapping distributed SQL questions from around the Internet for the month of December.
This ongoing series would not be possible without Dorian Hoxha, Franck Pachot, and Frits Hoogland. We also thank our incredible user community for their work with the technology.
Do you have any questions? Ask them on our YugabyteDB Slack channel, Forum, GitHub, or Stack Overflow. For previous Tips & Tricks posts, check out our archives. Now let’s dive in!
Can I control tablet placement on a regional basis?
Short answer: yes. YugabyteDB offers multi-zone and multi-region deployment commands using the yb-admin CLI. For example, a 3-node cluster with a node in each region uses these commands. You would then set a preferred region, where your tablet leaders would sit. Specifically, tablet leaders are the main tablets (i.e., shards) responsible for handling all reads and writes for that particular set of data.
The command modify_placement_info modifies the placement information (based on cloud.region.zone) for your cluster deployment. This allows you to specify a cloud provider, a region within that cloud provider, and an availability zone (AZ) within that region for your node placement. Next, you would set the preferred AZs and regions using the set_preferred_zones command. This ensures that the tablet leaders are on nodes within those zones and regions.
What about low latency writes to application users?
We have seen users utilize this type of configuration for low latency writes to application users in the preferred region. In this case, the other regions in the cluster are there for redundancy. However, users have set up follower reads on the remote nodes. The use case allows you to give up some consistency (i.e., eventually consistent) for lower read latency within those remote regions. When you have made the necessary changes to set your preferred leaders, you can verify this by running the following command:
curl -s https://<any-master-ip>:7000/cluster-config?raw
In the cluster configuration you should now see affinitized_leaders added at the bottom. This calls out the preferred zones set.
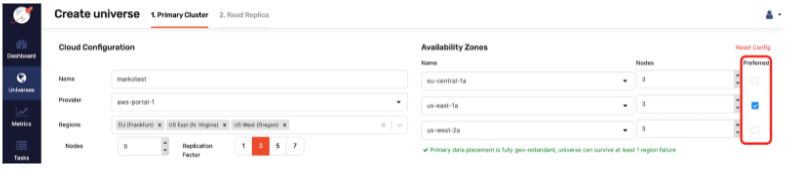
Be aware: if you are using the yb-tserver binary (used when launching individual tservers) to set the placement, you will need to set --placement_cloud=cloudX and --placement_zone=rackX arguments. In addition, you will need to set --placement_region=regionX to your yb-tserver processes (upon starting up a tserver) to match what you passed to modify_placement_info. Using Yugabyte Platform, you can select a preferred leader from the UI during the cluster creation process, as shown in the screenshot below.
Do insert/update queries on YCQL tables ensure ACID properties?
YugabyteDB supports ACID transactions for both APIs, YCQL, and YSQL, as a part of our core design goals. This includes single-row linearizable writes, as well as multi-row ACID transactions. Linearizability is one of the strongest single-row consistency models. Every operation takes place atomically and is consistent with the real-time ordering of those operations.
For multi-row transactions, YugabyteDB supports two isolation levels: Serializable and Snapshot Isolation (mapped to “repeatable read” in PostgreSQL). Note that for YCQL only Snapshot Isolation is supported at this time. In order to participate in multi-shard distributed transactions you must set the transactions property transactions={'enabled': true } on your table definition. Otherwise, the table will only have transactional guarantees for single shard transactions.
I can create a table in the read replica (RR) node with YSQL, should that really be possible?
With YugabyteDB, you can create a read replica as a part of your universe. It can be a separate cluster located in a different region. It can also be closer to the consumers of the data. The latter option results in lower-latency access and enhanced support of analytics workloads. Since the replica is read only, users expect any type of DDL or writes to fail. But this is not the case. Any DDL and writes reroute to the primary cluster rather than ignored or errored out to the user.
For those who want to try this out with YSQL, first enable YSQL follower reads on the cluster. From there, you can query the read replica locally and observe the differences in reads. You can also view the re-routing of any DDLs and writes as described above. This functionality is best suited for applications with old or static data.
In this case, the cost of reaching out to a remote leader tablet to fetch the data may be wasteful. That means reading from a follower tablet will help lower latency. In particular, there are two session variables that control the behavior of follower reads:
yb_read_from_followerscontrols whether reading from followers is enabled where the default value is false.yb_follower_read_staleness_mssets the maximum allowable staleness. The default here is 30000 (30 seconds).
New Documentation, Blogs, and Tutorials
Outside of the Yugabyte blogs called out below, check out our Yugabyte DEV Community Blogs here.
- Getting Started with YugabyteDB, Temporal, and the Temporal-Maru Benchmarking Tool
- How Kroger’s Data Architecture Powers Omnichannel Retail Experiences at Scale
- Using GIN Indexes in YugabyteDB
- Why Yugabyte is a Great Choice for Growing Your Engineering Career
- Announcing YugabyteDB 2.11: The World’s Most PostgreSQL-Compatible Distributed SQL Database
- Is Your Distributed Database PostgreSQL Compatible, and Why Does This Matter?
- Distributed SQL Essentials: Sharding and Partitioning in YugabyteDB
- Alerts and Notifications in Yugabyte Platform
- Yugabyte Platform API: Securely Deploying YugabyteDB Clusters Using Infrastructure-as-Code
- Announcing YugabyteDB 2.8
- How my Yugabyte Internship Changed Me For the Better
New Videos
- Is it Too Soon to Put the Data Layer in Kubernetes?
- GraphQL Workshop: Getting Started with Distributed SQL and Popular GraphQL Servers
- YugabyteDB: An Immersive Indulgence on Distributed SQL
- Evaluating PostgreSQL Compatibility
- Migrate a Workload from MySQL to YugabyteDB Using pgloader (OSS)
- Distributed SQL & YugabyteDB Fundamentals
- Distributed SQL Summit 2021 – all videos!
Upcoming Events
- NRF 2022 – January 16, 2022 12:00am – January 18, 2022 11:59pm (PT) • Conference • New York City, USA
- PostgreConf Silicon Valley 2022 – January 20 – 21, 2022 • Conference • San Jose, USA
- Is 2022 “The Year of the Edge?” – January 27, 2022, 8:00am – 9:00am (PT) / 16:00 – 17:00 (GMT) / 9:30pm – 10:30pm (IST)
Next Steps
Ready to begin exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our Quick Start page to get started.

 When Node Is Lost and Then Brought Back Into Cluster?")
