A Matter of Time: Evolving Clock Sync for Distributed Databases
February 2, 2022
Distributed clock synchronization is critical for many applications, including distributed SQL databases. Clock synchronization needs to keep up with the other demands in our modern infrastructure, such as:
- Applications that have increasing performance requirements while distributing data across different geographic regions
- Network infrastructure and computing power that is improving constantly
A distributed SQL database is highly available and resilient to failures when deployed across a cluster of nodes. It can process queries and transactions in a distributed manner while ensuring ACID compliance. What does an atomic clock service have to do with a cloud native, distributed SQL database? It turns out that time synchronization across nodes is critical to achieving distributed transactions. But getting multiple nodes to agree on time is a hard problem.
In this post, we’ll analyze the challenges and the different approaches to synchronizing time across nodes in a distributed database.
1. Synchronizing wall clocks across nodes
In a distributed cluster (or, more generally, a distributed system), the notion of time becomes ambiguous. Each node has its own notion of time that is not synchronized with the others. This is because nodes (like most modern timekeeping devices) rely on timers built using a quartz crystal oscillator to keep track of the passage of time.
These devices take advantage of quartz crystals vibrating from voltage at a precise frequency. The vibrations of the crystal act like the pendulum of a grandfather clock, ticking off how much time has passed. But the issue arises because these crystals run at different speeds, causing a clock skew. This means that the time across nodes gets out of sync.
Network Time Protocol
One mechanism commonly used to coarsely synchronize wall clocks across nodes is the Network Time Protocol (NTP). NTP is a networking protocol for clock synchronization between the nodes of a cluster which, under ideal conditions, can synchronize time across the participating nodes (of a cluster) to within a few milliseconds of each other.
However, in practice, it is rare to see NTP synchronize time across nodes consistently to within a few milliseconds. This is because deployments in the real world can often get into non-ideal conditions. These conditions include load on the node (NTP is not a kernel service, it runs in user space), asymmetric routes, network congestion, and failures, leading to much higher clock skews. From the ntp.org site on the accuracy of NTP, the typical accuracy can vary from 5ms to over 100ms. This makes it hard to simply use NTP to synchronize time in failure scenarios, especially given the purpose of a distributed SQL database is to work reliably even under failure scenarios.
Analyzing an example banking application
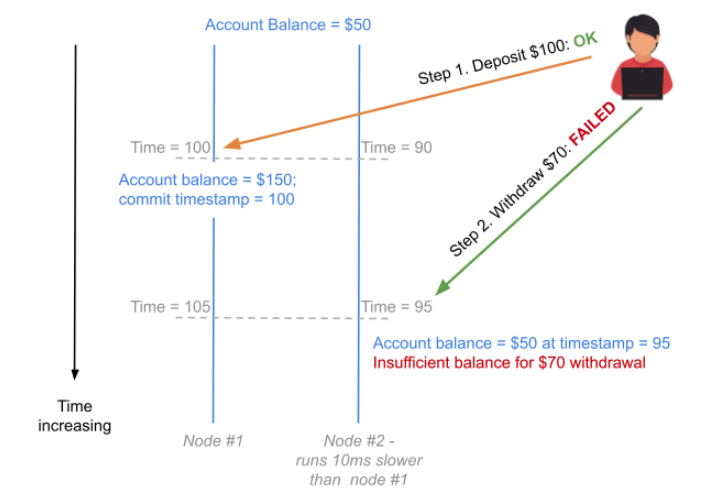
Let’s take an example of what could go wrong if time is not tightly synchronized across nodes. Say a banking application runs on a distributed, transactional database. This database then runs on a cluster of nodes where two of the nodes in the cluster have a 10s clock skew. Now assume that a particular user (with $50 in their checking account) first deposits $100, followed by withdrawing $70, which should succeed. The following scenario could arise if we do not synchronize time across nodes:
- The wall clock time on node #1 is 10s ahead of that on node #2.
- To begin with, the user has $50 in their account.
- The user connects to node #1 to deposit $100, and since the wall clock time on node #1 at this time is 100, the user’s account total becomes $150 at time = 100. Note that node #2 has a time of 90.
- About 5s after making the deposit, the user connects to node #2 to withdraw $70, which should succeed. However, the wall clock time on node #2 at this time is 95, and the user made the deposit only at time 100. Thus, per node #2, the user balance is still $50, and the operation to withdraw $70 would fail.
Below is a diagram depicting this scenario.
2. Logical clocks
The most well-known logical clock is Lamport’s Clock, originally proposed by Leslie Lamport. The Lamport timestamp algorithm provides a partial ordering of events by using the following rules:
- A process increments its counter before each local event (e.g., message sending event).
- When a process sends a message, it includes its counter value with the message after executing step 1.
- On receiving a message, the counter of the recipient updates, if necessary, to the greater of its current counter and the timestamp in the received message. The counter is then incremented by 1 before the message is considered received.
The algorithm above works if we only want causal ordering. This means that if event A leads to the occurrence of event B, then the timestamp of A is less than B. However, if A and B are unrelated to each other, their timestamps don’t mean anything. Thus, this does not solve our scenario above of a user depositing and subsequently withdrawing money from their account, since those two events are independent of each other. We would run into the same issue pointed out above.
The timestamp oracle – centralized logical clock
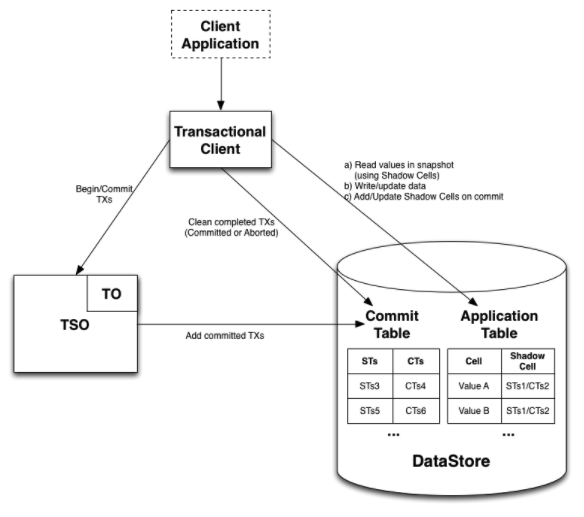
In order to eliminate clock skew and ensure all nodes have the same notion of time, one option is to use a centralized service that is the timestamp authority. In this scheme, all nodes use an external service to generate any timestamp. The Timestamp Oracle (TO) issues the start and commit timestamps for each transaction. This is a single node that ensures the timestamps are monotonically increasing as time progresses. Apache Omid (Optimistically transaction Management In Datastores) uses such a mechanism, as do Google Percolator and TiDB.
The single responsibility of the Timestamp Oracle is to manage transaction timestamps. Transaction timestamps serve as a logical clock and preserve the time-related guarantees required for Snapshot Isolation.
The TO allocates and delivers transaction timestamps when required by the TSO. To achieve this task, it maintains a monotonically increasing counter. Transaction timestamps allocate when a transaction begins and right after a transaction willing to commit has passed the writeset validation. The start timestamp is also used as a transaction identifier.
Below is a diagram outlining how Apache Omid works.
Issues with this approach
Violates horizontal scalability principle: The timestamp oracle could become a bottleneck as the cluster scales. It is in the critical path for all transactions, and is effectively just a single node irrespective of the size of the cluster. Thus, in this architecture, it is not really possible to scale out the timestamp oracle. This is because we’d be introducing clock skew between the two different timestamp oracle instances—and would be back to square one. With horizontal scalability as a core design principle for a distributed SQL database, this approach is not acceptable.
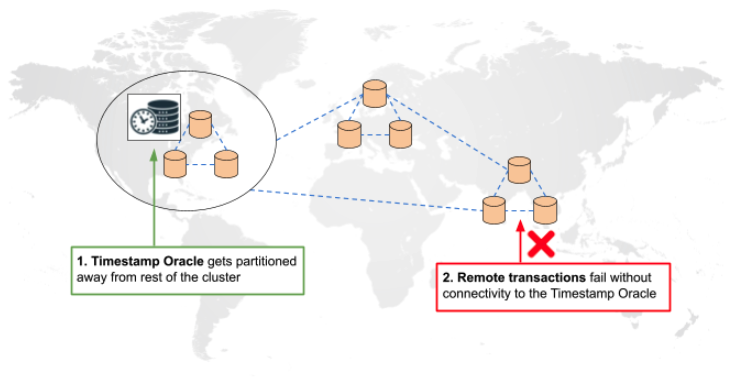
Not highly available for geo-distributed deployments: In geo-distributed deployments, there is still exactly one timestamp oracle, which partitions away from some of the nodes in the cluster. This could lead to the following scenario. Assume that the transaction oracle partitions from a set of nodes in a remote region, which could be a relatively common occurrence. Transactions between these nodes in the remote region would still require the timestamp oracle to issue timestamps, which partitions away. Thus, all these transactions would fail because they could not synchronize time amongst themselves, as shown in the diagram below.
3. Distributed time sync using atomic clocks
Google Spanner uses the TrueTime service, which is highly available and built using GPS and atomic clocks. TrueTime can guarantee an upper bound on the clock skew between the nodes in the cluster to under 7ms. The implementation of the TrueTime service is as follows:
TrueTime is implemented by a set of time master machines per datacenter and a timeslave daemon per machine. The majority of masters have GPS receivers with dedicated antennas; these masters separate physically to reduce the effects of antenna failures, radio interference, and spoofing. The remaining masters (which we refer to as Armageddon masters) are equipped with atomic clocks.
A brief note on atomic clocks
Clock skew across nodes would be unacceptable for distributed SQL databases, which need extremely stable clocks. Stability refers to how consistently a clock measures a unit of time. For example, its measurement of the length of a second needs to be precise over days and weeks.
Atomic clocks observe the ultra-stable oscillations of the atoms trapped within them. At the Naval Observatory, they rely on dozens of cesium and hydrogen maser clocks. The array of atomic clocks used by the U.S. Naval Observatory, the Master Clock, only deviates by 100 picoseconds (0.000 000 000 1 seconds) per day.
How TrueTime simplifies transactions
How does this service simplify our example scenario above? By knowing that the time on any two nodes can be no more than 7ms apart, it is possible to introduce an artificial delay of 7ms after accepting a transaction, and before committing it. This delay ensures that all other nodes in the cluster would have caught up to the issued timestamp being issued.
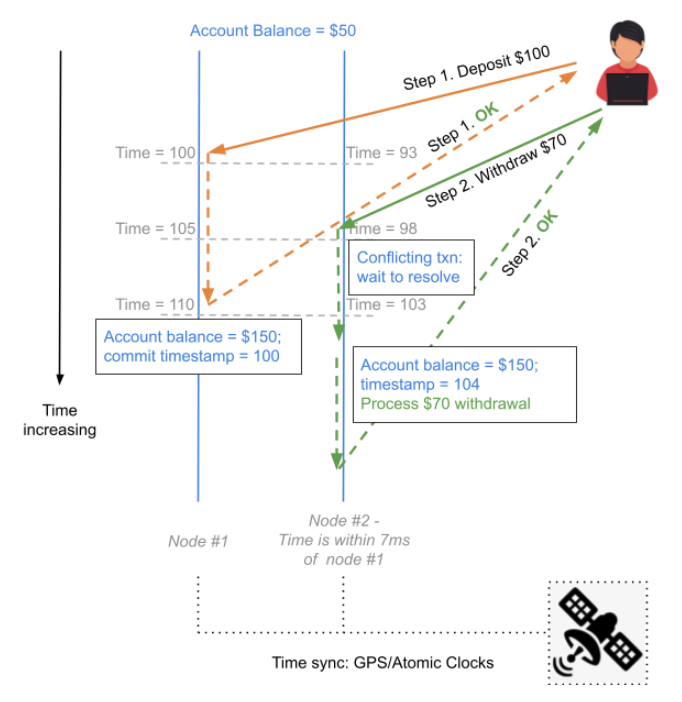
The figure above shows how this scheme works in the context of the example we used earlier. Note that the deposit transaction is accepted for a write at timestamp 100, but applied only at a later point in time (110 in the figure above). This ensures that no other node can serve a stale transaction, and the transaction doing the withdrawal detects the conflict. In the example above, this is resolved by the withdrawal “waiting” for the conflicting transaction to commit before being processed (this mode of waiting is called pessimistic concurrency control).
Issues with this approach
The primary issue with this approach is that a TrueTime-like service, which depends on GPS and atomic clocks, is not a commodity service. This makes it infeasible to easily deploy and run the database on most public or private clouds.
4. Distributed time sync with Hybrid Logical Clocks
Hybrid Logical Clocks (HLC) can perform distributed time synchronization without requiring a GPS/atomic clock service like TrueTime. It does this by combining physical clocks and vector clocks to enable better distributed time synchronization between the nodes of a cluster:
HLC captures the causality relationship like logical clocks, and enables easy identification of consistent snapshots in distributed systems. Dually, HLC can be used in lieu of physical/NTP clocks since it maintains its logical clock to be always close to the NTP clock.
The HLC-timestamp is a 64-bit value represented as the tuple (physical component, logical component). The physical component is a 52-bit microsecond-precision timestamp that synchronizes using NTP. The logical component is a 12-bit vector clock that tracks causal dependencies, as shown in the below diagram.

HLCs generated on any node are strictly monotonic. This ensures that the time on each node only moves forward and never jumps back. A distributed SQL database uses the physical clock (CLOCK_REALTIME in Linux) of a node to initialize the physical time component of its HLC. Because the physical component of the HLC—which is the wall clock time on the node—is synchronized using NTP or chrony, it should be possible to bound the maximum skew across any two nodes of the cluster. In practice, we see a 100-250ms max skew using NTP, so a value of 500ms is a safe default for the max skew. In effect, this means no two nodes can have their physical component more than 500ms apart if they generate timestamps at the same time.
HLCs for YugabyteDB
YugabyteDB is the first—and only—100% open-source, hybrid, multi-cloud, distributed SQL database on the planet. Each node in a YugabyteDB cluster first computes its own HLC value. When any node in the cluster makes an RPC call to another node, the pair of nodes exchange HLC timestamps. The node with the lower HLC timestamp updates its HLC to the higher value.
Our choice for the time sync mechanism had to take into account some of the fundamental design principles for YugabyteDB, such as:
- Horizontal scalability
- Support for multi-region transactional workloads requiring geographic distribution of data
- The ability to deploy and run anywhere with no external dependencies
This ruled out the centralized timestamp oracle option because it was a scalability bottleneck and unsuitable for geo-distributed deployments. The Google Spanner approach of performing distributed time synchronization across the nodes requires a service like TrueTime. But TrueTime is not readily available in most environments (public or private clouds).
Issues with this approach
The main downside is in certain scenarios where concurrent transactions try to perform conflicting updates. In these scenarios, the conflict resolution depends on the maximum clock skew in the cluster. This leads to a higher number of transaction conflicts or a higher latency of the transaction.
Going beyond TrueTime and HLCs
The problem of improving distributed time synchronization is far from done. There are some active, interesting projects underway that aim to improve distributed time synchronization. Some of them are listed below.
HUYGENS (Apr 2018)
In Exploiting a Natural Network Effect for Scalable, Fine-grained Clock Synchronization presented at the USENIX Symposium on NSDI ‘18, the authors state:
Nanosecond-level clock synchronization can be an enabler of a new spectrum of timing- and delay-critical applications in data centers.
To achieve this, they came up with HUYGENS, a software clock synchronization system that uses a synchronization network and leverages three key ideas:
- Coded probes identify and reject impure probe data. This is data captured by probes which suffer queuing delays, random jitter, and NIC timestamp noise.
- HUYGENS processes the purified data with Support Vector Machines, a widely-used and powerful classifier, to accurately estimate one-way propagation times and achieve clock synchronization to within 100 nanoseconds.
- Finally, HUYGENS exploits a natural network effect—the idea that a group of pair-wise synchronized clocks must be transitively synchronized—to detect and correct synchronization errors even further.
And here’s the impressive result in practice:
We find the discrepancy between clock frequencies is typically 5-10µs/sec, but it can be as much as 30µs/sec. We show that HUYGENS achieves synchronization to within a few 10s of nanoseconds under varying loads, with a negligible overhead upon link bandwidth due to probes. Because HUYGENS is implemented in software running on standard hardware, it can be readily deployed in current data centers.
Building an accurate time service at Facebook scale (Mar 2020)
Not surprisingly, Facebook experienced the similar challenge of synchronizing time across machines at scale:
As Facebook’s infrastructure has grown, time precision in our systems has become more and more important. We need to know the accurate time difference between two random servers in a data center so that datastore writes don’t mix up the order of transactions. We need to sync all the servers across many data centers with sub-millisecond precision.
Facebook did some careful measurements to compare ntpd and chrony. However, the result indicates that chrony is far more precise:
During testing, we found that chrony is significantly more accurate and scalable than the previously used service, ntpd, which made it an easy decision for us to replace ntpd in our infrastructure.
Chrony was just one component of a multi-layered precision time synchronization service, backed by atomic clocks and GPS systems on satellites. Below is the architecture diagram of the four-layered service.
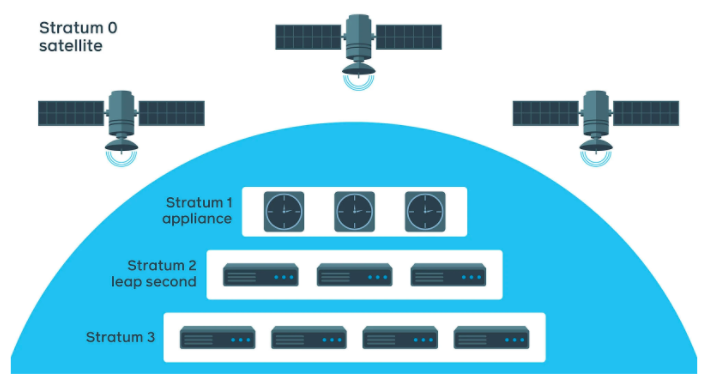
With this service, they were able to improve time precision from tens of milliseconds to hundreds of microseconds.
Sundial (Apr 2020)
There was a paper that recently appeared in OSDI 2020 called Sundial: Fault-tolerant Clock Synchronization for Datacenters. The authors present a fault-tolerant clock synchronization system for datacenters that achieves around 100ns (yes, that’s nanoseconds) time-uncertainty bound under various types of failures. From the abstract:
Sundial provides fast failure detection based on frequent synchronization messages in hardware. Sundial enables fast failure recovery using a novel graph based algorithm to precompute a backup plan that is generic to failures. Through experiments in a >500-machine testbed and large-scale simulations, we show that Sundial can achieve ~100ns time-uncertainty bound under different types of failures, which is more than two orders of magnitude lower than the state-of-the-art solutions.
Sundial is able to get epsilon less than 100 nanoseconds using the following techniques to achieve better time synchronization:
- Performs timestamping and synchronization at L2 data link level in a point-to-point manner using the hardware NIC. Doing synchronization at the hardware level enables frequent synchronization to compensate for the uncontrollable clock drifts of quartz clocks. They send a synchronization signal every 500 microseconds to reduce clock drift of quartz clocks and to keep epsilon very small. Performing synchronization this frequently would not work over software.
- Sundial uses a spanning tree as the multi-hop synchronization structure and synchronizes the nodes with respect to a single root. Sundial uses predetermined backup parents to default to, so it can recover fast from link and root failures.
Conclusion
We discussed a few different approaches for distributed time synchronization in this post, as summarized in the below table.

We picked HLC, which combines the best of logical clocks and physical clocks. This ensured that we were able to meet the fundamental design principles for YugabyteDB mentioned earlier.
When we began the YugabyteDB project in 2016, our premise was that clock synchronization in public clouds would keep getting better over time. This premise has already proven to be true with services such as Amazon Time Sync Service, which launched in 2017 followed by Time Sync for Azure.
Lastly, it is very exciting to see the newer, novel approaches in this area outlined in a prior section. We often look into such works to see how we can continuously improve YugabyteDB and offer higher transactional guarantees with better performance.
Ensure continuous availability and limitless scale with YugabyteDB Managed, an effortless way to get started with YugabyteDB. Register now to spin up a free YugabyteDB cluster!


