How to Integrate YugabyteDB with Real-Time OLAP DB (Apache Pinot) Using a CDC Connector
March 1, 2023
Building a modern, powerful data layer means leveraging a variety of best-in-class technologies—from the right cloud services to cloud native app frameworks to everything in between. A key part of the “in between” is choosing the right set of database solutions that can store transactional data consistency, provide the right level of analytics, and seamlessly connect those two together for real-time data sharing. How those solutions are connected and integrated is a key step.
In this blog, we’ll walk through how to integrate YugabyteDB with a real-time OLAP database-Apache Pinot-using the YugabyteDB Change Data Capture (CDC) connector.
Introducing Apache Pinot and YugabyteDB
Apache Pinot is a real-time distributed OLAP database designed for low-latency query execution even during times of extremely high throughput. It can ingest directly from streaming sources like Apache Kafka and make events available for querying immediately. Apache Pinot is used to build real-time OLAP queries, user-facing analytics, personalization, ad-hoc analytics, and search.
YugabyteDB is an open source distributed SQL database for transactional (OLTP) applications. YugabyteDB is designed to be a powerful cloud native database that can run in any cloud – private, public, or hybrid.
Integration of YugabyteDB (OLTP) with Apache Pinot (OLAP)
Achieving OLAP analytics at OLTP scale is challenging. Traditional OLAP uses either a pre-aggregate or pre-cube model to store the data in a multi-dimensional format. Apache Pinot instead splits the workload between near-real-time OLAP vs user-facing analytics (for example, LinkedIn profile views or user rating scores) by automatically deciding which will generate the best trade-off.
It can balance the storage of pre-aggregate or pre-cube data for specific queries by using special indexing techniques. Event or raw data can be made available for other queries.
YugabyteDB can seamlessly connect and offload transactional workloads to Apache Pinot using the YugabyteDB CDC connector. The seamless connection through the YugabyteDB CDC connector helps the application to consume both OLAP and OLTP workloads without requiring additional processing or batch programs to load data from YugabyteDB to Pinot.
Benefits of YugabyteDB Integration to Apache Pinot:
Together, YugabyteDB and Apache Pinot provide the following benefits:
- Distributed Architecture: Pinot data is stored in segments which pack in a columnar fashion and supports the periodic push of offline segments and the creation of segments by real-time segment servers. Therefore, query processing is faster than when done through centralized OLAP servers or storage.
- No additional software: The change data streams from YugabyteDB to Pinot’s real-time table without additional processing. The broker component of Pinot leverages YugabyteDB’s CDC layer and consumes the messages directly into its table.
- Real-Time OLAP: Analytical capabilities are exposed directly to the customer/end-user to provide a personalized experience (e.g. restaurant rating, food ratings, or profile views on LinkedIn). Since personalization directly impacts the user experience, it demands high throughput and low query latency.
- Faster than Traditional OLAP Queries: A column within a Pinot table can be configured to have a sorted index. Internally, it uses run-length encoding to capture the start and end-location pointers for a given column value, drastically reducing scans and in turn decreasing query processing time.
- Cloud and Infrastructure Agnostic: Pinot can connect from its own infrastructure to the Yugabyte database where it can reside either on-premise or public cloud.
YugabyteDB to Pinot Architecture
The diagram below (Figure 1) shows the end-to-end integration architecture of YugabyteDB to Apache Pinot.

The streamed change data from the YugabyteDB Debezium/Kafka connector is streamed directly to Apache Pinot’s real-time table.
Components of YugabyteDB Integration with Pinot:
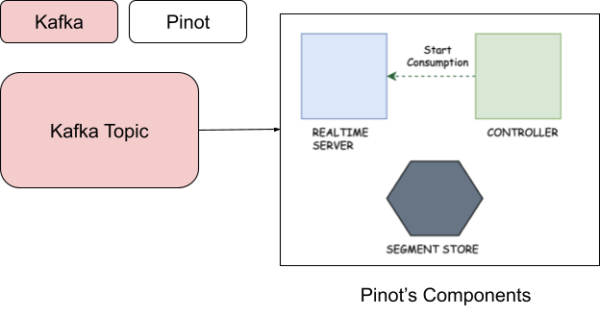
The diagram below (Figure 2) shows the physical components required to build the integration between YugabyteDB and Apache Pinot.
| Tool/Component Name | Purpose |
| Debezium YugabyteDB Kafka connect | Used to stream the changed datasets requested from YugabyteDB YSQL Tables |
| Realtime Server | Real-time server nodes ingest data from streaming sources, such as Kafka and generate the indexed segments in-memory (flushing segments to disk periodically). |
| Controller | Pinot’s controller acts as the driver of the cluster’s overall state and health. It is the first component typically started after Zookeeper. Two parameters are required for starting a controller. Zookeeper address and cluster name. |
| Segment Store | A segment is a horizontal shard representing a chunk of table data with some number of rows. The segment stores data for all columns of the table. Each segment packs the data in a columnar fashion, along with the dictionaries and indices for the columns. |
Use Cases For YugabyteDB Integration with Pinot
- IoT Sensor’s Performance Dashboard: An IoT application continuously streams sensor events or sends the signal data from different actuators or IoT gateways. YugabyteDB helps store this event-driven data using the YSQL API. YugabyteDB’s CDC will continuously stream the data to Apache Pinot to help build a dashboard with different time frames (e.g. weekly or monthly or custom window). The diagram below (Figure 3) shows IoT Sensor details dashboard built using Apache Superset using Apache Pinot Connector.

Figure 3: IoT Sensor Details—Real-time Dashboard - Real-time Aggregation for Customer Facing Retail Apps: Applications need to provide historical and real-time aggregations as needed. Transactions are stored with low latency and high throughput in YugabyteDB, so maintaining historical transactions in YugabyteDB will not be a challenge. However, it will not function as an OLAP if the application needs different slices and dices to aggregate the results. YugabyteDB’s CDC connector continuously pushes real-time transactions to Apache Pinot. Here, the role of Apache Pinot is to get the required aggregated results by calculating the aggregations based on different dimensions on the fly. It supports pre-join, pre-aggregation, and pre-cube operations on the historical data and returns the data with low latency, high flexibility, and low throughput.Example: An online retail ordering app helps the retailer respond quickly if there are suddenly a number of incorrect orders of a specific product category. YugabyteDB continuously stores the product catalog or product’s transaction in the transaction DB. The real-time aggregation of such data provides custom insights for each product or product category, which is immensely useful for day-to-day inventory management.

How to Set Up Apache Pinot’s Sink Configuration
Install YugabyteDB
You have multiple options to install or deploy YugabyteDB if you don’t have one already available. Note: If you’re running a Windows Machine then you can leverage Docker on Windows with YugabyteDB.
Configure YugabyteDB CDC (Source Configuration)
Ensure YugabyteDB CDC is configured at your database level (per this document) and running as per the above architecture diagram (Figure 1) along with its dependent components. You should see a Kafka topic name and group name (per this document) and it will appear in the streaming logs either through CLI or the Kafka UI (e.g. if you used KOwl)
Metrics and Dashboard for CDC (Change Data Capture):
The important health metrics of the CDC between YugabyteDB and Apache Pinot are mentioned below. How to access those health metrics is explained in our recent blog, Monitoring Change Data Capture (CDC) Using YugabyteDB’s Metrics Dashboard, In this integration, we have tested IOTPUBNUB data which is close to 230K to 300K records from YugabyteDB to Pinot.
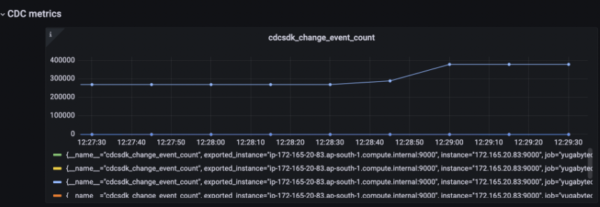
Change Event Count: The Change Event Count metric shown in Figure 4 displays the number of records sent by the CDC Service from YugabyteDB.
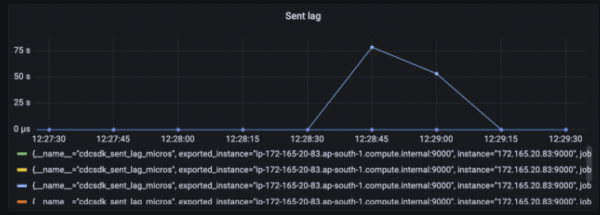
Figure 4: Change Event Count Sent Lag: It keeps track of the difference between the commit time of the last streamed record to the connector vs the newest committed record to YugabyteDB. This metric is maintained on a per-node level. We tested this integration in a single node. Figure 5 shows Sent Lag with the different timeframes.
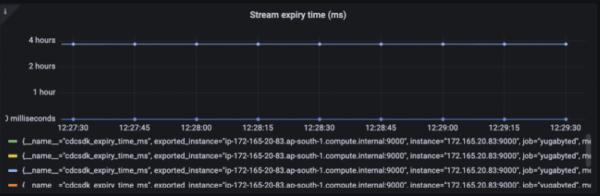
Figure 5: Sent Lag Stream Expiry Time: Records are retained in WAL for a limited period of time. The retention period can be configured using cdc_retention_time_ms. Figure 6 shows stream expiry time in milliseconds with the different timeframes.
Figure 6: Stream Expiry Time (in milliseconds) Install Apache Pinot
Apache Pinot can be installed locally using this Apache document, or you can install as docker containers using this Apache link. Post installation you should have the following daemons up and running.
- Zookeeper of Pinot
- Controller
- Broker
- HTTP Server
Note: Ignore the Kafka installation since you will be leveraging the kafka broker from YugabyteDB’s CDC.
Connect YugabyteDB CDC Kafka with Apache Pinot
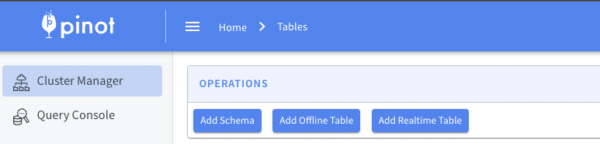
Create the necessary schema and a real-time table in Apache Pinot. The below diagram shows the cluster manager configuration screen ( Figure 7 ) of Apache Pinot.
Figure 7: Cluster Manager Configuration in Apache Pinot Click “Add Schema” and enter the dimension, metrics and timestamp fields (see below) and save it.
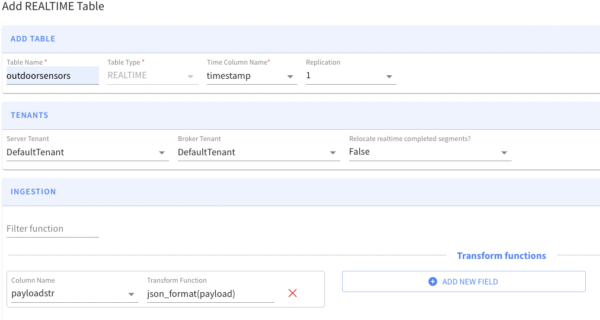
Click “Add REALTIME table” to stream the data in real time (see below).
Enter the Kafka Topic Name and Kafka Broker List as per YugabyteDB’s CDC configuration.
A NOTE ON UPSERT mode: Apache Pinot provides native support of upsert during the real-time ingestion. The upsert mode defaults to NONE for realtime tables. To enable the full upsert, set the mode to FULL in table definition.
Query the Real Time Table in Pinot
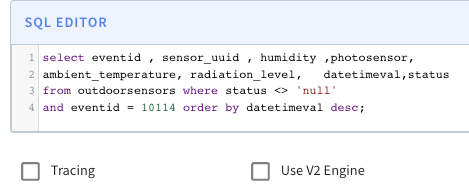
Using the Query console of Pinot, we can choose the specific table and query, like SQL Query in the SQL Editor below.
Schema Evolution in Pinot DB and YugabyteDB
Schema evolution in YugabyteDB: YugabyteDB CDC takes care of schema evolution without stopping or pausing the data stream. For example, the following table is stored in YugabyteDB:
yugabyte=# \d iotpubnubdata Table "public.iotpubnubdata" Column | Type | Collation | Nullable | Default ---------------------+------------------------+-----------+----------+------------------------------------------------ eventid | bigint | | not null | nextval('iotpubnubdata_eventid_seq'::regclass) sensor_uuid | character varying(100) | | | humidity | character varying(100) | | | photosensor | character varying(100) | | | ambient_temperature | character varying(100) | | | radiation_level | character varying(100) | | | timestamp | character varying(100) | | | Indexes: "iotpubnubdata_pkey" PRIMARY KEY, lsm (eventid HASH)The data is then streamed to Debezium Kafka Connect. This table got a schema change (a new column status is being added).
yugabyte=# alter table iotpubnubdata add status varchar(1); ALTER TABLE yugabyte=# \d iotpubnubdata Table "public.iotpubnubdata" Column | Type | Collation | Nullable | Default ---------------------+------------------------+-----------+----------+------------------------------------------------ eventid | bigint | | not null | nextval('iotpubnubdata_eventid_seq'::regclass) sensor_uuid | character varying(100) | | | humidity | character varying(100) | | | photosensor | character varying(100) | | | ambient_temperature | character varying(100) | | | radiation_level | character varying(100) | | | timestamp | character varying(100) | | | status | character varying(1) | | | Indexes: "iotpubnubdata_pkey" PRIMARY KEY, lsm (eventid HASH) yugabyte=# select * from iotpubnubdata where status is not null and eventid = 10114 limit 1; eventid | sensor_uuid | humidity | photosensor | ambient_temperature | radiation_level | timestamp | status ---------+---------------+----------+-------------+---------------------+-----------------+---------------+-------- 10114 | probe-tbhbnad | 80.655 | 803.72 | 20.93 | 201 | 1675593764097 | A (1 row) yugabyte=#The new data now appears in the table “Status”, and the CDC stream is continuously working as soon as this change is reflected in the WAL-irrespective of this schema change. It will be sent to Kafka and the same can be consumed by Apache Pinot.
Schema evolution in Pinot does not require the deletion and recreation of the table. Whenever YugabyteDB changes the model (by adding a new column on its table) and reflects this in CDC streams, Apache Pinot supports the schema evolution. This can be done through CLI and CURL commands.
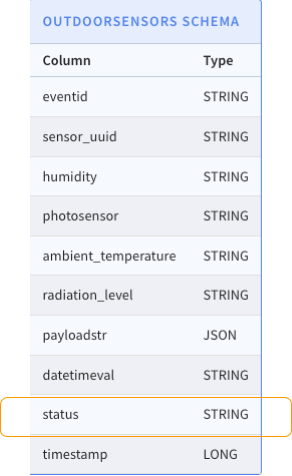
Figure 8 below shows the Schema of Outdoorsensors Realtime table in Pinot. (Note that a new column, status, was added).
Figure 8: Schema of Outdoorsensors In case of real-time tables in Apache Pinot make sure the “pinot.server.instance.reload.consumingSegment” config is set to true inside Server config. Without this, the current consuming segment(s) will not reflect the default null value for newly added columns. Note: the real values for the newly added columns won’t be reflected within the current consuming segment(s). The next consuming segment(s) will start consuming the real values.
curl -X POST localhost:9000/segments/outdoorsensors_REALTIME/reload {"status":"Segment reload details: {\"outdoorsensors_REALTIME\":{\"reloadJobId\":\"ac01bbe1-9c26-40ce-9673-440192ceb21d\",\"reloadJobMetaZKStorageStatus\":\"SUCCESS\",\"numMessagesSent\":\"1\"}}"}The same record we could see in Apache Pinot is streamed after the schema change is reflected between the source and target. Connect the Real-time table of Pinot using JDBC or Standard Dashboard tools
To connect Apache Pinot from your application, Pinot offers a standard JDBC interface to query the database, or you can use dashboard tools like Tableau, Trino, Apache Superset, StarTree and Presto.




 The same record we could see in Apache Pinot is streamed after the schema change is reflected between the source and target.
The same record we could see in Apache Pinot is streamed after the schema change is reflected between the source and target. 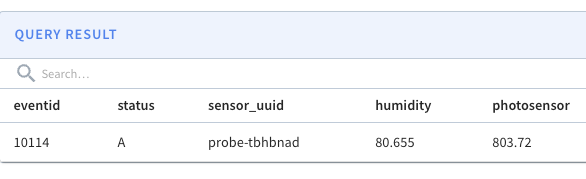
Conclusion and Summary
In this blog post we walked through step-by-step how to integrate YugabyteDB with Apache Pinot using YugabyteDB’s CDC connector.
These steps help to integrate real-time OLAP queries for your application from Pinot so you can pre-join, pre-aggregate and pre-cube your data with specific dimensions and measures.
The above CDC metrics provide valuable information for monitoring CDC operations, performance testing, benchmarking, etc. The metrics collected by YugabyteDB CDC provide an intuitive, visual way to monitor the health, performance, and progress of these CDC operations. For detailed information on CDC metrics, please refer to this page.
The schema evolution in YugabyteDB doesn’t require any outages or downtime when the source table undergoes schema changes. Together, YugabyteDB and Apache Pinot can help you deliver user-facing analytics or build user-facing apps for your enterprise that can generate business value from the large amounts of data you collect and store.


