Integrating YugabyteDB with Azure AI Search
April 21, 2025
Introduction
Modern businesses generate vast amounts of structured and unstructured data. Efficiently searching, analyzing, and deriving insights from this data is crucial for decision-making, process optimization, and customer experience enhancement. Traditional database systems often struggle to handle the scale, complexity, and variety of modern data workloads.
By combining modern distributed SQL databases and cloud-based search services, businesses can unlock new possibilities for scalable document management, transactional analytics, and search-optimized workflows. YugabyteDB and Azure AI Search together provide a robust solution for managing both structured and unstructured data with operational efficiency.
This blog demonstrates how insurers can enhance claims processing workflows by using YugabyteDB’s distributed database and Azure AI Search.
About YugabyteDB
YugabyteDB is a PostgreSQL-compatible, high-performance, distributed SQL database designed for cloud-native applications. It combines the benefits of SQL’s relational model with the scalability and resilience of a distributed database. This makes it ideal for modern applications that require global data distribution, high availability, and strong consistency. Built on top of a highly scalable architecture, YugabyteDB can handle large amounts of data and high transaction volumes across multiple regions, all while maintaining low-latency access to data.
About Azure AI Search
Azure AI Search is a cloud-based service that provides enterprise-ready information retrieval, enabling advanced search capabilities over diverse content using AI-powered indexing and querying. Key features include a full-text search for identifying suspicious activities, a semantic search for understanding context, anomaly detection to spot unusual patterns, and data enrichment for a comprehensive view of transactions.
Use Cases for Search-Optimized Document and Data Integration
The combination of YugabyteDB and Azure AI Search can be used in various industries and applications:
- Fraud Detection: Identifying suspicious activities through search-optimized workflows and structured fraud analytics.
- Customer Support Optimization: Enhancing search capabilities in customer support systems for faster issue resolution.
- Healthcare and Medical Record Search: Improving searchability and analysis of patient records, medical documents, and imaging reports.
- E-commerce and Recommendation Engines: Enabling smart product recommendations and personalized search experiences.
- Legal Document and Compliance Analysis: Automating contract review, legal document search, and regulatory compliance tracking.
Operational Fraud Detection: Using Transactional Queries
Fraud detection in various industries has traditionally relied on rule-based systems, which often miss complex or evolving fraud patterns. Operational analytics through structured SQL queries enables businesses to detect potential anomalies such as duplicate claims, high-value payouts, or frequent filings. These transactional queries complement the document search and indexing capabilities of Azure AI Search, providing a comprehensive approach to claims investigation and reporting.
In industries like insurance, it’s essential that solutions comply with data governance and regulatory requirements (such as Solvency, GDPR, or HIPAA). Fraud detection systems must enforce strong data privacy controls, auditability, and transparency to meet legal and compliance standards.
How to Integrate YugabyteDB with Azure AI Search
This architecture shows the integration of YugabyteDB with Azure AI search, leveraging its index, indexers, skillsets, and Azure cloud storage for claims processing and fraud detection.
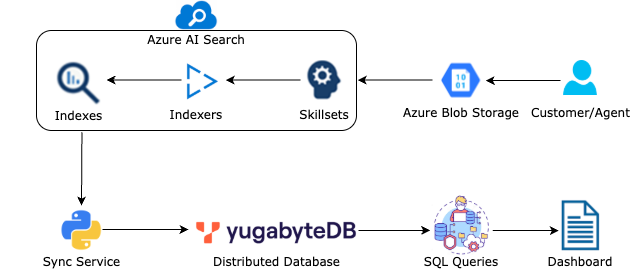
Here’s a simplified breakdown:
- Customer/Agent Application: A web or mobile app where customers or agents upload claim documents (PDFs, emails, or scanned images).
- Azure Blob Storage: This stores the uploaded claim documents securely for processing.
- Azure AI Search Indexer and Skillset: The Indexer fetches documents from Blob Storage, and Skillset (OCR and NLP) extracts claim details (e.g., Claim ID, Policy ID, Claim Amount, Description, etc.). Extracted text and metadata are stored in the AI Search Index for fast searches.
- Azure AI Search Index: This serves as the structured repository where your searchable content resides. It enables efficient full-text search, filtering, and retrieval operations across your data.
- Sync Service (Python Script): Fetches indexed claim data from Azure AI Search and parses and inserts it into YugabyteDB.
- YugabyteDB: Stores structured claim details in the claims table (Claim ID, Policy ID, Amount, Date, Status, Description, etc), runs fraud detection queries such as duplicate claims, high-value claims, and suspicious patterns, and ensures distributed and scalable database performance.
- Fraud Analysis Dashboard: A dashboard or API that provides insights into flagged claims for insurance companies to review.
Step 1: Setting Up Azure AI Search
1.1 Create an Azure AI Search Service
- Log in to the Azure Portal: Go to portal.azure.com.
- Search for Azure AI Search: In the search bar, type “Azure AI Search” and select it.
- Create a New Service:
- Click Create.
- Select your Subscription and Resource Group.
- Choose a Region and Pricing Tier (Standard is recommended for most use cases).
- Set the Service Name to fraud-detection-search.
- Click Review + Create, then Create.
1.2 Configure an Index
An index in Azure AI Search is like a search-optimized database table. It stores the extracted data in a structured way for fast searches.
- Create an Index.
- Click Indexes → Create Index.
- Set the Index Name to insurance-claims-index-v2.
- Click Create.
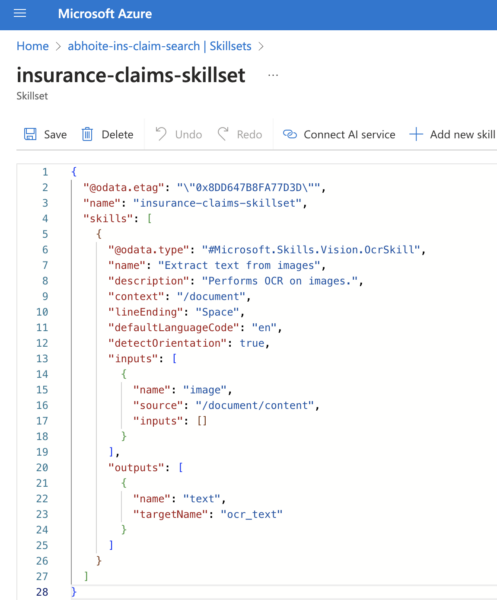
1.3 Add Skillsets
Skillset is designed to enrich and transform data during the indexing process. The provided JSON snippet defines a skillset named “insurance-claims-skillset,” which includes an OCR (Optical Character Recognition) skill. This particular skill is configured to extract text from PDF documents.
- Click Skillsets → Add skillset.
- Add Skillset JSON definition with name insurance-claims-skillset, then save the skillset.
1.4 Create an Indexer
An indexer is an automated process that extracts data from a source, e.g. Blob Storage, processes it, and adds it to the AI Search Index.
- Go to Indexers: In your AI Search service, click Indexers → Create Indexer.
- Configure the Indexer:
- Set the Indexer Name to insurance-claims-indexer-v2
- Choose index as the Index to insurance-claims-index-v2
- Choose Blob Storage as the Data Source to insurance-claims-datasource
- Choose Skillset for AI Enrichment (OCR) to insurance-claims-skillset
- Click Create.
1.5 Upload Sample Documents
- Upload Claims to Blob Storage: Customers and agents upload claim documents (PDFs, emails, scanned images) via the app to Azure Blob Storage, ensuring centralized and secure storage.
- Run the Indexer: Once documents are uploaded, the indexer can run periodically based on the user-defined frequency to extract text and populate the index.
Step 2: Setting Up YugabyteDB
- Create a YugabyteDB Cluster: Install YugabyteDB on three virtual machines or pods with three replication factors using Virtual Machines or Kubernetes Service and follow this YugabyteDB documentation to set up a distributed SQL database cluster.
- Create a Claims Table and index it based on the query pattern
yugabyte=# CREATE TABLE claims (
claim_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
policy_id UUID NOT NULL,
claimant_name TEXT,
claim_status TEXT CHECK (claim_status IN ('Pending', 'Approved', 'Rejected')),
claim_amount NUMERIC,
claim_description TEXT,
claim_date TIMESTAMP,
document_url TEXT,
last_sync_time TIMESTAMP
);Step 3: Syncing Data from Azure AI Search to YugabyteDB
The sync script serves as a bridge between Azure AI Search and YugabyteDB, ensuring that claims data extracted, indexed, and searched in Azure AI Search is also efficiently stored and processed in YugabyteDB for structured storage and advanced analysis.
The AzureAISearchtoYugabyteDBsync.py script automates the process by connecting to Azure AI Search, retrieving claim-related data via API calls, parsing the PDF extracted details (Claim ID, Policy ID, Claim Amount, Description, etc.), and inserting the structured claims data into the YugabyteDB claims table for further processing and reporting.
Optimizing Data Sync: The script uses ON CONFLICT (claim_id) DO UPDATE to update existing records in YugabyteDB, preventing duplicates. For better efficiency in the production use case, track the last sync timestamp to process only new or updated records.
This can be done by storing the last sync time in a database and filtering documents using the last_updated field in Azure AI Search, ensuring faster and more reliable synchronization.
Customers can schedule the AzureAISearchtoYugabyteDBsync.py script using the following methods:
- Using a Cron Job: Customers running the script on Linux servers can use a cron job to schedule execution.
Add a cron job to run the script every 5 Minutes:*/5 * * * * /usr/bin/python3 /path/to/AzureAISearchtoYugabyteDBsync.py >> /var/log/sync 2>&1
- Azure Function App: This process can also be achieved using an Azure Function App, which provides a serverless and automated way to execute the sync script at scheduled intervals. Customers can deploy the script as an Azure Function and schedule it to run automatically using a Timer Trigger.
Example Azure Function Timer Trigger Schedule (Runs Every 5 Minutes):"schedule": "0 */5 * * * *"
Note: Ensure the Azure AI Search Indexer’s refresh schedule matches the execution frequency of the synchronization script.
Step 4: Running Fraud Detection Queries in YugabyteDB
Below are sample SQL queries you can use to identify potentially fraudulent activities within your data. YugabyteDB’s compatibility with PostgreSQL allows you to utilize familiar SQL constructs for this purpose.
Detecting Duplicate Claims
This helps detect duplicate or repeated claims by the same claimant, which could indicate fraudulent activity.
yugabyte=# SELECT claimant_name, COUNT(*) yugabyte-# FROM claims yugabyte-# WHERE claim_description ILIKE '%car%' yugabyte-# GROUP BY claimant_name yugabyte-# HAVING COUNT(*) > 1; claimant_name | count ---------------+------- John Doe | 4 (1 row)
Detecting High-Value Claims Compared to the Average
This query flags claims with unusually high payouts compared to the average for similar claim types, helping insurers detect possible overinflated claims.
yugabyte=# SELECT claim_id, claimant_name, claim_amount yugabyte-# FROM claims yugabyte-# WHERE claim_amount > (SELECT AVG(claim_amount) * 2 FROM claims WHERE claim_description = 'Lost luggage'); claim_id | claimant_name | claim_amount --------------------------------------+----------------+-------------- 1d939d78-040d-448c-867d-1a829e578b42 | David Brown | 30000 ad56cd2f-b735-456b-8b0e-7a327e24a9c8 | Samantha Green | 25000 6f0f3c51-9b8f-4ab2-ae18-835f51a9b153 | James Peterson | 18000 (3 rows)
Detecting Specific Accidents with Damage
This query detects claims mentioning both accidents and damage, which could indicate high-severity claims that need further review.
yugabyte=# SELECT claim_id, claimant_name, claim_description yugabyte-# FROM claims yugabyte-# WHERE claim_description ILIKE '%accident%' yugabyte-# AND claim_description ILIKE '%damage%'; claim_id | claimant_name | claim_description --------------------------------------+----------------+-------------------------------------------------------------------------- ad56cd2f-b735-456b-8b0e-7a327e24a9c8 | Samantha Green | Severe accident resulting in damage to the rear and side of the vehicle. 7f6c3d82-d4d7-4267-a847-7c61c7d2853b | David Wilson | Minor car accident with no significant damage to the vehicle. (2 rows)
Flagging Frequent Claimants
This query helps evaluate fraud detection queries that have filed more than three claims within the past year.
yugabyte=# SELECT claimant_name, COUNT(*) AS claim_count yugabyte-# FROM claims yugabyte-# WHERE claim_date > CURRENT_DATE - INTERVAL '1 year' yugabyte-# GROUP BY claimant_name yugabyte-# HAVING COUNT(*) > 3; claimant_name | claim_count ---------------+------------- John Doe | 5 (1 row)
Step 5: Fraud Analysis Dashboard
You can develop a fraud analysis dashboard using custom web applications or B tools for data visualization, reporting, and analytics.
By connecting to YugabyteDB, the dashboard can display detected fraud cases, enabling insurance companies to take appropriate actions. This setup allows insurance agents to retrieve real-time fraud detection results from YugabyteDB, facilitating the approval, rejection, or flagging of claims while reviewing supporting documents.
Sample Dashboard Report
| Claim ID | Claimant Name | Claim Type | Amount | Risk Score | Flagged For |
|---|---|---|---|---|---|
| ad56cd2f-b735-456b-8b0e-7a327e24a9c8 | John Doe | Car Accident | $45,000 | 🔴 High | Multiple Claims |
| 7f6c3d82-d4d7-4267-a847-7c61c7d2853b | Alice Smith | Lost Luggage | $18,000 | 🟠 Medium | High Amount |
AI Search vs. YugabyteDB: Key Differences
YugabyteDB provides a robust platform for managing transactional workloads with strong consistency and scalability, and AI search systems excel in intelligent data retrieval.
| Feature | Azure AI Search | YugabyteDB |
|---|---|---|
| Search Type | Full-text and Semantic Search | SQL-based Queries |
| Performance | Fast for unstructured data | Optimized for structured data, Scalable distributed queries |
| Use Case | Document Search and Exploration | Identify data anomalies |
| Scalability | Horizontal Scaling | Distributed SQL Scaling |
| Text-based search (OCR, NLP) | Yes, Fast AI-powered search | No, Limited to SQL LIKE queries |
| Structured SQL-Based Search | No | Yes, Complex queries with joins |
| Handles Large-Scale Relational Data | No | Yes |
| Near Real-Time Fraud Detection | NLP-based similarity detection | Rule-based fraud detection |
Conclusion
Integrating YugabyteDB with Azure AI Search combines the strengths of a distributed SQL database with advanced search capabilities, offering a robust solution for data-intensive applications. This integration facilitates efficient data processing and real-time analysis, enhancing operational performance.
However, challenges such as ensuring data accuracy, maintaining regulatory compliance, and managing infrastructure costs must be carefully addressed through strategic planning and optimization. By proactively managing these factors, organizations can fully leverage the benefits of this integrated approach to scalable data management, search, and operational analytics.
Integrating YugabyteDB with Azure AI Search delivers a scalable and highly available database foundation for managing structured operational data.


