Delivering Postgres Parallel Queries in YugabyteDB
September 26, 2024
Achieving query parallelism is a key part of our effort to narrow the performance gap between Postgres and YugabyteDB.
Since its inception, we have gradually been improving the level of query parallelism of YugabyteDB by pushing execution down to the storage layer. YugabyteDB currently supports various scan filters, plus simple aggregations executed in parallel by multiple nodes.
So why do we need the Postgres Parallel Query feature?
Overall, this is part of our bigger effort to make YugabyteDB not just work like Postgres, but also perform like it (or better!)
Parallel queries allow PostgreSQL to distribute the execution between multiple processes running on the same machine. They also support the parallelization of larger, more complex plans, including joining, sorting, and grouping. Integration of the Postgres Parallel Query into YugabyteDB takes the parallelism to the next level, beyond just scan.
In this blog, we deep dive into the Postgres Parallel Query feature that is supported and available in the latest version of YugabyteDB. We’ll share how query parallelism is implemented and works in Postgres, and what we did to ensure the feature works in YugabyteDB. Spoiler Alert: the Postgres Global Development Group did the heavy lifting and we’ve already achieved 2x performance improvements by adopting parallel queries for the YugabyteDB storage architecture!
Why is Query Parallelism Important?
Parallelism is a way to complete the job faster by using more resources, such as CPU, memory, I/O, etc.
One way to parallelize a job is to split it into smaller parts and assign multiple workers to process those parts, as illustrated below.
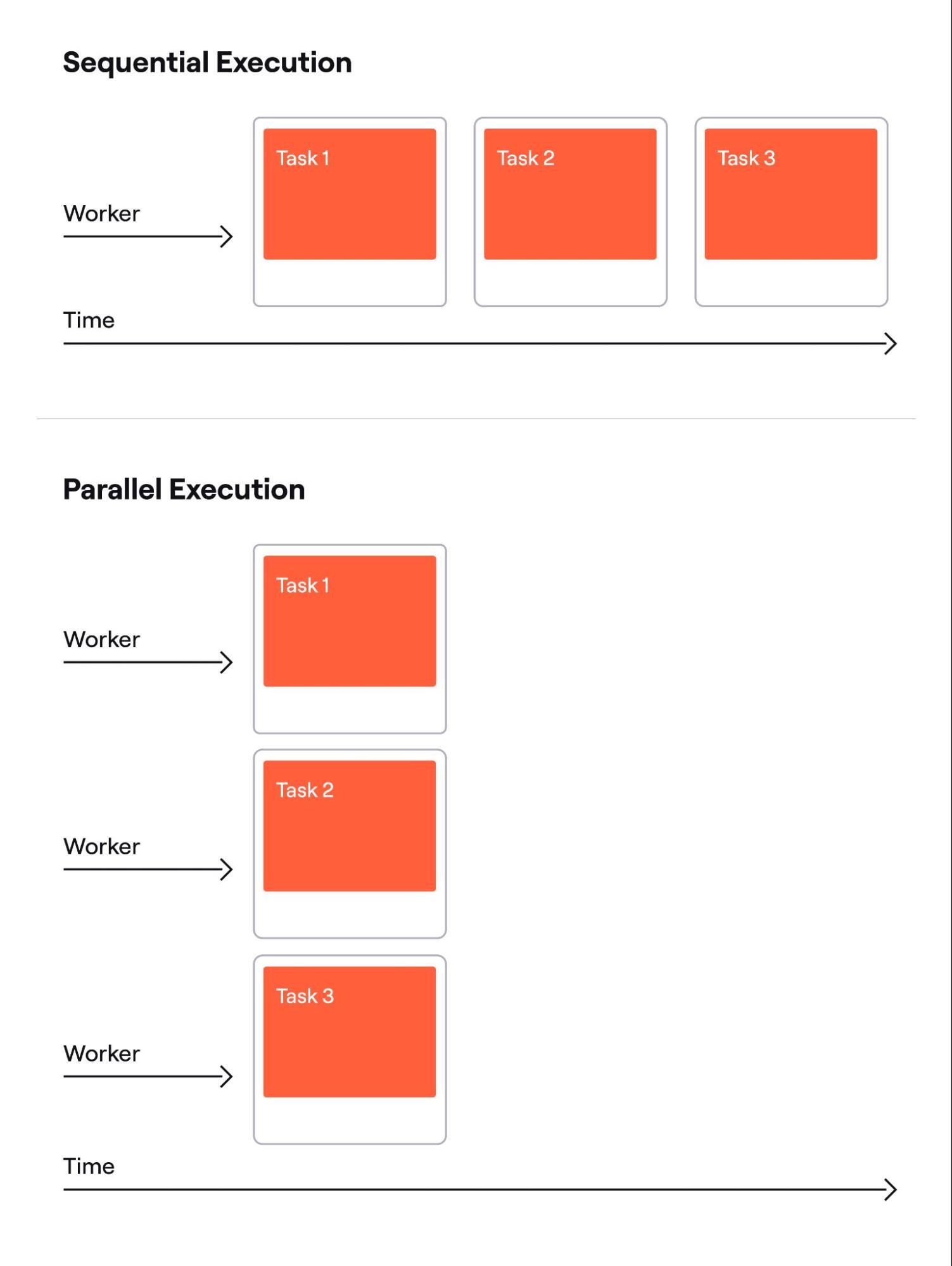
Multiple workers take significantly less time to execute multiple tasks in parallel.
Each worker has its own set of resources, and, in general, the resources per unit of time put toward completion by all the workers combined, is greater than one worker could allocate alone. That holds true when the resources required to complete the parts are equal, or at least close to, the resources required to complete the whole task.
However, parallelism requires some effort and overhead.
- Job splitting requires resources, as well as the combining of results. Therefore, it does not make sense to parallelize a tiny task as the overhead may be comparable to the effort required to complete the entire task. Overhead depends on the nature of the task, and some jobs are easier to split than others.
- Another overhead is communication between the workers. Ideally, a worker should complete the assigned part independently. However, in practice, communication is often necessary. For example, when a small number of workers work on a large number of parts (worker pool), each worker ready to take on another part needs to ensure no one else is working on that part, or attempting to do so. This communication can incur significant overhead. A worker may need to have exclusive locks to access the shared list of tasks. Many workers, small tasks, and taking a long time to assign a task all increase the probability of workers waiting on locks and increase the time, effort, and cost of completing the project.
Parallelism in Distributed Databases
If we think about parallelism in the database world, distributed databases have a way to split their query jobs naturally.
Distributed databases typically shard their data. This means, they break down their data sets into blocks and store each block separately on multiple network nodes. It is a straightforward decision to split the query by shards. The splitting effort is minimal, they just make a list of shards affected by the query and run one worker per shard.
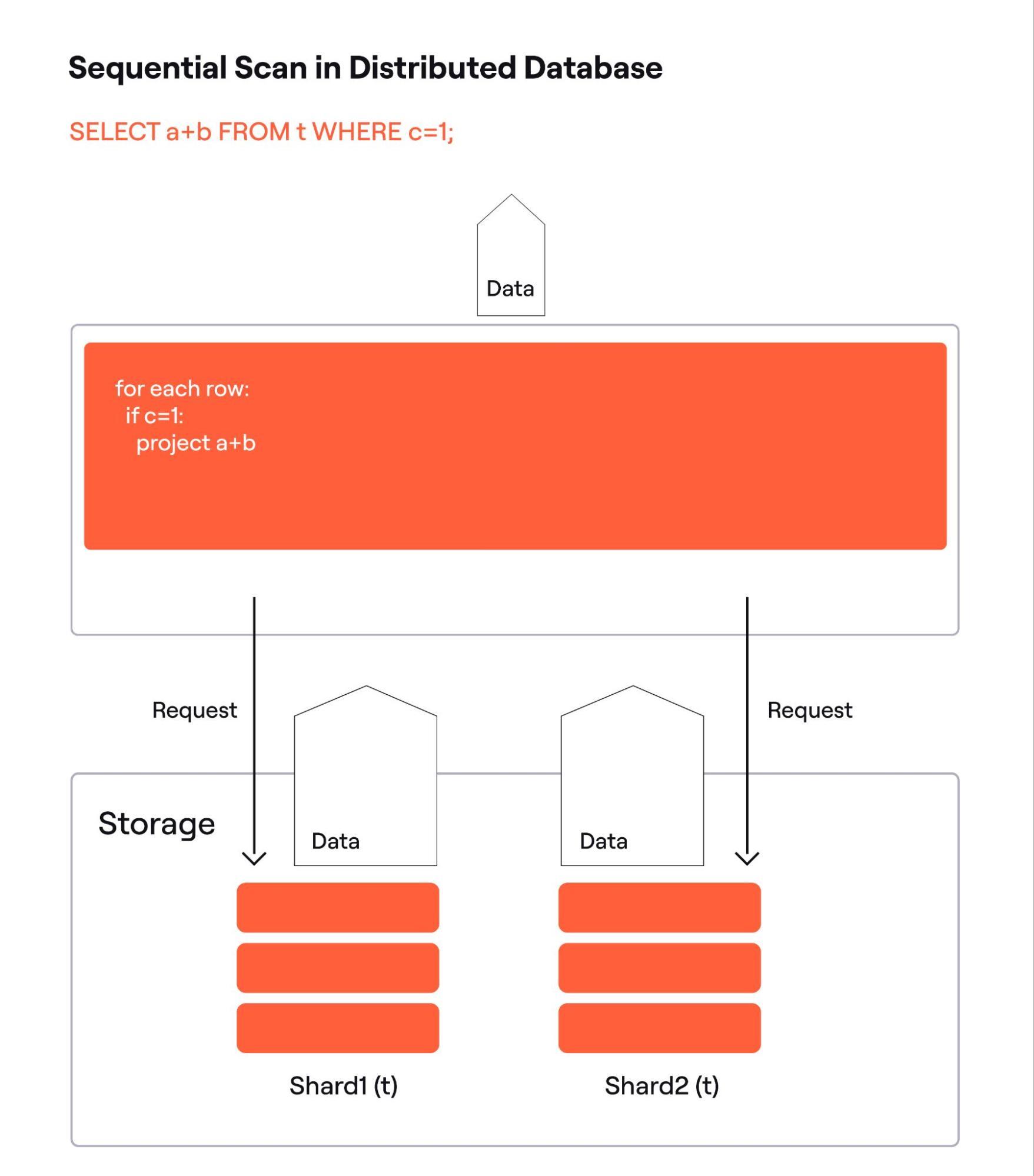
Above is one possible implementation of a sequential scan of a distributed table. The shards are hosted on different nodes and can work in parallel to form the responses to their data requests. In this implementation, the query engine performs the filtering and projecting.
If storage nodes are “smart” and can evaluate expressions, the filter condition and the list of used columns may be included with the request, so data is filtered where it is, reducing network traffic. Fig. 3 below shows this possible implementation.
Note: it does not always make sense to perform projection on the remote nodes. The projected row may be wider than the filtered column values, so it may increase network traffic.

If most of the work is divided between N workers, it takes roughly 1/Nth of the time to complete all the work. In practice, it is more than that, because the query processor has to do a part: prepare requests, handle responses, do projections, etc.
Data may be sharded unevenly, and some workers finish later than others. A query is considered completed when all workers are done, so the actual time is higher than 1/Nth, only approaching this level in ideal conditions.
These considerations are true for a scan, but in general, the effect of parallelization depends on the complexity of the task being parallelized.
For example, the complexity of the best sorting algorithms is O(Nlog(N)). If the table is split into N shards it takes 1/Nlog(N) of the time to sort all the shards simultaneously. The overhead is higher in that particular case, because the query layer has to perform the merge sort on the worker results, which is O(log(N)), but, in general, the more complex the task, the better the result of parallelization.
YugabyteDB has sharded its data since the very beginning. Over time we significantly improved the level of parallelism by scanning shards in parallel, filtering out unused columns, and applying filters at the storage layer when performing table and index scans. Our storage nodes can even do simple aggregation.
However, we were tied to individual table scans, until we integrated the Postgres Parallel Query feature. We will now dive into the details of how we achieved this.
Postgres Query Parallelism
Historically, Postgres is a monolithic DBMS. It runs on a single computer, does not shard data, and its query execution engine is a single process/single thread.
This architecture worked well enough initially, but when multi-core CPUs became the norm, developers began looking for a way to better leverage the computing power. One of these ways is to execute queries in parallel.
While not formally sharded, Postgres table data is stored in pages. A page is a good unit of parallel work. Pages are uniformly sized, data rows reside in only one page (no gaps or overlaps), and since pages are enumerated, it is easy to synchronize their processing as only an atomic counter is needed. To take another unit, workers atomically increment the counter, which returns the next page to work on. If the counter number is higher than the total number of pages, it means the work is done.
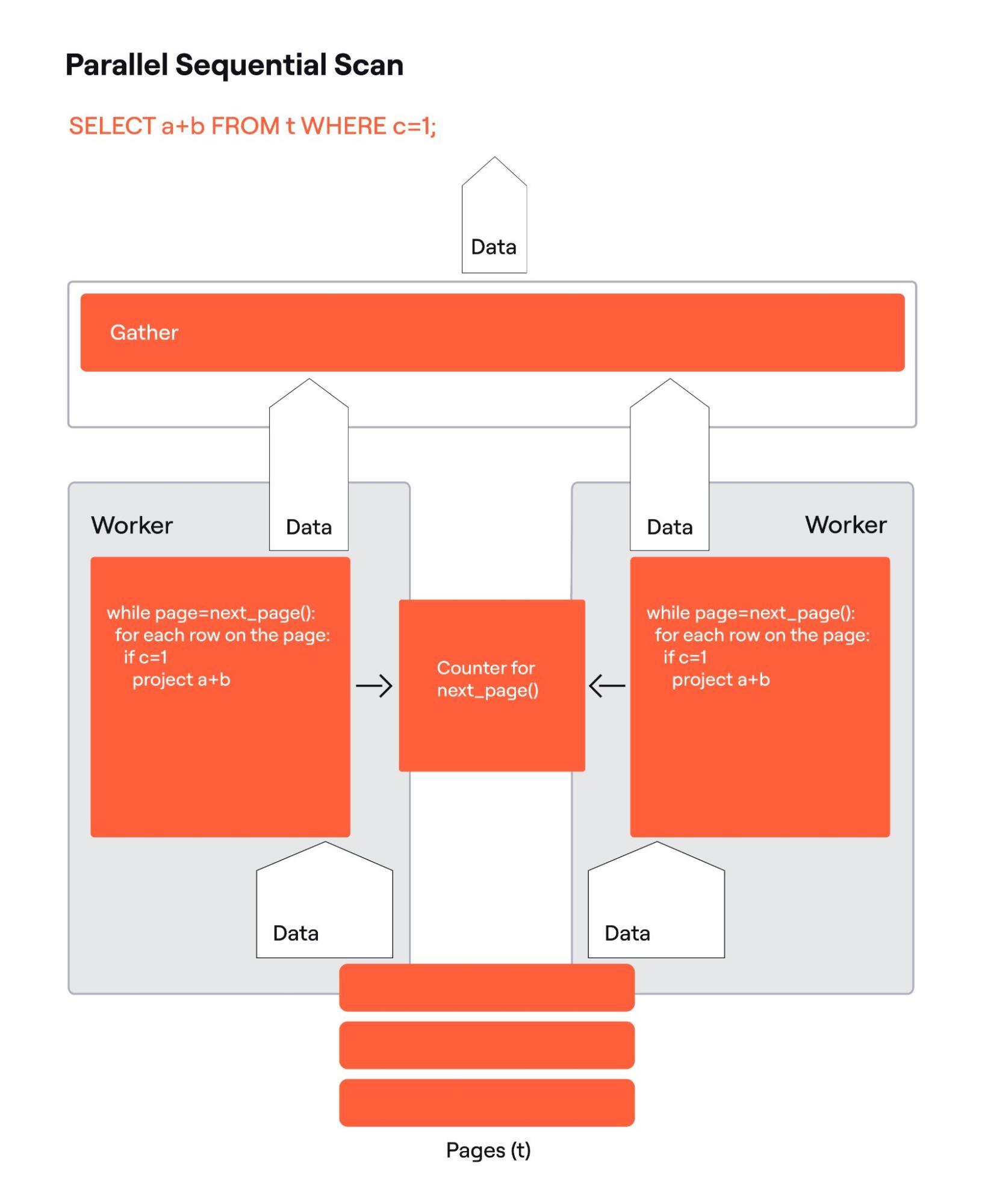
While the Postgres’ backend is a single process/single thread, Postgres is a multiprocess application, where each client connection is served by a separate process.
All processes have access to the table pages cache in the shared memory, and parallel workers have a block of shared memory to synchronize their work. In the case of parallel sequential scans, it is the atomic page counter. Fig. 4 shows Postgres parallel scan details. For simplicity, there are two parallel workers, but there may be multiple. The Gather node shown is to consolidate the data coming from the worker. Another (not pictured) responsibility of Gather is to set up processes to run the parallel workers.
Postgres processes are stateful. Transaction isolation is the most important part of the state. There are rules on what changes made by concurrent transactions the query should or should not see. There is the user, who may be authorized or not authorized to access specific data. There are configuration parameters that may affect the query. All these variables that make up the state have to be copied from the main process to the parallel workers. It is crucial to properly replicate the state to make sure the read is consistent. In other words, the result is the same, regardless of which process scanned a particular page. The correct replication of the state represented by values of multiple variables was a big problem that Postgres committers and maintainers had to solve.
Once it was solved, Postgres could run scans in parallel and also perform associated tasks like filtering and projecting. But could it parallelize more? The answer is yes.
To see how, let’s look at the regular Postgres query plans.
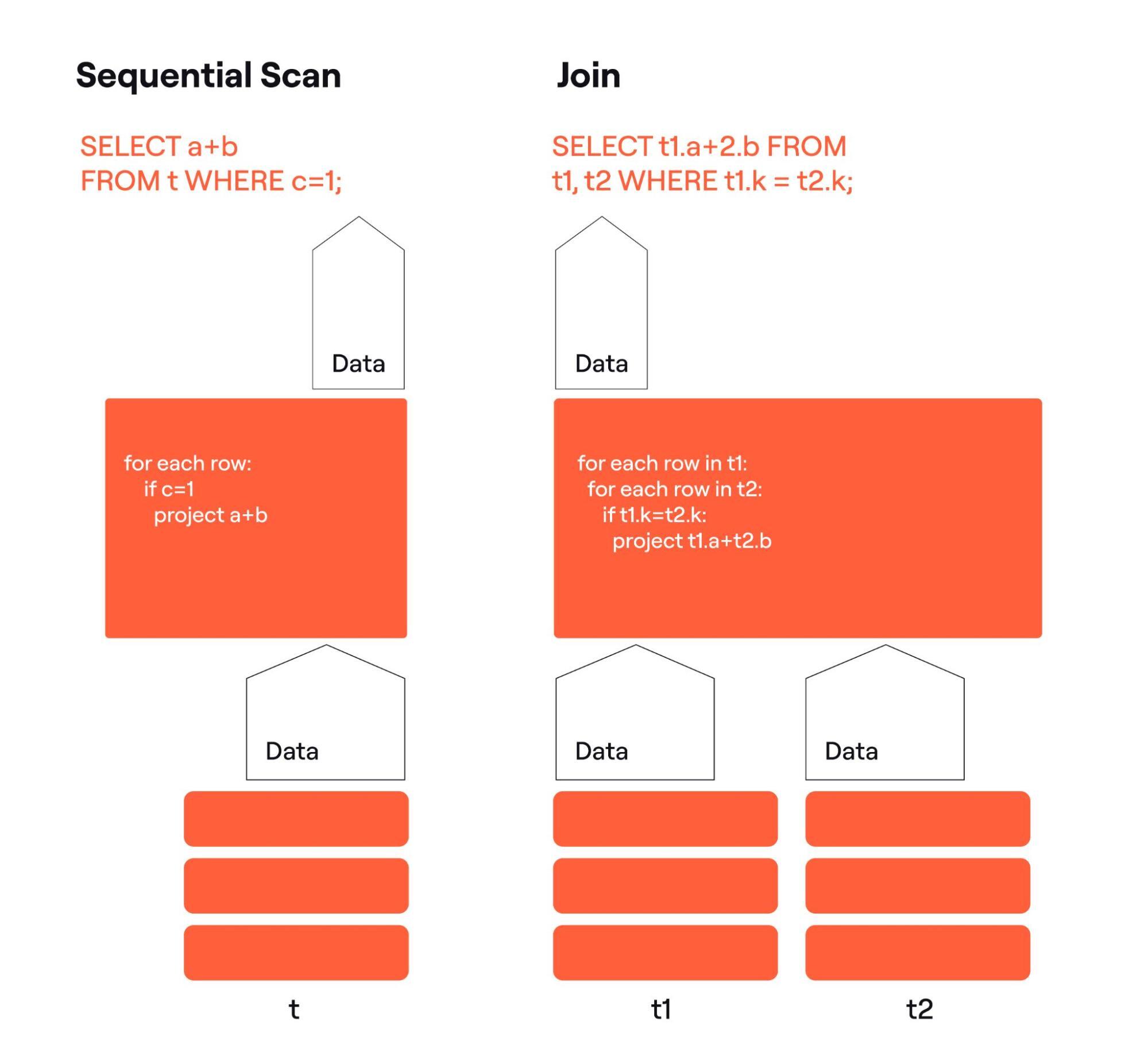
Let’s focus on the arrows representing data. The scan has one incoming arrow, the join has two. Both have one outgoing arrow. Those data streams are organized into columns and rows, so the scan and the join can process the rows and columns in certain ways. We will call these organized data streams ‘relations’.
Any Postgres plan emits a relation. Now look at the rectangles labeled t, t1, t2. They look like tables. But tables are organized into columns and rows, hence tables are relations. And we can substitute anything here, emitting a relation, a view, a set returning function, or another Postgres plan. By defining relation as an abstract collection of rows and columns, with just two types of plan nodes we can construct arbitrary complex query plans joining multiple tables.
Postgres has many other types of plan nodes: sort, aggregate, and even various scans and joins implementing different algorithms. The Gather node in Fig. 4 is a type of plan node too, so it can be used in Postgres query plans.
The data arrows underneath the Gather are also relations. But, they are special. When gathered, the relations emitted by the parallel plan nodes are equivalent to the relation emitted by a similar non-distributed plan. In a sense, a parallel plan shards the relation’s data. While all shards stay on the same node, they are like the shards of a distributed database.
Many Postgres plan nodes can be correctly used in a parallel plan. That means, if multiple instances of the plan node take a correctly “sharded” relation as an input, their output is a correctly “sharded” relation. This is equivalent to the relation that would be emitted by the same node if the input was a non-sharded relation. Some Postgres plan nodes, like Merge Join, can’t work correctly in a parallel plan. Some can work conditionally.
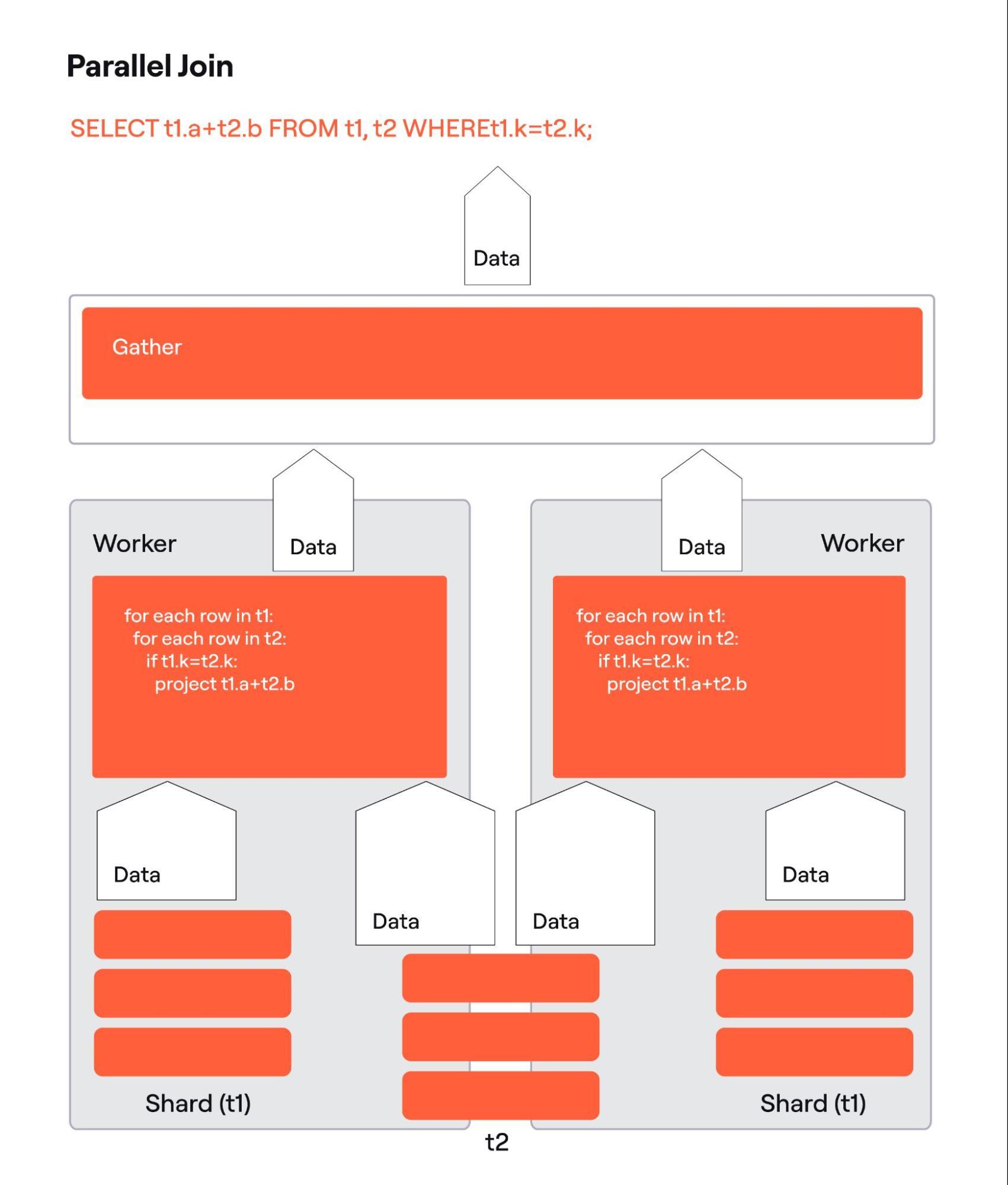
Fig. 6 shows a parallel join. The algorithm there is a Nested Loop implementation of an inner join. It is easy to see that if t1 is sharded, and t2 is not, the algorithm is correct as together all instances of the join find matches for every row in t1.
If Nested Loop implements an outer join, the algorithm would be still correct if t1 is on the outer side as we can tell if a row from t1 has no matches. But it would be incorrect, if t2 is on the outer side as if we have no matches for a t2 row on the local node, we can’t tell if t2 has matches anywhere else. Thus the Nested Loop algorithm is conditionally correct.
Why is Postgres Query Parallelism Useful for YugabyteDB?
Is Postgres parallelism better than one implemented in a distributed database like YugabyteDB? Frankly, no.
Postgres is still a single node DBMS and the available resources are those installed on the node – the same amount of memory and the same number of CPU cores. Distributed databases can spread the data between a virtually unlimited number of nodes, offering almost unlimited parallelism. Cloud databases, like YugabyteDB, can easily scale, adjusting the level of parallelism to meet demand.
However, Postgres parallelism is complementary to YugabyteDB parallelism in a couple of ways:
- YugabyteDB supports special kinds of tables, called colocated. Those tables are not distributed, they and their indexes share one tablet. Colocation works best for small tables, but there are cases when colocated tables are large. Postgres parallel query allows parallelization of processing of the colocated tables.
- When we mention parallel processing of distributed data in relation to YugabyteDB, we usually mean scans. We can do sequential or indexed scans in parallel, apply filters, and evaluate projections on matching rows. YugabyteDB supports simple aggregation. Postgres, however, can parallelize complex plans, including joining, sorting, hashing, and aggregating, and we want to support that in YugabyteDB as well.
How we Made it Work
It didn’t require much effort to enable Postgres parallel query in YugabyteDB. YugabyteDB’s query plan is a Postgres query plan. There are differences in the scans because YugabyteDB replaced the Postgres storage engine with its own distributed storage engine. However, we had to come up with our own way to divide tasks between the workers.
YugabyteDB storage is LSM-based, nothing like Postgres enumerated pages. We decided to use the LSM index to build a sequence of keys with approximately equal amounts of data between the adjacent keys.
A large table may have too many blocks of the given size, and therefore return too many keys. So, we implemented a storage layer function, which can return the keys in pages.
It takes the starting key as a parameter, and fetches the keys until it reaches the key limit, data size limit, or the end of the table. The keys are placed in the shared memory buffer, where they are accessible by the workers.
When a worker needs the next block of work, it removes the first key from the buffer and copies the second. Those keys become respectively lower and upper bounds of the scan. If a worker finds the number of keys in the buffer is running low, it stops its scanning work to fetch the next page of keys from the storage layer. The last key in the buffer becomes the starting key, and the worker can estimate the limits for the next page size and the number of required keys based on the free space in the buffer. When a response arrives, the worker puts the keys in the buffer and continues with the scan work.
The worker needs to lock the shared memory buffer to take a key range or add more keys. A larger buffer is required to make fewer key requests. Together with the need to fetch keys from the storage layer, the Postgres parallel query in Yugabyte requires significantly more overhead than Postgres’ atomic counter.
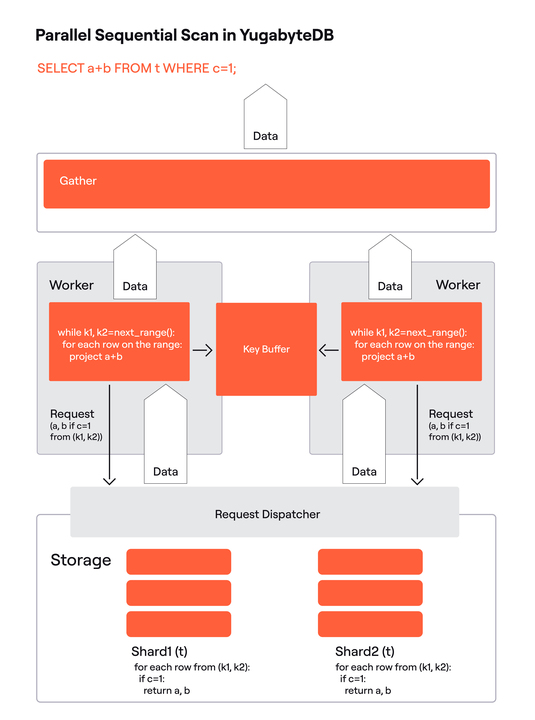
Fig. 7 shows YugabyteDB’s parallel scan. Compared to the Postgres implementation in Fig. 4, there is a key buffer (the key buffer’s fill up process is not shown) in place of the counter, and the storage is remote and distributed.
In addition to the distributed sequential scan shown in Fig. 3, there is a request dispatcher that finds the target shard by the request’s range. The request dispatcher is shown to emphasize the fact that a worker may get a range from any shard. It had existed before we integrated parallel queries, but its usage was limited. Basically, if the query had a condition on the key columns, the request dispatcher could filter out some shards.
It is easy to see that the YugabyteDB scan on a distributed table satisfies the definition of the Postgres parallel plan, and therefore can be integrated with the Postgres parallel query.
An additional challenge was to transfer the transaction state from the main backend to background workers. Postgres copies a transaction ID and snapshot, but in YugabyteDB transactions are distributed, and their state, as well as MVCC visibility data are different from Postgres. We had to properly copy that data to the background workers to ensure all workers are transactionally consistent.
Next Steps
The Parallel Postgres feature is now available for colocated tables. Please watch our recent YFTT Episode for more insight and a demo.
In our tests using two background workers, we’ve already achieved over 2x performance gain in some queries. The next step is to support hash and range distributed tables. We also need to better cost parallel scans, so the optimizer makes better choices when multiple options are available.
In the longer term, we would like to be able to send parallel subplan instances to other nodes. That would allow us to use more workers and increase parallelism. Stay tuned for our next update!
To find out more about the powerful new capabilities and architectural enhancements introduced in YugabyteDB 2024.1 to achieve enhanced Postgres compatibility, check out our latest release page.


