Presentation Recap: Modernizing Application Development with GraphQL and Distributed SQL
October 30, 2020
At the Distributed Summit 2020 , Allison Kunz, Solutions Engineer at Hasura, presented the talk “Modernizing Application Development with Planet-scale GraphQL and Distributed SQL”. In the talk she covered what is GraphQL, why GraphQL, why Hasura GraphQL Engine, and a checklist of what it takes to have enterprise-grade GraphQL APIs in production, focusing on performance, security, and reliability. She also showed a demo of Hasura Cloud in action.
What is GraphQL, and why GraphQL?
In her talk, Allison defines GraphQL as an API spec, like REST or SOAP. Originally created by Facebook, GraphQL was open sourced in 2015 and is now guided by the independent GraphQL foundation. It is data source agnostic, growing in popularity, and is supported by an enthusiastic community. The community is enthusiastic because of the many benefits GraphQL provides, such as automated documentation and auto-suggestion while writing queries, elimination of over-fetching of data, and reduced friction on both the frontend and backend supporting modern data-driven services. All of these benefits are great, especially for highly interconnected data and mobile applications.
 A few benefits of using GraphQL and resources to learn more
A few benefits of using GraphQL and resources to learn more
The n + 1 problem
To highlight why the Hasura GraphQL Engine is a popular choice, Allison walks us through the “n + 1 problem”. Allison explains that if you take a look at a simple query to list artists and their albums, a naive approach is to query the database for the list of artists and then query again for the list of albums for each artist. If there are n artists, then there are n + 1 total database requests to resolve this query. Another approach is to implement a data loader service, which batches the n album requests into a single request. However, as queries grow in complexity, as in the case of a real-world application, this problem presents a real challenge. The naive approach gets exponentially expensive; the data loader approach reduces to linear growth, but Allison notes that we can do even better.
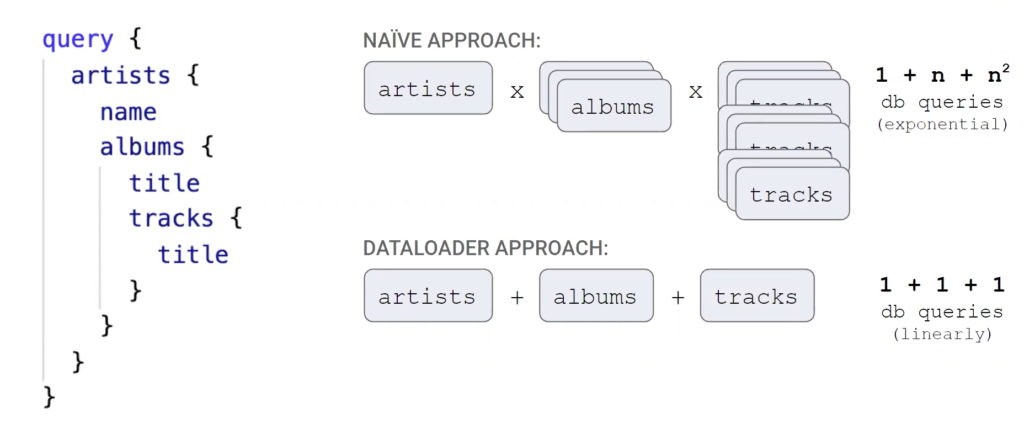 The n plus 1 problem
The n plus 1 problem
A different approach: Under the hood of the Hasura GraphQL Engine
If we look at what it takes from a SQL perspective to provide the data for that query, it’s simple and SQL already has ways to optimize the execution and response. Allison notes that this is where the Hasura GraphQL Engine comes in and why its performance is so fast: the query is parsed and then compiled into a SQL statement, which PostgreSQL can handle easily with its decades of experience and optimizations, as well as PostgreSQL-compatible databases like YugabyteDB. The compiler approach allows for additional opportunities as well, like automated caching and extensibility, plus Hasura GraphQL Engine is open source and works with many of your favorite tools out of the box.
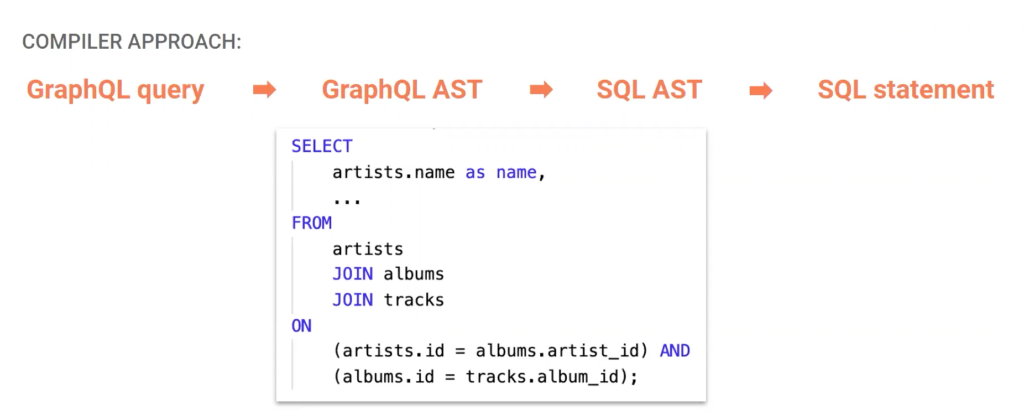 A different approach: Don’t resolve, instead compile
A different approach: Don’t resolve, instead compile
A checklist for enterprise-grade GraphQL APIs
With globally-distributed applications that are enabled by distributed databases like YugabyteDB, deployments are global and data can be everywhere. In this environment, your GraphQL service also has to have that kind of scale, as well as other enterprise-grade capabilities before it is truly production worthy. To get this to large-scale, enterprise-grade GraphQL API, you will want to have your databases and the GraphQL API services co-located and distributed globally, and scalable as well. Allison walked us through a checklist for enterprise-grade GraphQL APIs, focusing on performance, security, and reliability, and how to achieve the desired outcomes in Hasura GraphQL Engine. She ended with a demo of Hasura Cloud and resources to learn more.
 GraphQL production checklists
GraphQL production checklists
Want to see more?
Check out all the talks from this year’s Distributed SQL Summit including Pinterest, Mastercard, Comcast, Kroger, and more on our Vimeo channel.


