Real-Time Decision-Making: How Event Streaming is Changing the Game
October 3, 2023
Businesses today generate a lot of data—from customer interactions and financial transactions to sensor outputs and machine data. The evolving opportunities for businesses have reshaped our view of data—from mere entries in a database that are quickly forgotten to real-time* streams of events that are immediately turned into revenue-generating services.

These real-time streams, often referred to as streaming data or event streaming, are a continuous, unbounded (meaning there’s no beginning and no end) flow of data generated from various sources.
*The definition of “real-time” depends on the use case and industry. In some cases, it means “immediate.” For most data streams, it usually ranges from a few seconds to 15 minutes to an hour, depending on the data and its intended use.
Types of Streaming Data
Streaming data can be regular, such as sensor readings that happen at regular intervals, say every 5 or 15 seconds. It can also be irregular, like ATM transactions that happen whenever someone walks up to the machine and makes an inquiry or transaction. Each type of data stream requires a different type of structure in the database. Some are best with NoSQL and some are better served by a SQL database. The good news is that YugabyteDB can handle both.
The Evolution of Streaming Data
Streaming data has been around for a long time, but it would often be discarded or, if something was out-of-bounds, immediately acted upon without being stored. What distinguishes today’s landscape of streaming data is the ability to aggregate and capture this data in discrete packets (or vents) and then store it to derive some immediate business value from it. Companies across all different industries, from financial to retail to automotive, are building new services and business opportunities that leverage this continuous stream of data.
Wide-Ranging Use Cases for Event Streams
The capability to not only capture but also store and analyze data in real time has led to numerous use cases that span various industries. For instance, because companies can capture and act upon data generated by customers, they can drastically improve their ability to engage with them.
In the IoT space, the massive amounts of data generated by sensors across the globe can be aggregated and acted upon almost instantaneously, providing invaluable feedback loops for businesses.
Financial metrics and stock behaviors can also be tracked and analyzed in real time, enabling rapid decision-making.
Retailers, too, benefit from streaming data. For example, by having real-time insight into inventory levels, they are able to reduce the overhead of on-hand inventory and even mitigate the risk of theft and fraud.
Benefits of Event Streaming
Companies are increasingly adopting streaming data systems for several reasons.
- Quick Decision-Making. These systems change the paradigm of how businesses consume data. Instead of relying on batch jobs that run overnight or even weekly, companies can now access and analyze their data in near real time, allowing them to make immediate, data-driven decisions.
- Proactive Monitoring. Event streaming enables proactive monitoring. Companies can set thresholds for specific metrics and receive immediate alerts when those thresholds are crossed. Decisions are then made that can drive needed outcomes more efficiently.
- React to New Customer Needs. Continuous data monitoring means that companies can keep an eye on how consumers are interacting with their products. This offers them the ability to detect changing patterns and sentiments over time, leading to more informed business strategies.
- Long-Term Monetization Strategies. Aggregated and stored data can be analyzed to identify long-term trends, giving businesses additional data points to make more informed decisions. Additionally, there is the potential to monetize this stored data, opening up new avenues to increase revenue and develop new business channels.
Challenges in Implementing Streaming Data Systems
Streaming data systems do come with their share of challenges. One major issue is that traditional, legacy databases and frameworks often cannot handle the speed and scale needed to process event streams. Achieving data consistency and transactional ordering in a distributed real-time system is difficult due to the sheer speed and volume of data. These systems also need to offer features like parallel processing, fault tolerance, high write throughput, and resilience to meet the demands of mission-critical operations.
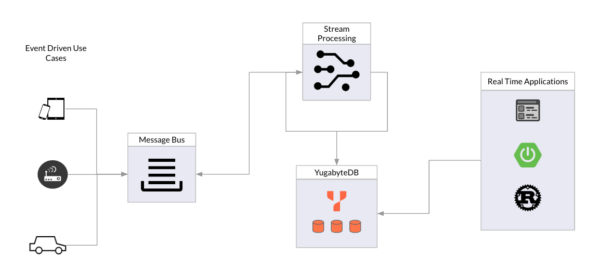
What Does a Modern Streaming System Look Like?
In a simplified view, a modern streaming system is made up of three key components.
- Event sources are anything that generates data (i.e. events) that the system is interested in. These could be anything from smartphones and IoT devices to plant equipment to firewalls and routers.
- Event processor, which ingests, processes, and aggregates the data. It then stores this data in a persistent storage unit. NOTE: YugabyteDB is perfectly suited for the storage of both the real-time event sources as well as the aggregate sources that are generated from the event processing system.
- Event consumers are the upstream applications or any external systems interested in the processed or raw streaming data, such as APIs or mobile applications.
A key characteristic of modern streaming and event data is the need for high write throughput. When reads are performed on the data, they are typically range queries for an entity.
Explore YugabyteDB for Event and Streaming Data>>>
The Role of Flexible Schemas
It’s crucial that the database is able to process diverse and flexible data types, such as JSON and varying schemas. Take, for example, a factory equipped with 20 different types of machinery. Each machine generates a status, but these statuses aren’t uniform; they differ from machine to machine.
Instead of managing 20 individual data streams for each machine, which can be cumbersome and inefficient, the ideal scenario would be to have a single, unified data stream for the entire factory. This stream would funnel into your architecture as key values in a JSON object. The database should be capable of fully processing this JSON data in real time to serve your applications. That’s the kind of flexibility and efficiency we expect from modern databases.
The Role and Complexity of Streaming Data at the Edge
Another layer of complexity arises when event sources are in remote locations, such as plant equipment or a store’s POS system. There’s a lot of benefit to being able to process these streams locally—at the edge—and then send the aggregate data up to a consolidated cluster for analysis, further processing, etc.
For example, you may have plant machinery that’s producing telemetry data across several locations. Each plant could have a YugabyteDB cluster and stream processing system to process this data at the edge. By using Yugabyte’s synchronous and asynchronous replication, this data can then be funneled to a central YugabyteDB cluster for further analysis and integration into other systems.
Moving the data from local clusters to the consolidated cluster mainly leverages our database’s SQL-driven asynchronous mechanisms. It’s a powerful feature that pools data from multiple edge locations into one unified system, essentially acting like a single table across all your sites. This introduces a new architectural approach, letting you integrate and use the data as if it’s coming from one table, despite each remote location having its own table set.

Explore how to best design data architectures for stateful edge applications and why distributed SQL database are a top choice for those transactional applications. Download eBook: Stateful Applications At The Edge
Final thoughts….
Data management is undergoing a seismic shift, with real-time event streaming at its core. YugabyteDB is positioning itself as a versatile, efficient solution to meet both current and future demands in this rapidly evolving space as a database solution for ecommerce and retail.


