YugabyteDB and Red Hat OpenShift: Resilient Kubernetes Workloads at Scale
June 10, 2022
Kubernetes has become widely adopted in the Fortune 500. Many companies are now using the platform to run stateless and stateful applications on-premises or as hybrid cloud deployments in production. Of course, with any new technology, there are growing pains when running resilient Kubernetes workloads. But most executives and developers agree that the benefits far outweigh the challenges.
Data on the Kubernetes ecosystem is evolving rapidly with the rise of stateful applications. However, stateful applications demand a new database architecture that takes into account the scale, latency, availability, and security needs of applications. But how do you know which database architecture is best equipped to handle these challenges?
In this blog post, we’ll explore why YugabyteDB and Red Hat OpenShift are an ideal combination to ensure Kubernetes deployments are resilient and continuously available.
YugabyteDB: distributed SQL for resilient Kubernetes workloads
YugabyteDB is a cloud native distributed SQL database for transactional applications. The database solves availability and resiliency challenges when running application workloads on Kubernetes while being 100% open source.
This database functions as a single logical database deployed as a cluster of nodes. This means the database cluster takes care of sharding, replication, load balancing, and data distribution. Therefore, YugabyteDB keeps your database up and running even if there’s a pod, node, or underlying infrastructure failure. The database cluster is able to detect the failure, handle it, and recover without any loss of data or access by the application.
YugabyteDB also provides a scalable and resilient data store for connecting applications. It takes care of migrating data between pods after a pod moves to a new node. It does this behind the scenes without any form of operator intervention.
“Run Anywhere” distributed stateful workloads
YugabyteDB is available on Red Hat OpenShift, the industry’s leading enterprise Kubernetes platform for deploying and managing cloud native applications. This means development teams can deploy YugabyteDB on Red Hat OpenShift with confidence. As a result, both are well-integrated to run on Kubernetes and enable efficient Day 1-2 operations.
One major benefit to running YugabyteDB on Red Hat OpenShift is geo-distributed stateful workloads. The below diagram depicts what such an architecture looks like in practice.
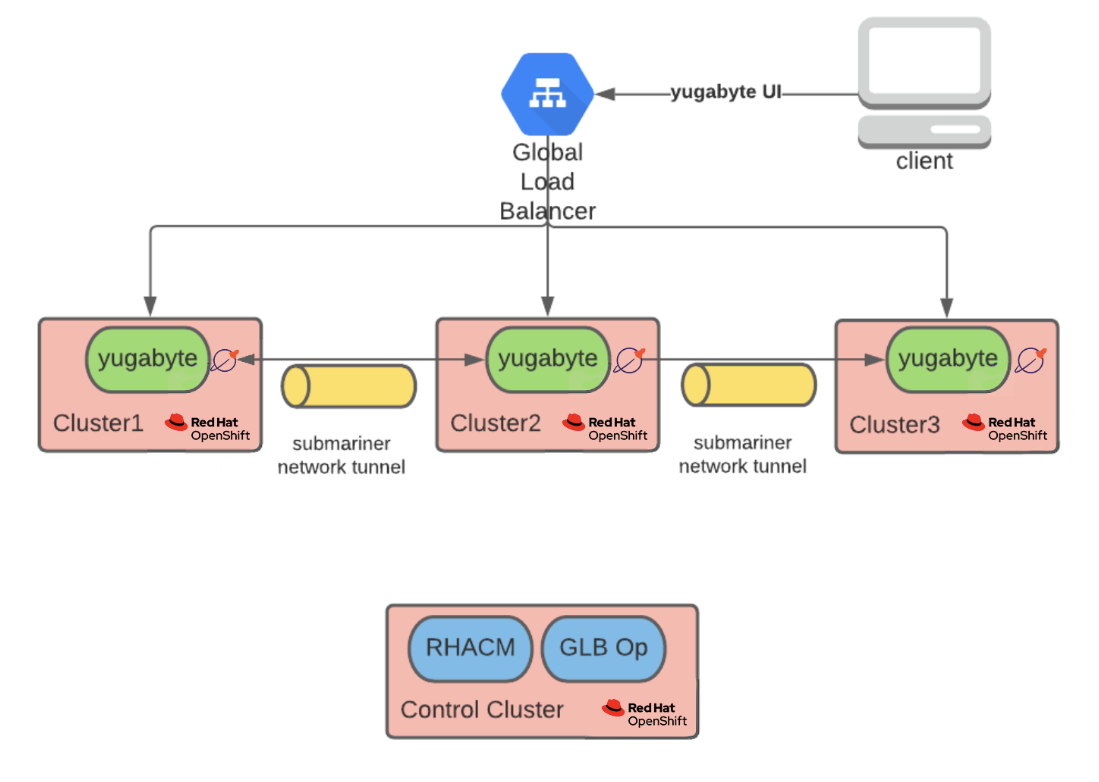
Starting from the top, we have a global load balancer directing connections to the YugabyteDB UI. Then, there are three Red Hat OpenShift clusters with YugabyteDB instances deployed to each cluster. These instances can communicate with each other via a network tunnel implemented with Submariner.
Finally, at the bottom of the diagram, Red Hat Advanced Cluster Manager for Kubernetes exists within a control cluster. This creates the other clusters along with the global load balancer operator, which facilitates configuring the global load balancer at the top of the diagram.
Each cluster is in a different region of a public cloud provider.
Zooming in on the YugabyteDB deployment, we have three tablet servers and a master (metadata server) in each cluster. Together, they form a logical YugabyteDB instance.
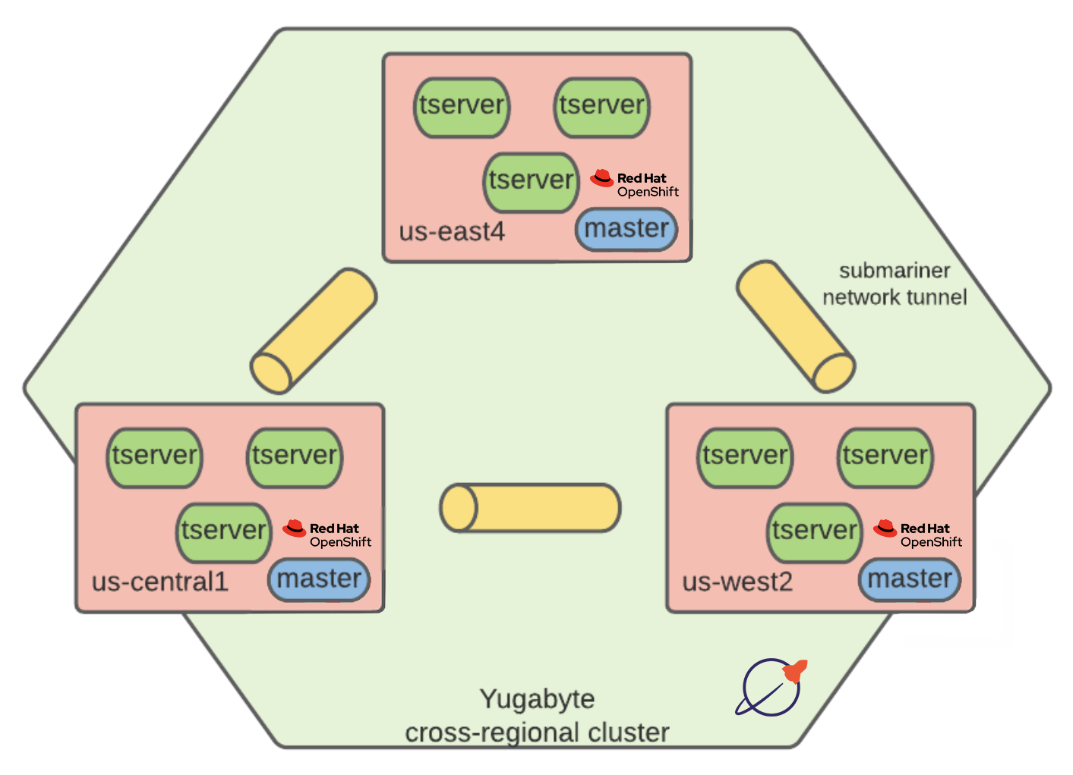
Load test results reveal this kind of deployment is usable in production, as shown by the integration work done between Yugabyte and Red Hat in this Geographically Distributed Stateful documentation.
Zero data loss and continuous availability
Another benefit to running YugabyteDB on OpenShift is zero data loss and continuous availability during a major system outage or natural disaster.
For example, in the below diagram, the network of one region prevents any inbound or outbound traffic while running a TPC-C test.
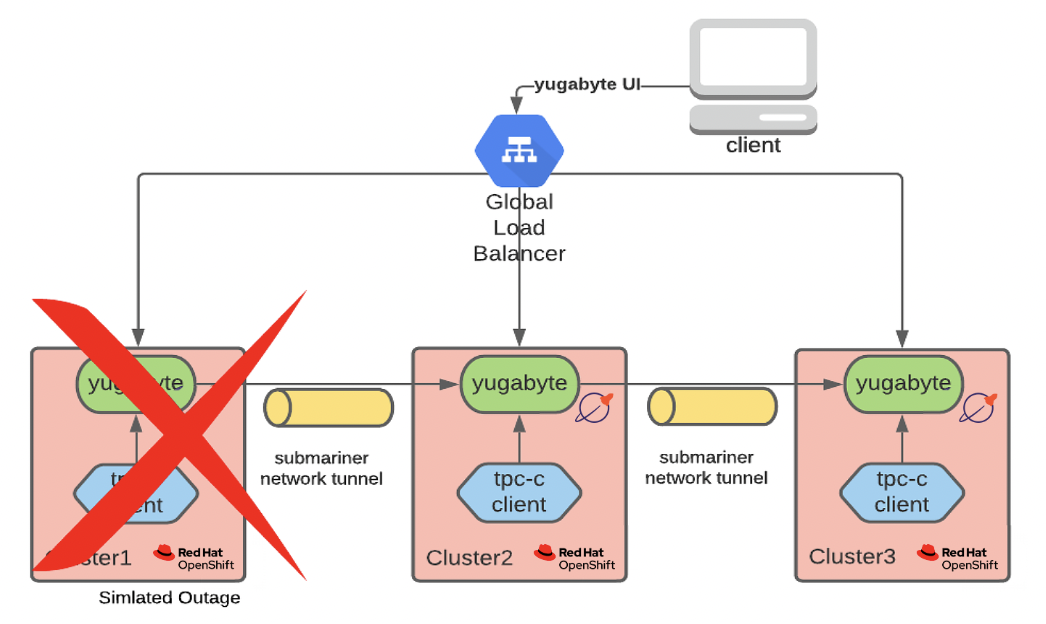
When simulating this disaster, there were a few errors in the surviving TPC-C clients; essentially, some in-flight transactions failed to complete. But YugabyteDB moved all of the tablet leaders to the healthy instances.
The system managed the disaster without the need for any human intervention.
When connectivity to the isolated region came back online, there were no issues within the ongoing TPC-C clients. YugabyteDB rebalanced the database by moving the tablet leaders back to the newly-available tablet servers. Again, no human intervention needed.
During this simulation, the system experienced zero data loss (RPO 0) and very little unavailability (RTO measured in seconds).
Resilient Kubernetes workloads are the future
Kubernetes has been a paradigm shift in the way enterprises build and deploy applications to cater to the needs of an increasingly cloud native world. There is no one-size-fits-all database reference architecture that works for all applications in this environment. Depending on the requirements of the application and tradeoffs involved, enterprises will choose different topologies to meet their needs, and change the topologies when needs change.
YugabyteDB on Red Hat OpenShift provides a powerful and versatile data layer for running applications in both the cloud and Kubernetes environments. This combination serves business-critical applications with SQL query flexibility, high performance and cloud-native agility. As a result, YugabyteDB on Red Hat OpenShift allows enterprises to focus on business growth instead of complex data infrastructure management.
Discover how to achieve stateful workloads and zero data loss in our white paper, Running Resilient Databases on Red Hat OpenShift. Download your copy today!


