Scaling a Hasura GraphQL Backend with Distributed SQL
April 7, 2020
GraphQL is taking the modern development world by storm having been adopted by companies like Facebook, GitHub and Intuit because it solves many of the common problems developers encounter when working with REST APIs. For example, it solves issues like overfetching (getting more data than your response needs) and underfetching (having to make multiple fetches to get all the data you need), or when consolidating API responses on the client is necessary. When a developer follows the GraphQL spec, it means they have typed schema on the server that defines the exact structure of their API. Another advantage of GraphQL is that it gives us a single API endpoint and query language so we can query any data that we need from the client without introducing a lot of new API endpoints.
Creating a GraphQL backend can be tough. Creating it with real-time capabilities in mind is even tougher. And scaling a GraphQL backend can be really tough. Luckily there are free and open source projects like Hasura that solve lots of these problems. The Hasura engine is a compiler that runs on top of PostgreSQL and compiles your GraphQL query language into better performing SQL statements while leveraging the best features that PostgreSQL has to offer.
In a nutshell, the Hasura engine auto generates a GraphQL CRUD API, provides an eventing system to trigger serverless functions, can stitch other GraphQL servers inside the engine, has a permission system built-in, auth, and more. For a deeper dive, check out some of my blog posts on Hasura, including Effortless Real-time GraphQL API with Serverless Business Logic. There are also a few Twitch streams on twitch.tv/vnovick that you can check on my YouTube channel.
Initially, scaling Hasura involves stitching multiple Hasura instances together, however, this does not solve the problem of how to scale our database.
So, what are the challenges we will likely encounter with scaling the database? Because modern apps need to support users worldwide, we need a database that is geo-distributed, fast, supports transactions, and can scale up or down without incurring any downtime. By employing a database with these characteristics, data will always be available, and the operations team won’t have to architect external systems and processes to handle scaling, fault tolerance, multi-region asynchronous replication, and so on.
Introducing YugabyteDB
YugabyteDB is an open source, high-performance distributed SQL database for powering global, internet-scale applications. Built using a unique combination of a high-performance document store, per-shard distributed consensus replication and multi-shard ACID transactions (inspired by Google Spanner), YugabyteDB serves both scale-out RDBMS and internet-scale OLTP workloads with low query latency, extreme resilience against failures and global data distribution.
YugabyteDB is also a cloud-native database, so it can be deployed across both public and private clouds, including Kubernetes environments. In regards to serving as a backend for microservices, YugabyteDB brings together three must-haves: a PostgreSQL-compatible SQL API, low-latency read performance, and globally distributed write scalability.
Getting started with YugabyteDB
To get started head on over to: https://docs.yugabyte.com/preview/quick-start/
Note: For the purposes of this blog post, I will be running YugabyteDB locally on my Mac, but you can run on any of the major cloud providers. Look for additional blog posts from me on this topic in the future.
Get started on Mac
I will follow the relevant docs section with the following steps:
Check the prerequisites
Make sure you check the prerequisites for your machine before you venture forward. Like the Python version and increasing the maxfiles limit. These are described pretty well here.
Download YugabyteDB
Download the YugabyteDB tar.gz file using the following wget command.
wget https://downloads.yugabyte.com/yugabyte-2.1.2.0-darwin.tar.gz
To unpack the archive file and change to the YugabyteDB home directory, run the following command.
tar xvfz yugabyte-2.1.2.0-darwin.tar.gz && cd yugabyte-2.1.2.0
Adding loopback addresses
In our example I want to create a YugabyteDB cluster with 3 nodes. Since these nodes will be running on localhost, I want to add six loopback addresses by running the following:
sudo ifconfig lo0 alias 127.0.0.2 sudo ifconfig lo0 alias 127.0.0.3 sudo ifconfig lo0 alias 127.0.0.4 sudo ifconfig lo0 alias 127.0.0.5 sudo ifconfig lo0 alias 127.0.0.6 sudo ifconfig lo0 alias 127.0.0.7
Create a local cluster
Now it’s time to create a local cluster. In an unpacked Yugabyte folder I will run the following:
./bin/yb-ctl create --rf 3 --tserver_flags "ysql_suppress_unsupported_error=true"
This will create a distributed SQL cluster with 3 nodes. Note that I’ve added --tserver_flags
After I’ve created my cluster, I can now run
./bin/yb-ctl status
to check my cluster status.
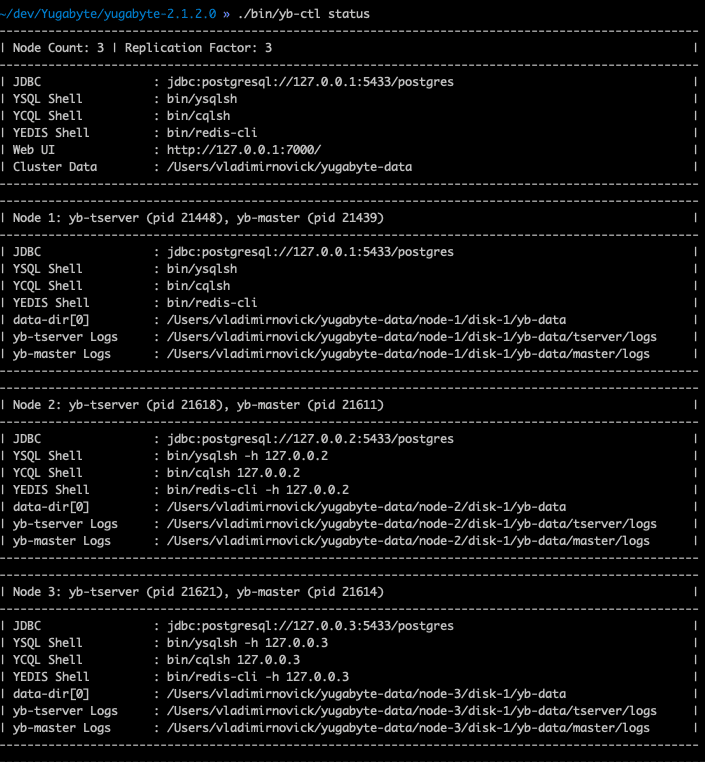
There is another option to check our cluster with the Admin UI, which is automatically exposed by Yugabyte on localhost.
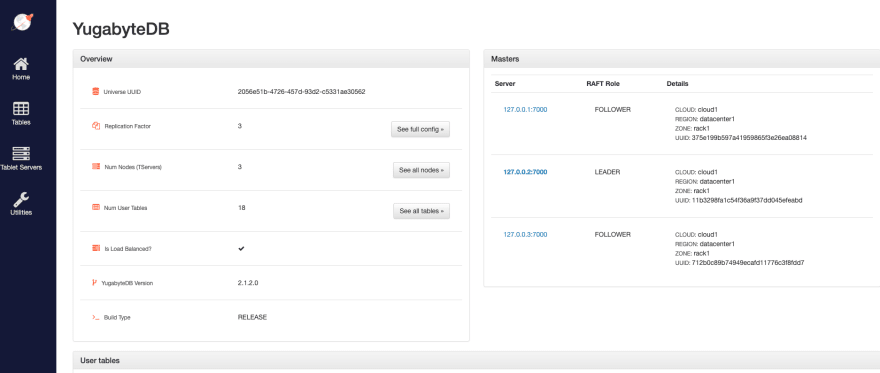
You can go to https://127.0.0.1:7000 for the YB-Master UI where you will see the:
- List of tables present in the cluster
- List of nodes (aka YB-TServer servers) present in the cluster
- List of utilities available to debug the performance of the cluster
You can also access each tablet server individually by selecting the Tablet Servers menu option and accessing each server admin link.
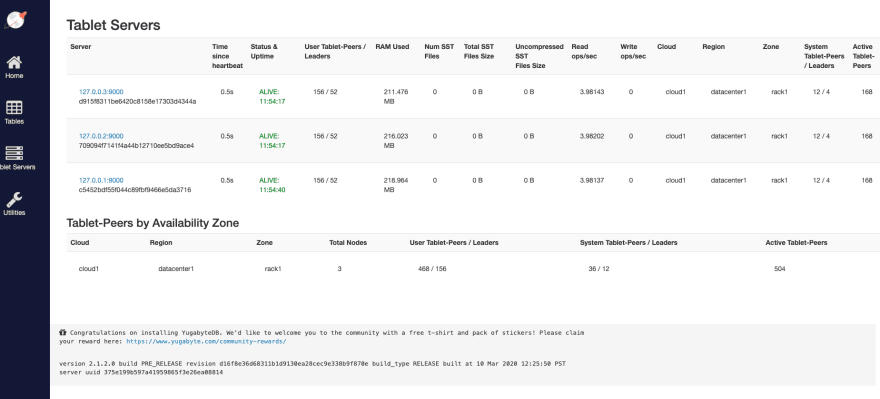
For example if I want to access the second tablet server admin UI, I can go to https://127.0.0.2:9000/.
Running Hasura on top of Yugabyte
Now that I have YugabyteDB running, let’s set up Hasura on top of it.
I can either go to the Docker Deploying section in the Hasura docs and follow the instructions or just simply run the following command:
docker run -d -p 8080:8080 -e HASURA_GRAPHQL_DATABASE_URL=postgres://postgres:@host.docker.internal:5433/yugabyte -e HASURA_GRAPHQL_ENABLE_CONSOLE=true hasura/graphql-engine:latest
You can notice that HASURA_GRAPHQL_DATABASE_URL points now to postgres://postgres:@host.docker.internal:5433/yugabyte.
Hasura migrations
We want to be sure that when we destroy our cluster, we will be able to recreate database changes that we will do through the Hasura console. In order to recreate these changes, we will make sure Hasura will write migration files whenever we change database schema in the console. (You can read more about migrations here.) In order to do that we will run hasura init in any folder of our choice (typically project folder) and then run:
cd hasura hasura console
That will bring up our Hasura console:
From that point on any changes done in the console will write migration files. If for some reason (or for cleanup) I need to destroy my cluster, I will always be able to recreate the database schema just by running hasura migrate apply.
Testing CRUD
Now I will create a simple blog post API below. You can also find videos of this on my YouTube channel.
Let’s try to run the following queries in the Hasura console:
mutation insertPost {
insert_posts(objects: {user: {data: {name: "Vladimir Novick"}}, title: "First blog post 1", content: "Content"}) {
returning {
user {
id
}
id
}
}
}
mutation updatePost($id: uuid!) {
update_posts(where: {id: {_eq: $id}}, _set: {title: "First blog post"}) {
affected_rows
}
}
mutation deletePost($id: uuid!) {
delete_posts(where: {id: {_eq: $id}}) {
affected_rows
}
}
query getPosts {
posts {
title
content
user {
name
}
}
}
subscription getPostsSub {
posts {
title
content
user {
name
}
}
}
It looks like all of them work just perfectly.
Simulate downtime with active subscriptions
Now let’s simulate downtime while having an active GraphQL subscription running. For that we will run the following GraphQL subscription in the Hasura console.
subscription getPostsSub {
posts {
title
content
user {
name
}
}
}
Now head to the terminal in the Yugabyte unpacked tar folder and execute:
./bin/yb-ctl stop_node 3
This will stop one of the nodes of the Yugabyte cluster, but our GraphQL subscription will keep working. Only if we stop node 2 as well, we will get an error. This is because YugabyteDB is configured with Replication Factor 3 that allows it to tolerate one infrastructure failure automatically. We have simulated a node failure here but such failures can also include disk, network, availability zone, cloud region/datacenter, or even entire cloud (for a multi-cloud cluster configuration).
So basically if 2 out of 3 nodes are failing we will get an error.
{
"data": null,
"errors": [
{
"errors": [
{
"extensions": {
"path": "$",
"code": "unexpected"
},
"message": "postgres query error"
}
]
}
]
}
Now let’s start node 2 again. Almost immediately our subscription will continue working.
Summary
As you’ve seen in this blog post, getting started with YugabyteDB and integrating it to work with Hasura is straightforward. When you combine these two technologies you get all the benefits of GraphQL’s efficiency and performance when dealing with APIs plus the scale and availability of a YugabyteDB backend.
YugabyteDB with its global data distribution brings data close to users for multi-region and multi-cloud deployments. It is a self-healing database that tolerates any failures, which we’ve just seen in our example.
Finally, recall that everything I’ve shown in this blog post is open source, so there is no proprietary code, licenses or trial periods to hold you back from developing with GraphQL and a YugabyteDB backend!


