Presto on YugabyteDB: Interactive OLAP SQL Queries Made Easy
This post describes how you can run Presto queries on YCQL API as well as join data across the YCQL and YSQL APIs.

This post describes how you can run Presto queries on YCQL API as well as join data across the YCQL and YSQL APIs.

MongoDB’s “schemaless” JSON data modeling was initially attractive to web app developers looking to escape the constraints of traditional relational databases, but issues with data durability and ACID transactions have been a consistent challenge. While the recent MongoDB 4.0 release includes multi-document transaction support, this post explores where the platform falls short for transactional, high performance apps.

In this post, we will look at the architecture of YSQL, the PostgreSQL-compatible distributed SQL API in YugabyteDB. We will also touch on the current state of the project and the next steps in progress. Here is a quick overview:
…

YugaByte has introduced YSQL, a PostgreSQL-compatible distributed SQL API in YugabyteDB’s 1.1 release. This architecture enables developer agility, operational simplicity, and scalability, addressing the needs of fast-growing online services and cloud-native deployments.
Prof. Daniel Abadi, lead inventor of the Calvin transaction management protocol and the PACELC theorem, wrote a thought-provoking post last month titled “NewSQL database systems are failing to guarantee consistency, and I blame Spanner”. The post takes a negative view of software-only Google Spanner derivative databases such as YugabyteDB and CockroachDB that use Spanner-like partitioned consensus for single shard transactions and a two phase commit (2PC) protocol for multi-shard (aka distributed) ACID transactions.
…
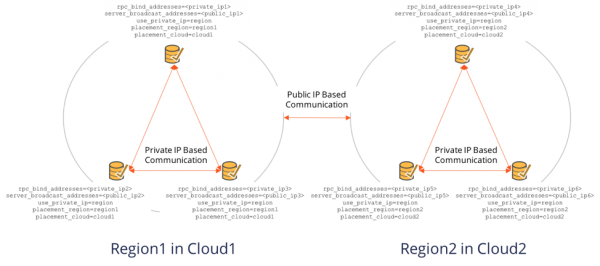
Welcome to another post in our ongoing series that highlights new features from the latest 1.1 release announced last week. Today we are going to look at the importance of public IP addresses and hostnames in simplifying multi-cloud and hybrid cloud deployments.
In modern cloud deployments, servers often have a combination of private IP addresses (used in the private LAN and often the IP address of the network interface on the server),
…
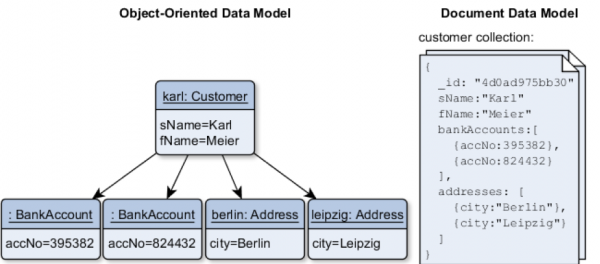
Welcome to another post in our ongoing series that highlights new features from the latest 1.1 release announced last week. Today we are going to look at document data modeling using the native JSON data type available in YugabyteDB’s Cassandra compatible YCQL API. Note that this data type is specific to YugabyteDB and is not part of the standard Cassandra Query Language (CQL).
With YugabyteDB’s native JSON support,
…
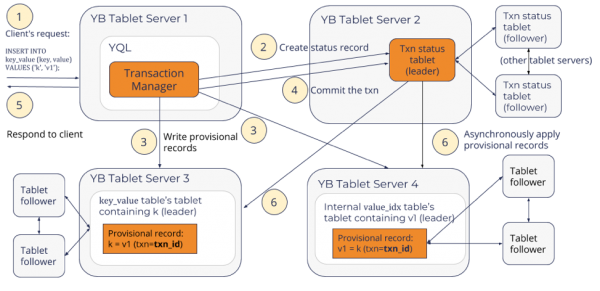
Welcome to another post from our ongoing series where we highlight a new feature from the latest 1.1 release! Today we are going to look at secondary indexes.
A database index is a data structure that improves the speed of data retrieval operations on a database table. Typically, databases are very efficient at looking up data by the primary key. A secondary index can be created using one or more columns of a database table,
…
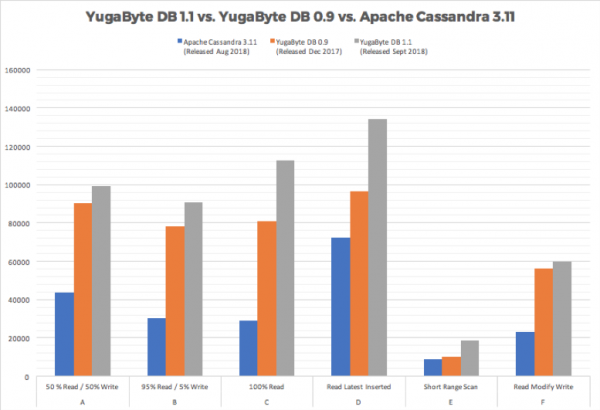
We announced the general availability of YugabyteDB 1.1 earlier this week. This post gives you a deep dive into the various features of YugabyteDB 1.1.

The team at YugaByte is excited to announce that YugabyteDB 1.1 is officially GA! You can download the latest version from our Quick Start page. New in this release:
…