YugaByte Database Engineering Update – Nov 27, 2018
November 27, 2018
Lots has happened since our last engineering update about 3 months ago. Below are some of the highlights.
PostgreSQL API Updates & PostgresConf Silicon Valley Wrap-Up
We have made a lot of progress on YSQL, the PostgreSQL compatible distributed SQL API for YugabyteDB! You can also read about YSQL architecture which covers how distributed SQL is implemented in YugabyteDB.
We were at the first ever PostgresConf Silicon Valley in October 2018. We had a talk about architecting distributed data for GDPR compliance, where we go into the requirements imposed by GDPR, making sure app architecture continues to ensure regulatory compliance and the impact it has on the modern data tier. We also had a 3 hour hands-on workshop on getting started with the PostgreSQL-compatible YSQL on YugabyteDB by running metabase, an open-source business intelligence tool while exploring scale out and fault tolerance features.
Recent Meetups and Conferences
We were at a number of conferences and meetups over the past few months, below are some select few with the highlights.
Nov 1 – SF Bay Cloud Native Open Infra Meetup
In this meetup, we explained what Kubernetes StatefulSets are and 5 key points that developers and operations engineers should be aware of when working with them. We also demonstrated how to run a complete E-Commerce application powered by YugabyteDB, when all services are deployed in Kubernetes.
Nov 7 – Bay Area Kafka Meetup
In this talk at the Kafka meetup, we went over the key architectural patterns involved in the context of a sample IoT Fleet Management application built on Kafka, KSQL, YugabyteDB and Spring Boot.
Nov 15 – Silicon Valley Kubernetes and Cloud Native Meetup
Due to popular demand, we presented the Kubernetes StatefulSets talk at this meetup as well.
Nov 26-30 – AWS re:Invent
If you are planning on being in Las Vegas for the AWS show, drop by our booth to schedule a technical briefing on how YugabyteDB can help you lower your AWS infrastructure costs and reduce operational complexity, all at the same time.
YugaByte will have a booth at AWS reInvent and Kubecon, be sure to stop by and say hello!

We are Hiring!
YugaByte is growing fast and we’d like you to help us keep the momentum going! Check out our currently open positions:
- Software Engineer – Cloud Infrastructure – Sunnyvale, CA
- Software Engineer – Core Database – Sunnyvale, CA
- Software Engineer – Full Stack – Sunnyvale, CA
- Developer Advocate – Sunnyvale, CA
Our team consists of domain experts from leading software companies such as Facebook, Oracle, Nutanix, Google and LinkedIn. We have come a long way in a short time but we cannot rest on our past accomplishments. We need your ideas and skills to make us better at every function that is necessary to create the next great software company. All while having tons of fun and blazing new trails!
Release and Roadmap Updates
We released YugabyteDB 1.1 with a ton of great features.
- Distributed multi-shard/multi-table ACID transactions!
- Global & consistent secondary indexes
- UNIQUE constraint on secondary indexes
- Native JSON data type
- Public/private IP bindings for multi/hybrid cloud or multi-region deployments
- User authentication
- Redis-compatibility features added to our YEDIS API:
- “Read from followers” for tunable read consistency
- Support for multiple databases or namespaces
- Support for MONITOR, EXPIRE, TTL
Read more about some of these features such as support for secondary indexes, the JSON data type and public IPs to simplify multi-cloud and hybrid-cloud database deployments.
YugabyteDB 1.1 also boasts a big performance boost! The graph below compares the performance of the latest Apache Cassandra with YugabyteDB 0.9 and 1.1 using the YCSB benchmark!
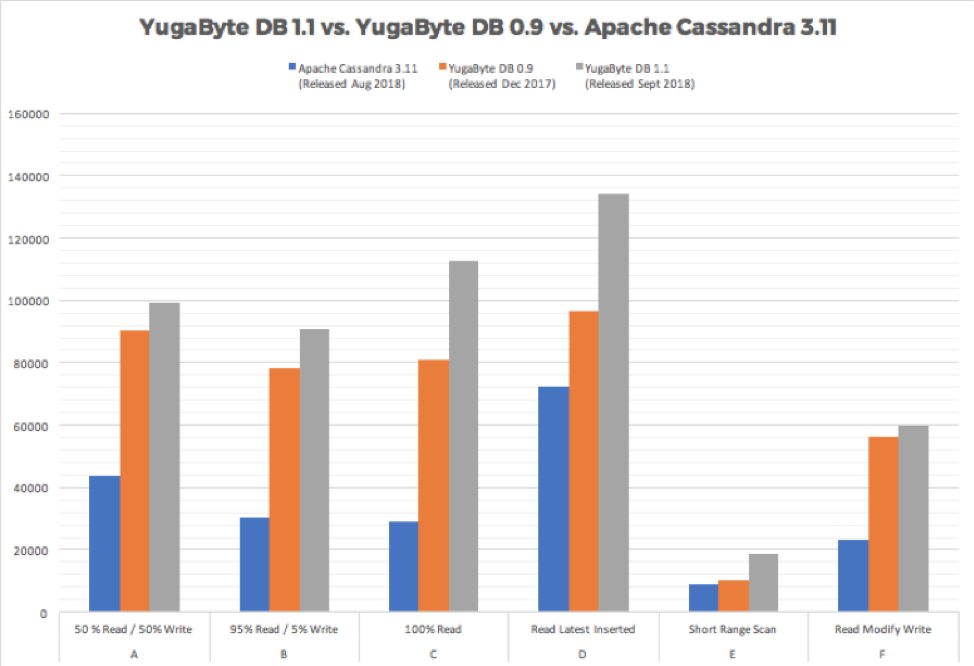
Look out for our upcoming release which will feature native Kubernetes support for YSQL (PostgreSQL-compatible API in YugabyteDB)!
Documentation, Blogs, Tutorials and Videos
We have been busy writing a lot of high quality blog posts, here are a few of them:
- Data Modeling Basics – PostgreSQL vs. Cassandra vs. MongoDB
- Getting Started with Distributed Backups in YugabyteDB
- Presto on YugabyteDB: Interactive OLAP SQL Queries Made Easy
- Are MongoDB’s ACID Transactions Ready for High Performance Applications?
- Apache Cassandra: The Truth Behind Tunable Consistency, Lightweight Transactions & Secondary Indexes
- Google Spanner vs Calvin: Is There a Clear Winner in Battle for Global Consistency at Scale
We have produced a number of technical videos as well, below is a list – enjoy!
- Spanner vs Calvin: Comparing Consensus Protocols
- Linear Scalability with YSQL – A PostgreSQL Compatible API for YugabyteDB
- Fault Tolerance in YSQL – a PostgreSQL Compatible API for YugabyteDB
- Distributed Database Architecture for GDPR
- Getting Started with Community Edition
On the documentation front, be sure to explore some of the core YSQL features.
Enhancements, Bug Fixes & Technical Questions
Security in YugabyteDB
We have just completed adding role based access control (RBAC) for the YCQL API! Securing who can access data in a database is extremely important. This is often done by created roles/users to authenticate who can connect to a database and granting them the appropriate access privileges to ensure they can access just the data they need. YugabyteDB automatically enforces authentication and authorization while allowing operators to add nodes to a cluster and tolerate failures. Most of our users running or planning to run YugabyteDB for their business critical data require this feature.
Serialization for YSQL
A great question asked by ddorian was about how the serialization format of data types in the PostgreSQL-compatible YSQL in YugabyteDB. In order to quickly enable the vast majority of PostgreSQL types, we are starting with reusing PostgreSQL’s in-memory serialization. This allows YugabyteDB to quickly enable data types such as N-dimensional arrays, JSONB and other complex types PostgreSQL has. However, for data types that are allowed in the primary key, YugabyteDB has a serialization, because the binary representation needs to be byte sortable. For collection types such as arrays, maps and JSONB the plan is to start using PostgreSQL’s serialization, and later map them onto the hierarchical document structure of DocDB to allow efficient updates of keys within the map in a backward-compatible way.
Since ddorian has had a number of great suggestions and answers to questions by other users to help YugabyteDB along, we are sending him a hoodie!
What’s Next?
- Using YugaByte at your company? Tell us about it and we’ll send you a hoodie!
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.
- Compare YugabyteDB to databases like Redis, Cassandra, MongoDB and Cosmos DB and DynamoDB.


