Introducing YugabyteDB with Enhanced Postgres Compatibility: Postgres Without Limits
September 19, 2024
We are thrilled to announce powerful new capabilities and architectural enhancements — collectively called enhanced Postgres compatibility — that allow a broader range of Postgres apps to run on YugabyteDB.
This release delivers on the promise we made a year ago to enable full portability of PostgreSQL applications to YugabyteDB. This latest development makes YugabyteDB the perfect database for companies building cloud-native applications and modernizing existing applications to a cloud-native RDBMS.
In this blog, we share what’s new in YugabyteDB and why we decided to build these new capabilities.
Before we get into the details, here’s a quick run-through of what we’ve added:
- Runtime Compatibility with Postgres – YugabyteDB now offers transactional semantics, retry logic, and CDC that works just like Postgres as part of our ongoing efforts to improve Postgres runtime compatibility.
- Adaptive Cost-Based Optimizer (CBO): YugabyteDB’s new Adaptive CBO extends the range of PostgreSQL’s CBO for high-scale and multi-region applications.
- Smart Data Distribution: YugabyteDB now automatically decides whether to colocate tables for lower latency, or shard and distribute them to achieve massive scale.
Together, YugabyteDB’s new adaptive CBO and smart data distribution allow developers to run their Postgres applications on YugabyteDB with comparable performance, and shard and distribute their data when they need scale.
This means no more tradeoffs and forced migrations!
Watch Yugabyte founder and co-CEO Karthik Ranganathan share the key features of this new release.
Our Bet on Postgres as the Standard
PostgreSQL remains the most popular database among developers due to its mature feature set, powerful extensions, open-source community, and support for popular programming languages.
Postgres is more than just a database now, it has become the default API for cloud-native transactional databases.
A growing number of Postgres-compatible databases and derived solutions have chosen to support the Postgres protocol, alongside other capabilities. YugabyteDB recognized this shift early and announced PostgreSQL compatibility as early as 2017-2018.
There are many benefits for databases that have Postgres compatibility:
- Postgres-compatible databases can tap into the vast existing ecosystem of tools, libraries, and frameworks built for Postgres without the need to re-engineer from scratch. This ecosystem continues to grow rapidly, and now includes AI extensions such as pg_vector.
- Developers can quickly get productive on a new database by drawing on their existing Postgres experience, avoiding the need to start learning from scratch.
- Businesses choosing to go with a Postgres-compatible database reduce risk and exposure, as they have Postgres and other compatible databases available as a fallback plan.
The Power of Postgres Compatibility
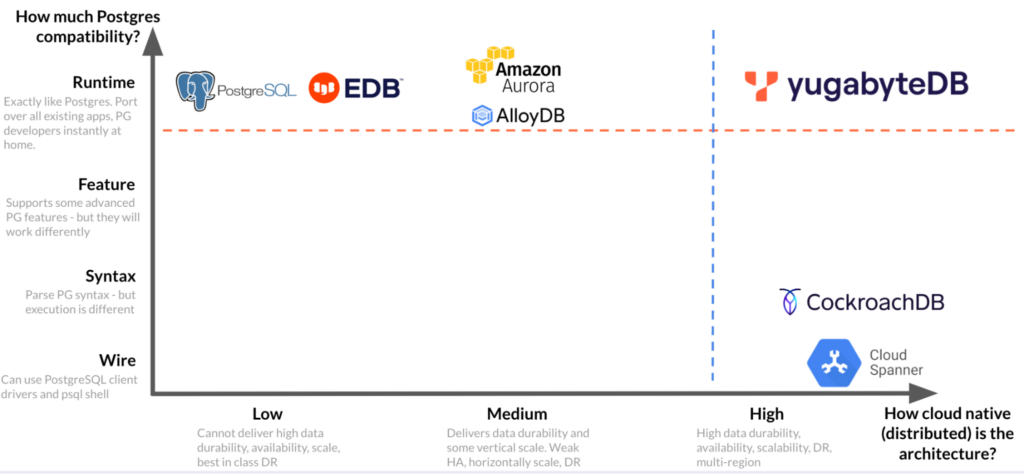
The extent to which you see these benefits depends on the level of compatibility your database offers, which varies (often wildly). Wire compatibility with Postgres doesn’t get you very far – developers want runtime compatibility, which ensures retries, error codes, etc. work seamlessly.
We realized early on that it is infeasible to achieve runtime compatibility by building the PostgreSQL API from scratch. Instead, YugabyteDB reuses the PostgreSQL query layer to achieve full PostgreSQL compatibility.
YugabyteDB’s Postgres-Compatible Architecture
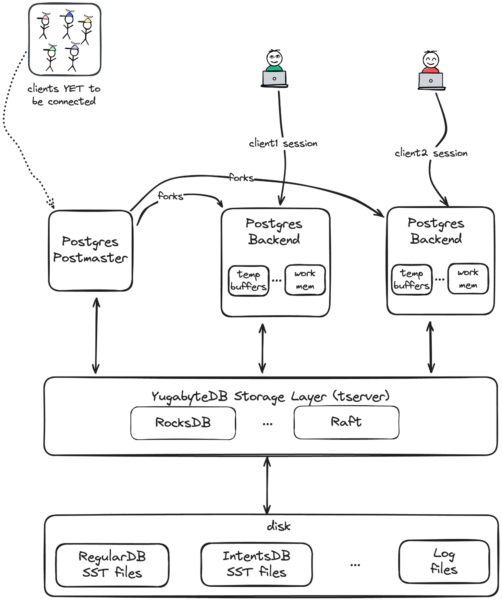
Figure 1. The simplified architecture of a YugabyteDB node
We use vanilla Postgres as-is for the query layer and replace Postgres storage with YugabyteDB’s own distributed storage engine.
As a result, whenever you connect to any node in a YugabyteDB cluster, you’re actually connecting to a Postgres postmaster process. When your app executes a SQL query, a Postgres backend process handles and executes that request over a distributed cluster.
Evolving Postgres for Modern Enterprise Applications
Despite the popularity that Postgres enjoys, its limited resilience and scalability are stumbling blocks for enterprise and business-critical applications.
This is particularly challenging for apps that need to stay online through planned or unplanned outages, scale quickly to meet demand, or keep data in multiple regions.
YugabyteDB retains all the power and familiarity of PostgreSQL while evolving it in three distinct ways:
- Distributed from within: YugabyteDB’s distributed architecture gives you built-in resilience, dynamic scalability, and multi-site distribution, while the PostgreSQL-compatible API offers workload portability
- Enterprise-grade out of the box: YugabyteDB brings the capabilities of leading commercial RDBMS to distributed Postgres, such as disaster recovery and replication, performance optimization and observability, security, etc.
- Delivered as a cloud service: YugabyteDB has architected Postgres as a flexible managed service in any public or private cloud. Rather than just running Postgres as a managed service in the cloud, we are reimagining the database as a native cloud service that fully uses the vast resources of public cloud services.
Delivering Runtime Compatibility AND Scalability
While other databases may be runtime compatible with Postgres, these databases are not distributed. This means that they cannot scale their reads and writes, don’t have the same resilience and availability (they are not multi-active), and lack multi-region capabilities.
Similarly, other databases may be fully distributed, but are only wire-compatible with Postgres.
YugabyteDB is the only database that is both runtime compatible with Postgres and fully distributed.
Beyond Functional Compatibility with Postgres
As more enterprises have migrated their Postgres apps to YugabyteDB for high availability and scalability, we realized that runtime compatibility with Postgres was not enough to easily bring apps over.
Why?
YugabyteDB is a distributed database that shards and replicates data to multiple nodes in a cluster to achieve resilience and scalability. When an application is ported from Postgres to YugabyteDB, query performance can be impacted, sometimes in unexpected ways.
Developers had to spend extra cycles optimizing their existing Postgres apps for YugabyteDB’s distributed nature. Developer time is valuable, and while some enjoyed diving into distributed systems, we saw this friction as an opportunity for improvement.
We wanted to provide a better lift-and-shift experience, enabling developers to run their existing Postgres apps on YugabyteDB without additional work.
Going Beyond Functional Parity
We set out to achieve performance parity, going beyond just functional compatibility with Postgres. Developers should be able to migrate applications built for PostgreSQL with minimal changes (lift-and-shift) and have those apps run without errors and with performance that is comparable with PostgreSQL.
Then, when the apps need scalability, they should be able to automatically shard and distribute the tables and queries to use the resources in the cluster.
To achieve this, we innovated on two fronts:
Adaptive Cost-Based Optimizer
PostgreSQL’s built-in cost-based optimizer (CBO) is critical for handling multiple and diverse workloads. YugabyteDB’s new Adaptive CBO extends the range of PostgreSQL’s CBO for high-scale and multi-region applications.
It determines an optimal query plan that considers whether data is co-located, automatically sharded, or even distributed across zones or regions. It also implements core Postgres capabilities including extended table statistics, parallel plans, and bitmap scans.
Smart Data Distribution
Distributed SQL databases typically federate data and query processing across nodes. While this enables workloads to scale, it can degrade the performance of applications built for a traditional database. This forces developers to choose between lower latency and greater scale.
YugabyteDB eliminates this forced choice by automatically determining whether to store tables together in a colocated manner for lower latency, or shard and distribute them to achieve massive scale.
Another reason some apps didn’t see comparable performance was due to subtle storage differences between standard Postgres and distributed Postgres (YugabyteDB). In the early days, we had to give up on certain internal Postgres capabilities (such as bitmap scans or parallel queries), especially those tightly coupled with the Postgres storage layer.
However, over the past year, we’ve been bringing back these missing pieces of the puzzle at the storage layer—or at the intersection of the storage and query layers—by “teaching” Postgres how to use our new cost-based optimizer, run parallel queries, leverage shared memory, and do so much more with YugabyteDB’s distributed storage.
Why do these latest optimizations matter?
YugabyteDB should not only work like Postgres but also perform like it—or even better! We want developers migrating Postgres apps to YugabyteDB to enjoy out-of-the-box high availability and scalability without sacrificing key Postgres features, or investing extra effort in performance optimizations.
The final results exceeded even our expectations.
- Over 92% of PostgreSQL query patterns run with comparable performance on YugabyteDB, up from 47% two years ago. This means developers can port their Postgres applications to YugabyteDB and achieve comparable performance while being able to scale in place when needed.
- YugabyteDB’s Adaptive CBO picks the optimal query plan in 93% of TAQO Framework tests, which is close to the 97% score achieved by Postgres. The TAQO Framework is a query optimizer testing framework for Postgres-compatible databases based on research at the University of California at Davis.
- Smart Data Distribution enables YugabyteDB to support over 50,000 database objects – tables, indexes, sequences, and more – compared to 2,000 without smart data distribution. This results in significantly higher scalability.
Further details on the latest improvements are available in the Enhanced Postgres Compatibility Mode documentation.
In Summary
We hope you now have a better understanding of why YugabyteDB continues to go deep in the woods with Postgres compatibility, and our commitment to making YugabyteDB the database of choice for modern transactional applications.
We’re not just building another distributed SQL database. We’re building a fully distributed database with enhanced Postgres compatibility that scales and never fails.
Check out our latest release page for more information.
Additional Resources
We want you to take your existing Postgres app and run it with no (or minimal) changes on YugabyteDB. That’s already a reality—just check out and join our Postgres Century App Challenge to demonstrate how easy it is to migrate and run Postgres apps on YugabyteDB.
If you’re interested in learning how we brought these latest capabilities to life, check out the related blogs below (we will add more as they go live!)
Stay tuned to our blog page for more upcoming engineering deep dives on the new cost-based optimizer, parallel queries, bitmap scans, and other features of the enhanced Postgres compatibility mode.
You can also download the latest version of YugabyteDB today and try it out!
To find out more about YugabyteDB and the power of distributed SQL, register for free to attend our upcoming Distributed SQL Summit (DSS) on November 12th.



