Using YugabyteDB Geo-Partitioning to Ease Global Expansion & Achieve Regulatory Compliance
July 25, 2024
From GDPR mandates for personal data in the EU, to payment data restrictions in India, global data regulatory requirements are constantly evolving.
Companies planning global expansion must meet the data regulatory requirements of each new region. A traditional approach is to launch a separate database instance in each new region, however, these databases do not communicate, which is unacceptable for modern environments.
To mitigate this, you need to build out dependencies to allow certain data to be replicated across these regions. This is generally done asynchronously, and involves application code being built-out to fuse data across regions and support functionality that requires data from multiple regions.
This blog discusses the pitfalls of standing up separate PostgreSQL instances per region and the advantages of using geo-partitioning in YugabyteDB.
What is Geo-Partitioning?
As YugabyteDB is PostgreSQL compatible, you can use the PostgreSQL concepts of declarative table partitioning and tablespaces to set up geo-partitioning in YugabyteDB. As our documentation explains:
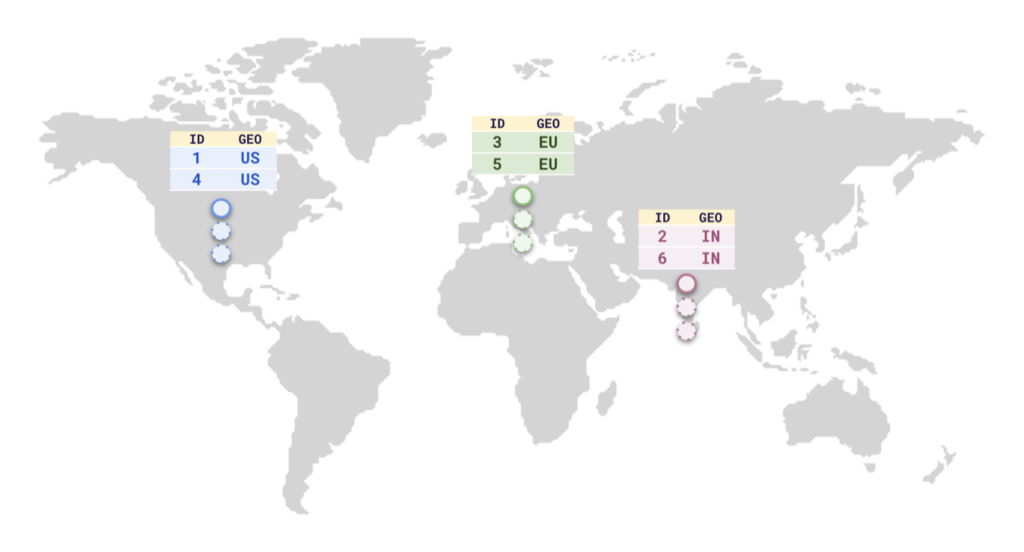
Row-level geo-partitioning allows fine-grained control over pinning data in a user table (at a per-row level) to geographic locations, thereby allowing the data residency to be managed at the table-row level. Use cases requiring low latency multi-region deployments, transactional consistency semantics, and transparent schema change propagation across the regions would benefit from this feature.
Geo-partitioning allows you to move data closer to users to:
- achieve lower latency and higher performance
- meet data residency requirements to comply with regulations such as GDPR
Geo-partitioning of data enables fine-grained, row-level control over the placement of table data across different geographical locations. This is accomplished in two steps:
- Partition a table into user-defined table partitions.
- Pin these partitions to the desired geographic locations by configuring metadata for each partition.
Why Use YugabyteDB?
Single Logical Cluster
When you launch a YugabyteDB cluster you control:
- How many regions it covers
- The number of nodes per region
- The instance type of those nodes
Regardless of the number of regions involved, this is a single logical cluster that stretches across the selected regions. This means that data is accessible from the region you may connect to, even if that data itself resides in a different region. This greatly simplifies connection routing you may need to implement to gather all the data your application requires.
Cross Region Functionality
As the number of application users grows, so does the complexity of their requirements.
For application functionality that requires data in multiple regions, you can query a single region to get the necessary data across your cluster. Compared to the traditional approach, this allows you to avoid building out application logic to gather this data through separate connections, and bring data together before you send it to the user.
For example, a healthcare startup requires this functionality for collaboration between global doctors (who have access to data from multiple regions) and local doctors (who only have access to their local region) to optimize cancer patient treatments. Without this capability, the doctors would require separate log-ins per region to allow them to access each region individually. Alternatively, they would have had to build out the application logic to query all the regions, and then present it to the user.
Global Data Access
Most data models need global tables. These are tables that have replicas across multiple regions in a cluster. They are typically used for data that is required in each region, and does not have to abide by data regulatory requirements i.e. metadata, configuration data, etc.
In YugabyteDB the amount of replicas and the regions they reside in can be controlled by creating a global tablespace, rather than a tablespace for a specific region. This allows you to synchronously replicate data across multiple regions natively through the database, using the same tablespace concept that enables you to map local data to local nodes for geo-partitioning.
For local access to this global data you can use follower reads for low latency reads, albeit with some staleness. Staleness should not be a major issue as global tables should not be changed often. With traditional single node databases you typically have to replicate your data across regions asynchronously, which brings its own management overhead and data challenges.
Ease of Expansion
It is simple to expand to new regions with YugabyteDB. Once you add nodes to the new region, you just create a new tablespace and partition for that region. By assigning the partition to the tablespace you can insert and read data from that partition. Additionally, if regulations change in the future, you can simply change the tablespace the table is assigned to and the tablets will move over automatically.
Take Advantage of Geo-Partitioning with Minimal Application Changes
YugabyteDB has built-in geo-partitioning functions you can use to avoid changing your existing application. This allows you to add new regions with minimal, sometimes no, application code changes, drastically minimizing time to market.
A leading global transport and logistics company took advantage of geo-partitioning with minimal application changes and optimized for lower latencies and resiliency using these functions.
Adding Value with YugabyteDB Aeon
In addition to the core database benefits YugabyteDB provides, YugabyteDB Aeon (the cloud-native managed DBaaS) provides features to help you control costs as you expand.
Expand When Your Business Needs To (And No Earlier!)
You can start with a single region, and expand when required. There is no need to start with a three-region cluster if you don’t require them, and spend money on nodes that don’t bring you immediate value. Instead, enjoy the flexibility of only expanding your cluster as your needs grow.
Asymmetric Regions
As your application reach grows, not every region will have the same resource demands. If you first launched your application in the US, don’t expect the same level of traction when you initially expand your cluster to the EU. YugabyteDB Aeon makes it easier to fine-tune your vCPU, memory, and disk storage resources per region. This gives you greater control of costs as your application grows globally.
The Benefits of Launching a PostgreSQL Instance per Region
Single Node Latencies
You will continue to see the same latencies without needing to make changes. You may see higher latencies with distributed databases (unfortunately you cannot get scalability and high availability without tradeoffs), so if there is no flexibility here, this approach may suit your needs better.
The traditional approach may also meet your needs if you don’t anticipate a current or future need for combining data from multiple regions or replicating data synchronously across regions.
No Database Changes
Although this approach may require add-ons, like asynchronous replication, no actual schema changes are required for your database. Changes will have to be on the application side if you require cross region data sharing or aggregation. However, although you may not require database-level changes, it doesn’t mean you can launch a new region quicker than you would with the geo-partitioning approach.
Gaps in the PostgreSQL Approach
Many of the gaps called out in this section are solved or mitigated using YugabyteDB.
Multi-Region Data Access
The traditional approach is that all your single server deployments of PostgreSQL are siloed to a single region. If your application requires data from multiple regions you will have to manage separate connections, possibly with custom routing, to aggregate the necessary data from each region in the application layer. Even after this custom code is built out it will have to be managed and improved upon as you build out additional application functionality, or expand to new regions. This complexity can greatly reduce your time to market in new regions, and increase management overhead for developers.
Data Replication Across Regions
For data required in each region, you would have to set up and manage asynchronous replication. The more regions you have, the higher the overhead. Overhead in this case is the extra time developers require to build out and maintain asynchronous replication, as well as the risk of issues and resultant downtime.
This process increases in complexity if all regions need to write to these tables, as custom routing has to be added to the setup.
High-Availability Setup
Each region requires its own high availability configuration. This complicates the architecture by adding primary and replica endpoints that the application must manage. In comparison, YugabyteDB provides high availability as a part of its core functionality.
Management Overhead
Each region must be managed and adjusted separately for each separate database instance. This is time-consuming and error-prone, limiting flexibility and responsiveness.
With YugabyteDB, all nodes are a part of a single logical cluster. For example, a database upgrade will be performed as a no-downtime rolling restart.
The PostgreSQL approach means you have to handle the database upgrade separately in each region. This same limitation applies to any DDL changes you need to make on the schema, in which case the modifications would have to be applied to all of the disparate databases.
With YugabyteDB it is just a single database, and only one DDL statement.
Gaps to the Geo-Partitioning Approach
Distributed SQL Latencies
Generally, latencies for distributed SQL databases tend to be higher than single node databases like PostgreSQL. In most cases this has no impact for single point queries, however, the difference can increase as the queries increase in complexity.
This discrepancy has been improved upon in recent versions of YugabyteDB, especially in v2024.1 which introduces Enhanced Postgres Compatibility Mode.
Lack of Support for Foreign Keys on Partitioned Tables
YugabyteDB does not currently support foreign key references on partitioned tables. This has been supported by PostgreSQL since version 12 (YugabyteDB is currently based on PG version 11.2). This will be supported in YugabyteDB following its upgrade to PostgreSQL 15.
Conclusion
Whether you plan to stand up separate PostgreSQL instances per region, or take advantage of geo-partitioning in YugabyteDB, there are tradeoffs.
However, using geo-partitioning with YugabyteDB is an ideal solution for use cases that require cross-region data access, faster time to market, and easy deployment management.
YugabyteDB provides the flexibility you need to meet data residency requirements, while improving the overall experience of regional expansion.
Learn more about YugabyteDB’s upgrade to PostgreSQL 15
- YugabyteDB Moves Beyond PostgreSQL 11
- Sneak peek into PostgreSQL 15 compatible YugabyteDB | YugabyteDB Friday Tech Talk | Episode 111
Achieve live migrations from PostgreSQL with YugabyteDB Voyager


