Using YugabyteDB xCluster DR for PostgreSQL Disaster Recovery in Azure
June 6, 2024
PostgreSQL high availability and disaster recovery are top requirements for cloud-native applications that span multiple availability zones and regions.
You can choose the most suitable option from a broad PostgreSQL ecosystem based on your recovery point objective (RPO) and recovery time objective (RTO). One solution is YugabyteDB, a distributed SQL database built on PostgreSQL.
With YugabyteDB, your PostgreSQL applications can choose from several design patterns for multi-region applications. These range from traditional active-active multi-master database deployments with asynchronous replication, to contemporary geo-partitioned database clusters with synchronous replication within configured locations.
In this guide, we’ll use the active-active single-master configuration to achieve disaster recovery across two regions in Microsoft Azure. We’ll set up two standalone distributed PostgreSQL clusters (aka. YugabyteDB) in different cloud regions. One cluster will be designated as the primary, responsible for all reads and writes, and replicating the data to another replica cluster asynchronously. We’ll also use the xCluster disaster recovery (DR) feature of YugabyteDB to perform failover and switchover between the clusters.
Configuring Azure Regions in YugabyteDB Anywhere
YugabyteDB Anywhere is a self-managed database-as-a-service offering that allows you to deploy and operate YugabyteDB in your public and private cloud environments.
Once you host a YugabyteDB Anywhere portal in your environment, you can start configuring the infrastructure that will be used for a target database deployment.
In this guide, we’ve provided the configuration for Microsoft Azure spanning multiple regions in the USA.
Next, let’s assume we’re building a trading application that lets you buy and sell stocks. The primary instance of the application will be deployed in the US East region. According to the disaster recovery plan, the US West region will serve as a secondary location in case of region-level outages in the East.
Deploying the Primary Database Cluster
Let’s start by configuring a primary database instance in the US East region.
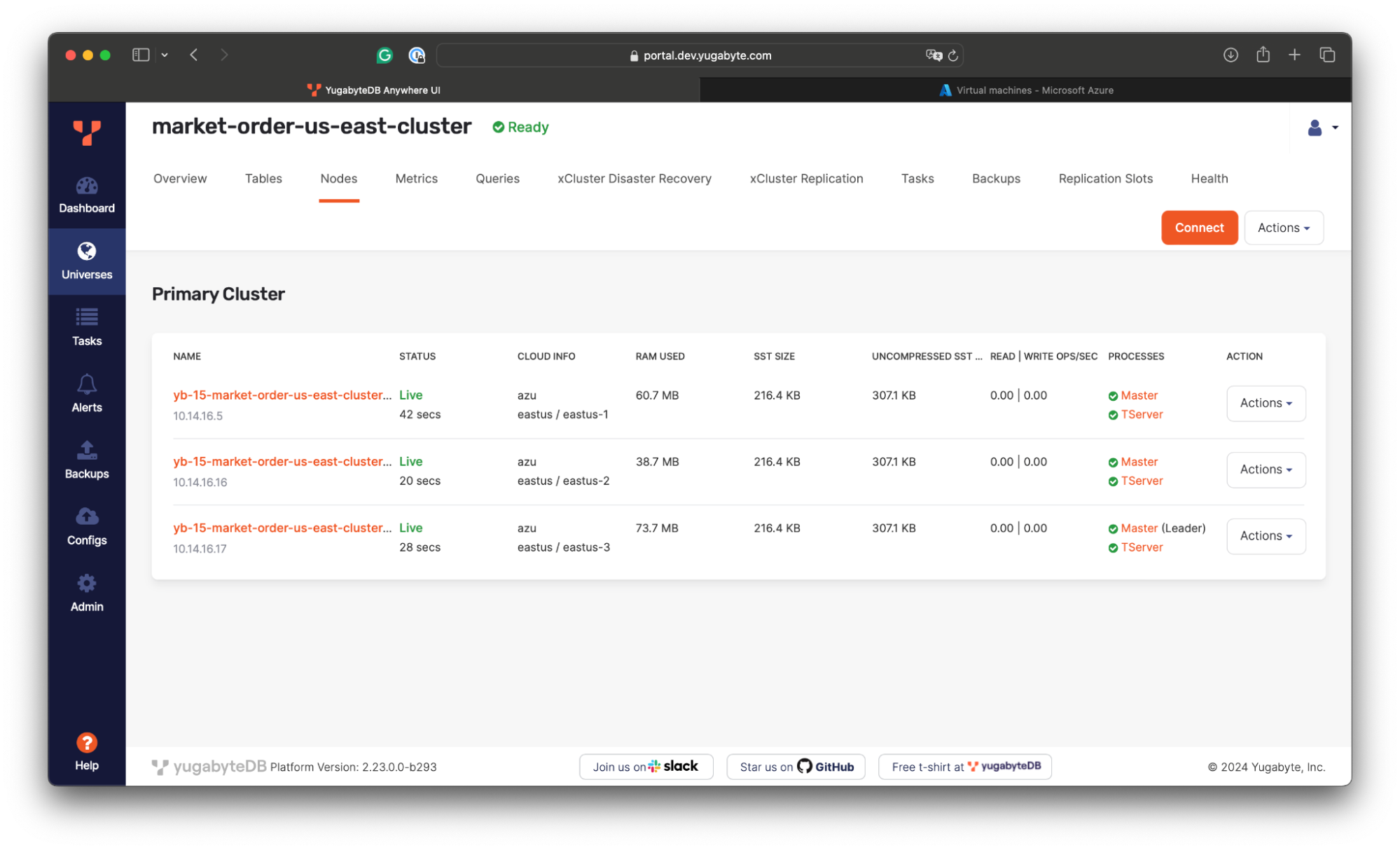
We’ll deploy a three-node YugabyteDB cluster spanning three availability zones in the US East region.
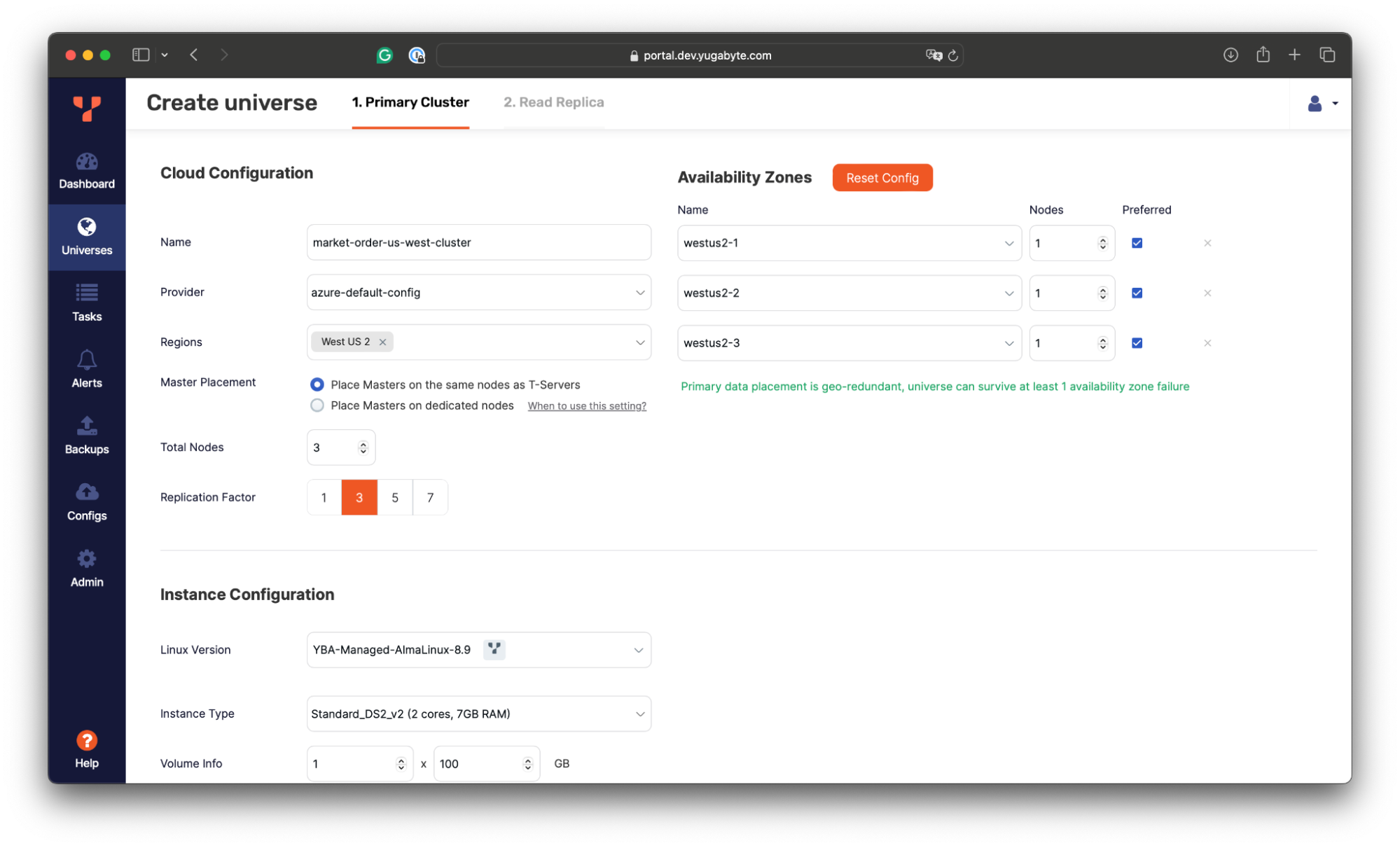
With this configuration, the database will be able to tolerate zone-level outages with no disruption to application workloads. The read/write requests will be evenly distributed across all the nodes, which communicate directly to coordinate transaction execution, handle failures, and replicate changes synchronously using the Raft consensus protocol.
With this setup, we can achieve an RPO of 0 and an RTO of 3 seconds.
Once the cluster is configured, YugabyteDB Anywhere will provision it within a few minutes:
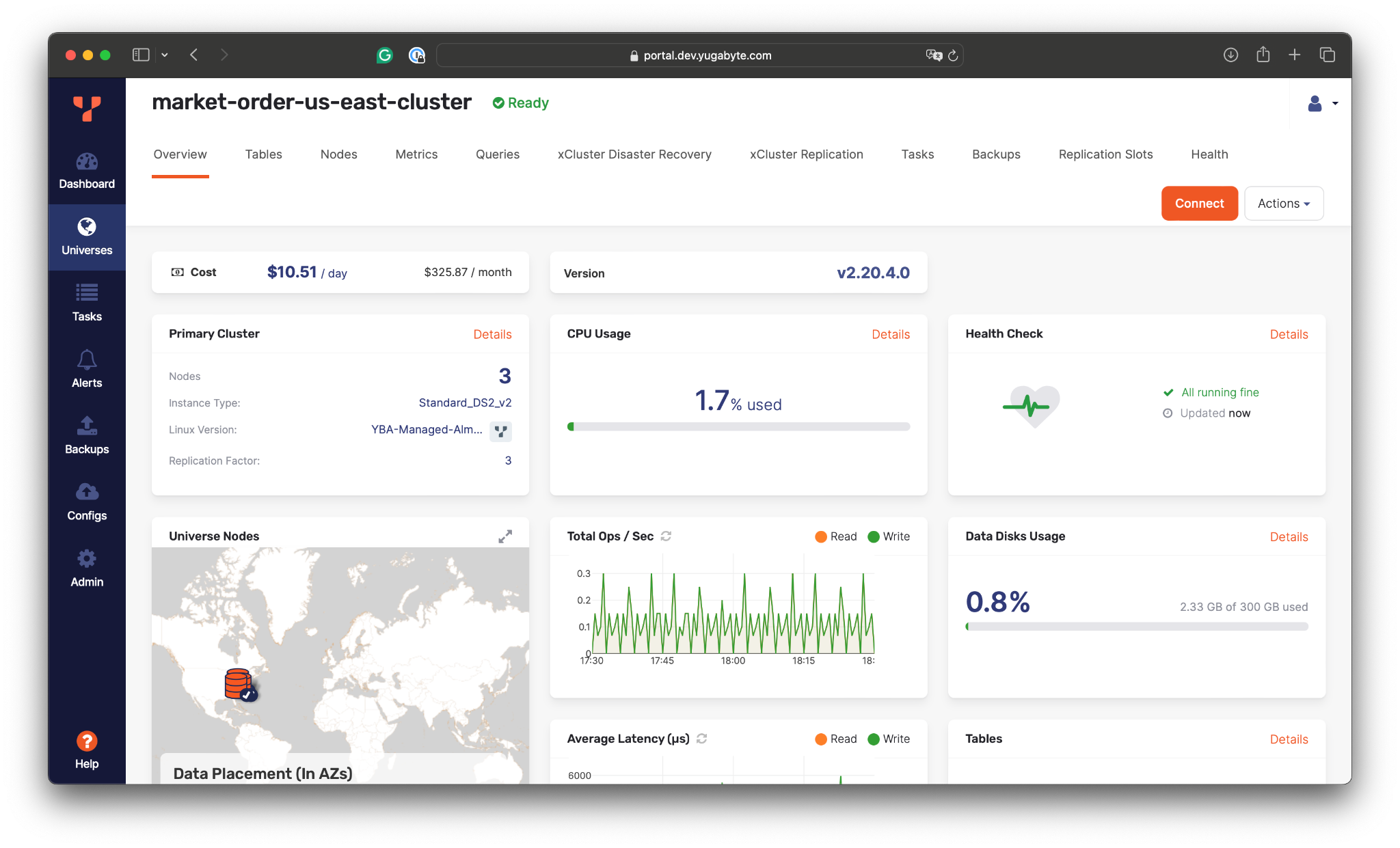
As soon as the cluster is ready, we can connect the trading application and assess the cluster’s resilience to zone-level outages.
Starting the Trading Application
The sample application subscribes to a remote API endpoint to receive information about mock market orders. The orders are processed and stored in PostgreSQL.
To minimize latency between the data and application layers, an application instance will be deployed in the US East region in Azure, which already hosts YugabyteDB.
After provisioning and connecting to a VM in the US East, we are ready to clone and configure the application:
- Clone the application source code:
git clone https://github.com/YugabyteDB-Samples/market-orders-app
- Update the
properties/yugabyte.propertiesfile with the YugabyteDB connectivity settings such as IP addresses allocated by Azure for the database nodes:dataSourceClassName = com.yugabyte.ysql.YBClusterAwareDataSource maximumPoolSize = 5 dataSource.user=yugabyte dataSource.password=password dataSource.databaseName=yugabyte dataSource.portNumber=5433 dataSource.serverName=10.14.16.5 dataSource.additionalEndpoints = 10.14.16.16:5433,10.14.16.17:5433
The application uses the YugabyteDB Smart Driver (YBClusterAwareDataSource), which is an extended version of the standard PostgreSQL JDBC driver.
The smart driver connects to one of the database nodes provided in the dataSource.serverName setting and automatically loads information about the entire cluster topology. The driver can then transparently connect to any of the nodes and load balance read/write requests.
The dataSource.additionalEndpoints setting is used only when the driver needs to open the very first connection to the cluster. If the node provided in the dataSource.serverName is not available, the driver will connect through one of the nodes listed in dataSource.additionalEndpoints.
Next, build and start the application:
mvn clean package java -jar target/market-orders-app.jar connectionProps=./properties/yugabyte.properties loadScript=./schema/schema_postgres.sql tradeStatsInterval=2000
The application successfully connects to the primary database instance and starts processing market orders that are synchronously replicated with Raft across the YugabyteDB cluster:
============= Trade Stats ============ Trades Count: 1017 Stock Total Proceeds Linen Cloth 2406.719971 Elerium 1551.320068 Google 1450.920044 Apple 1118.580078 Bespin Gas 1111.479980 Fill or kill trades: 13 =========================
Simulating a Zone-Level Outage
As our primary YugabyteDB cluster is stretched across several availability zones, it allows us to tolerate zone-level outages with an RPO of 0 and an RTO of a few seconds.
Let’s simulate a zone-level incident by stopping a database node the trading application has open connections with:
- Go to Azure Portal and stop a VM running a database node in one of the availability zones:

- Go to YugabyteDB Anywhere and confirm one of the nodes is no longer reachable:
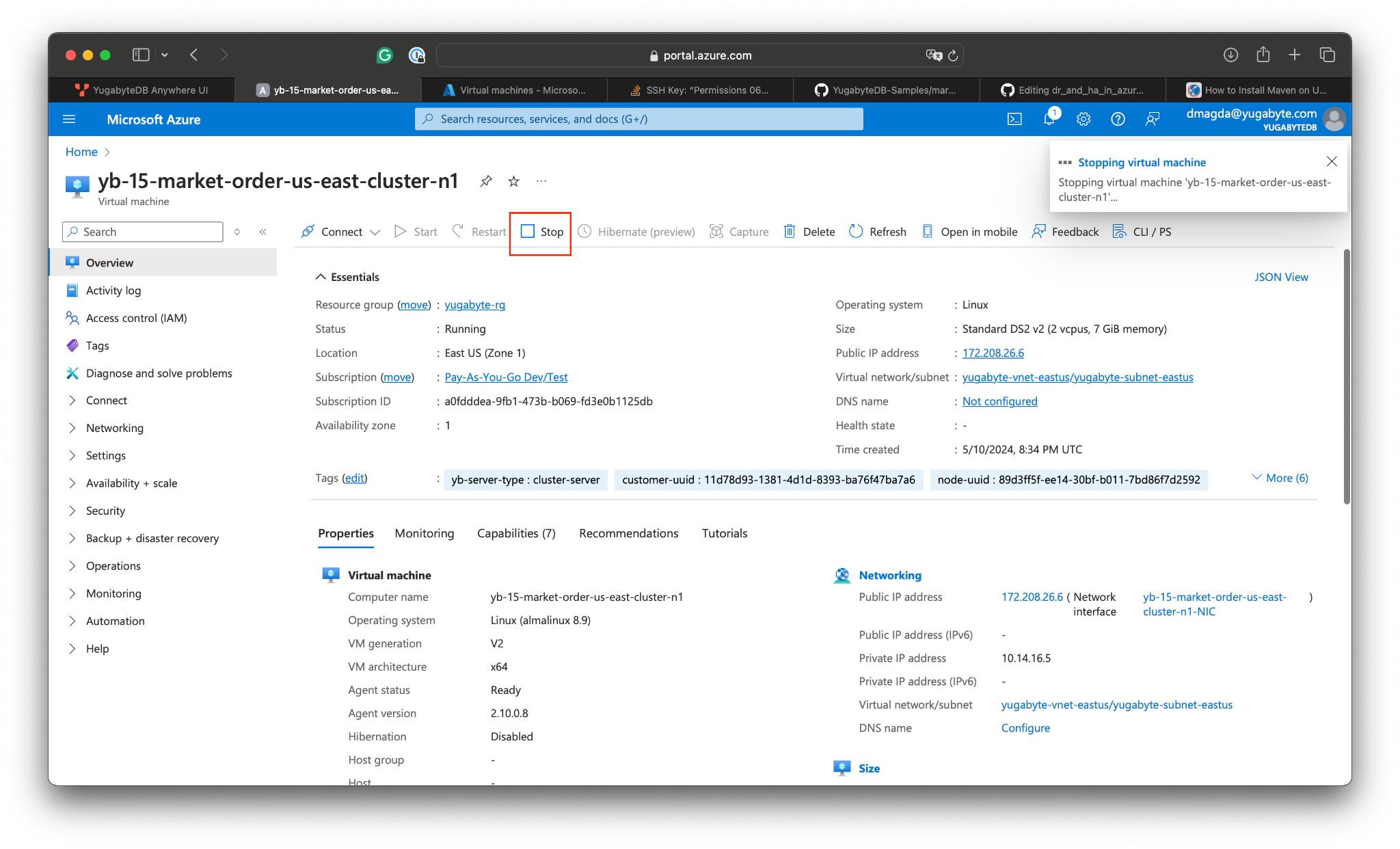
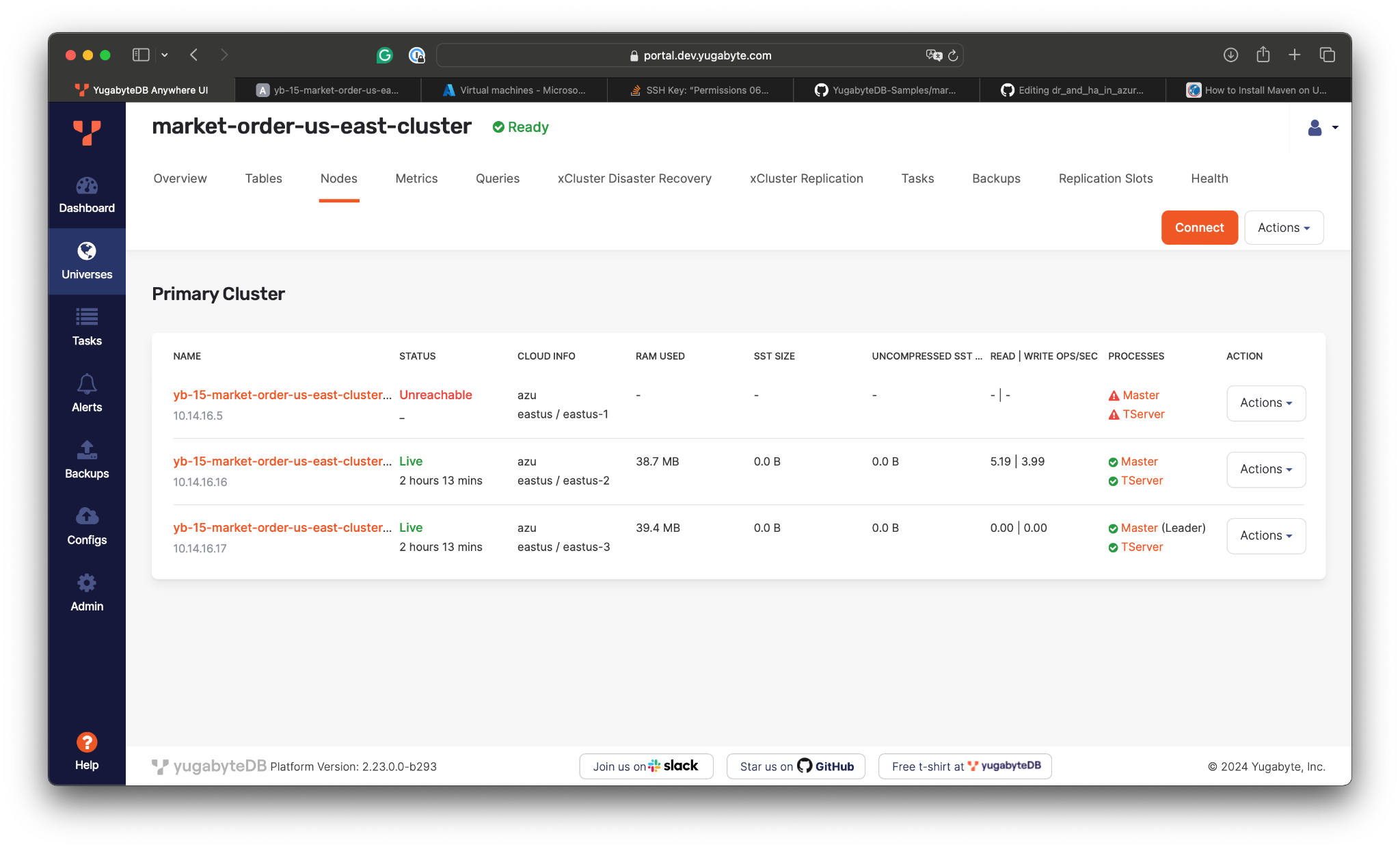
If we check the application logs, we see that the application continues processing the market orders without disruption. The database driver and connection pool detected that some of the opened connections had failed and reopened new connections with healthy database nodes.
============= Trade Stats ============ Trades Count: 3860 Stock Total Proceeds Google 58393.218750 Linen Cloth 52013.031250 Apple 40971.640625 Bespin Gas 40322.328125 Elerium 27966.039063 Fill or kill trades: 169
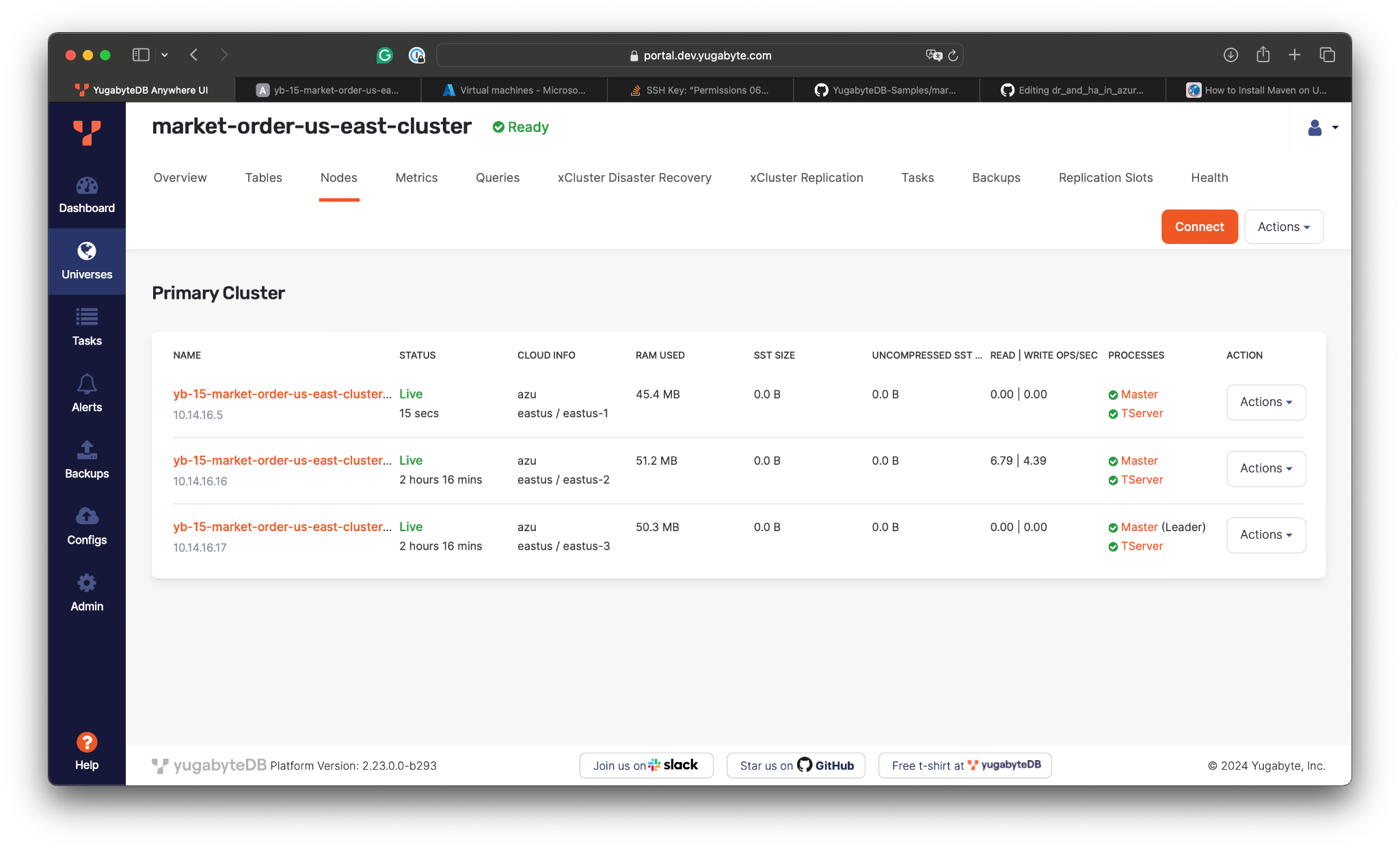
As the database instance was configured with a replication factor of 3, the remaining two database nodes are enough to achieve consensus with the Raft protocol.
Next, let’s bring the failed node back to the cluster by starting its VM in Azure. Then, we’ll achieve resiliency across multiple regions with a secondary replica cluster in the US West.
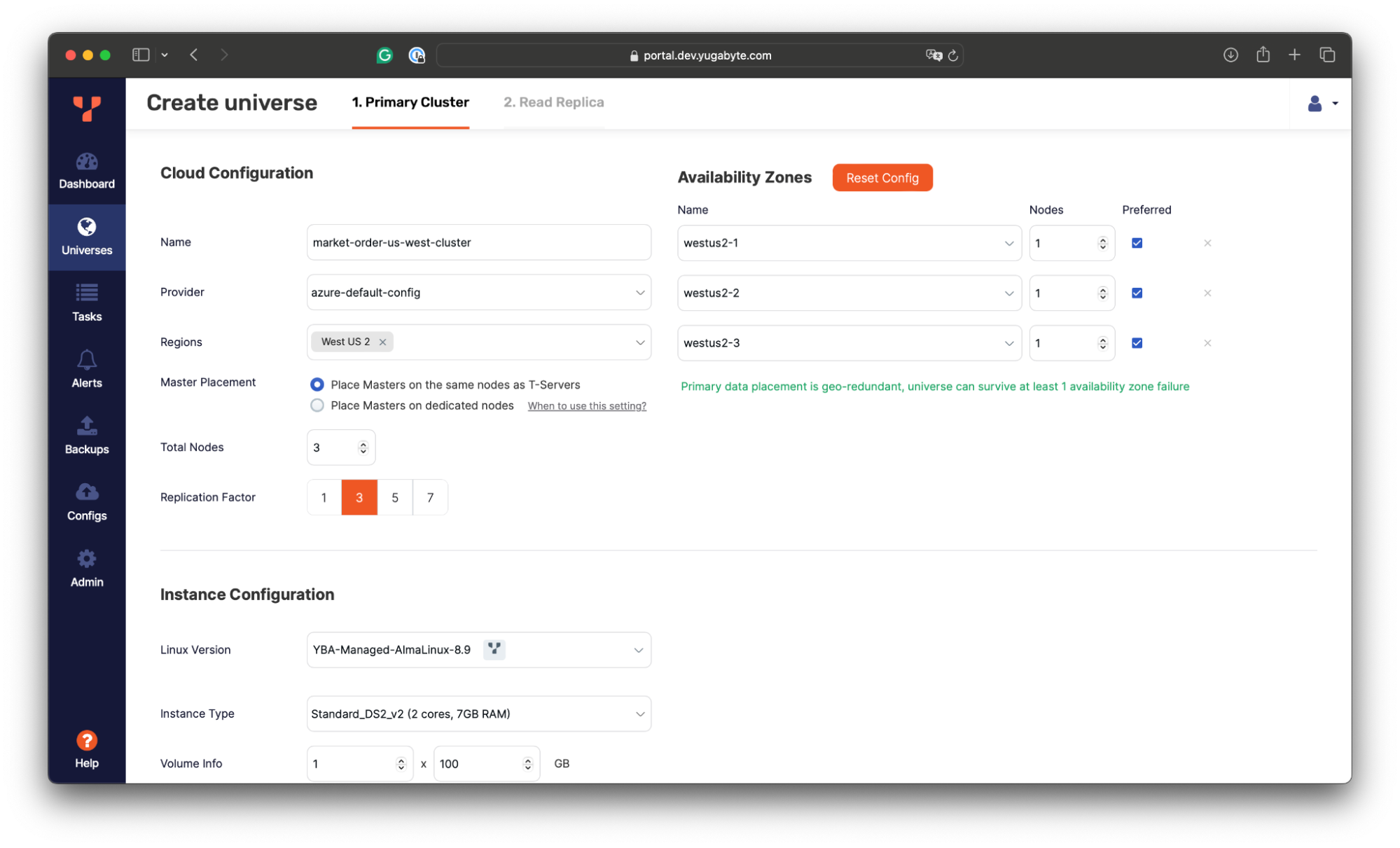
Deploying Replica Cluster in the US West
The configuration of the secondary replica cluster is similar to that of the primary one. We use YugabyteDB Anywhere to deploy a three-node database instance with the same configuration, but in a region in the US West.
The cluster will be deployed within a few minutes: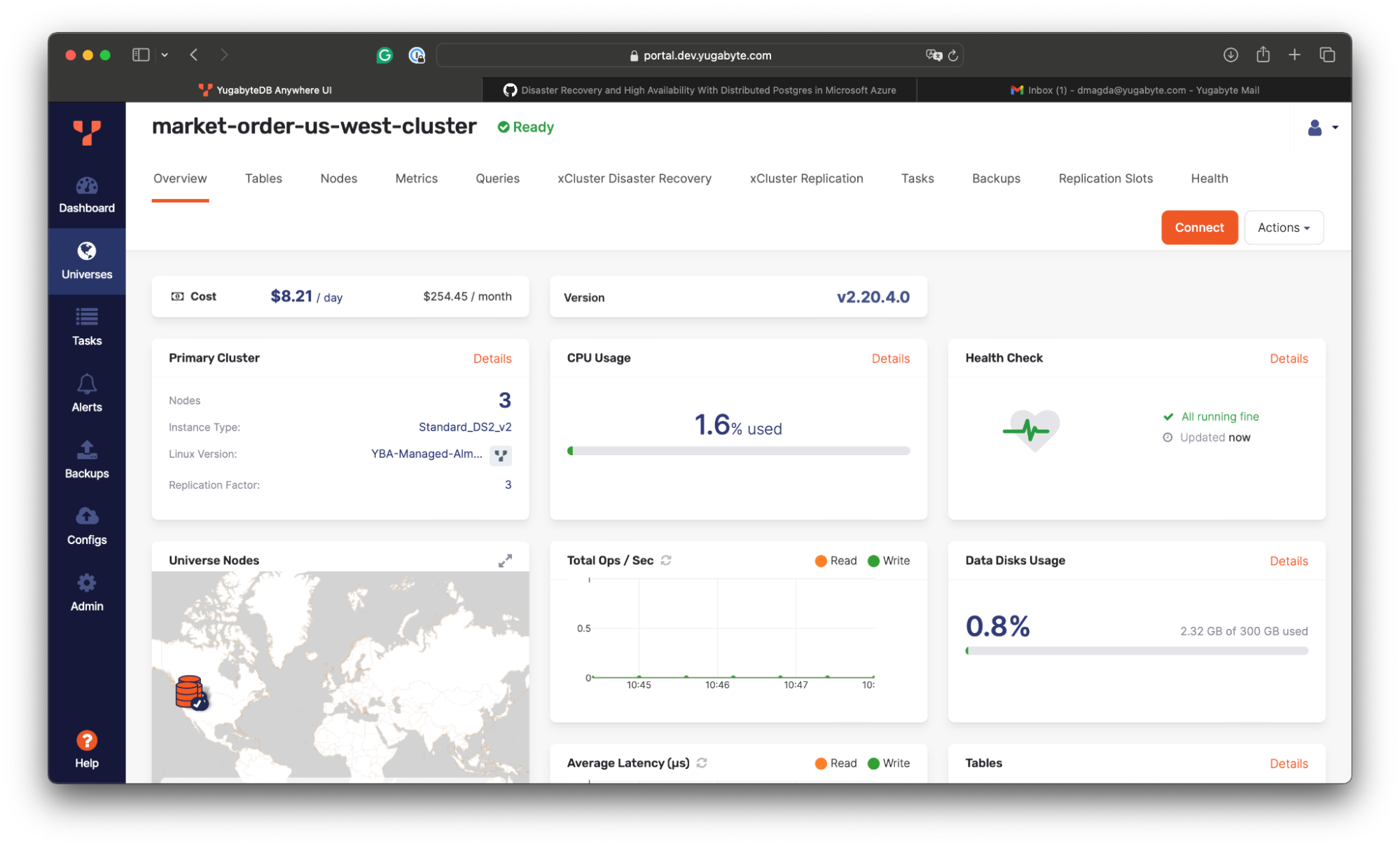
Configuring xCluster Disaster Recovery
The xCluster disaster recovery (DR) simplifies recovery from an unplanned outage (failover) or from performing a planned switchover. Planned switchover is commonly used for business continuity, disaster recovery testing, and as a failback after a failover.
Let’s use the xCluster DR to set up replication between the database clusters in the US East and US West:
- Go to the primary cluster’s dashboard and start configuring the xCluster DR:
- During the xCluster DR bootstrap, the initial copy of data will be applied from the primary to the replica cluster. We need to provide a storage location, such as Azure Storage, for that initial backup:
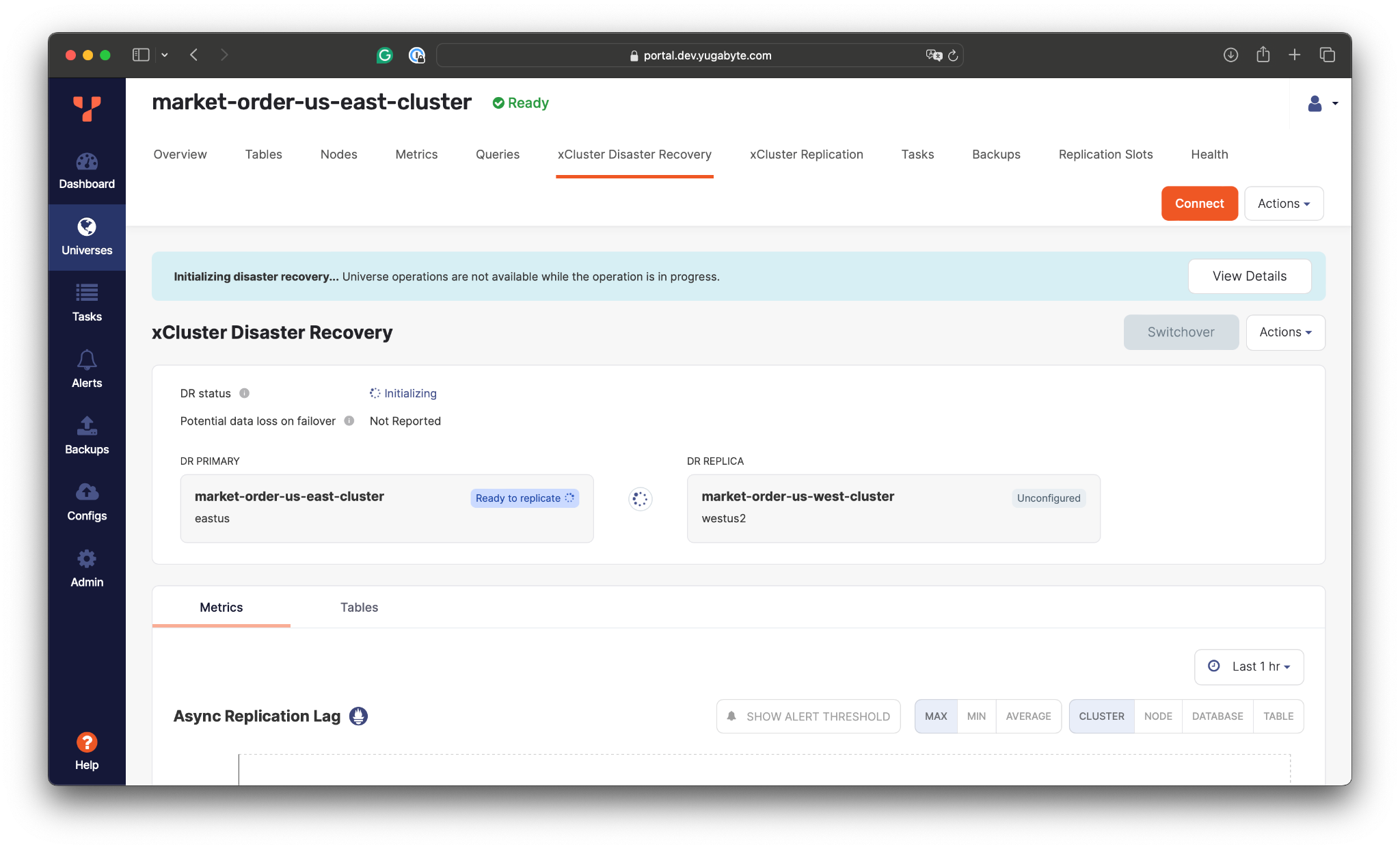
- Initialize the xCluster DR and wait for its completion:
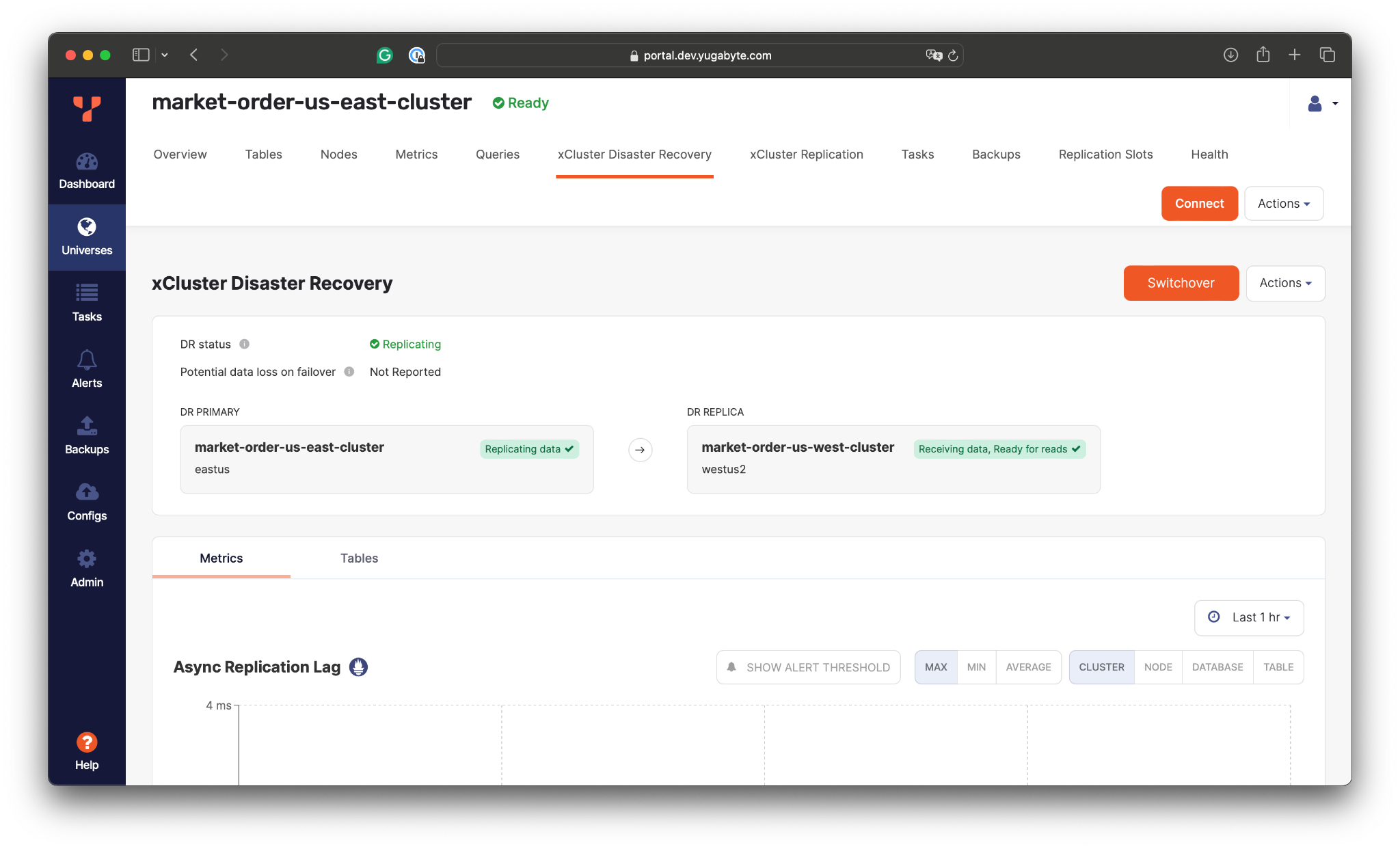
Once the initialization is complete, the xCluster DR will take a data backup from the primary cluster in the East and apply it to the cluster in the West. Then, the cluster in the East will start streaming changes asynchronously to the replica in the other part of the country.
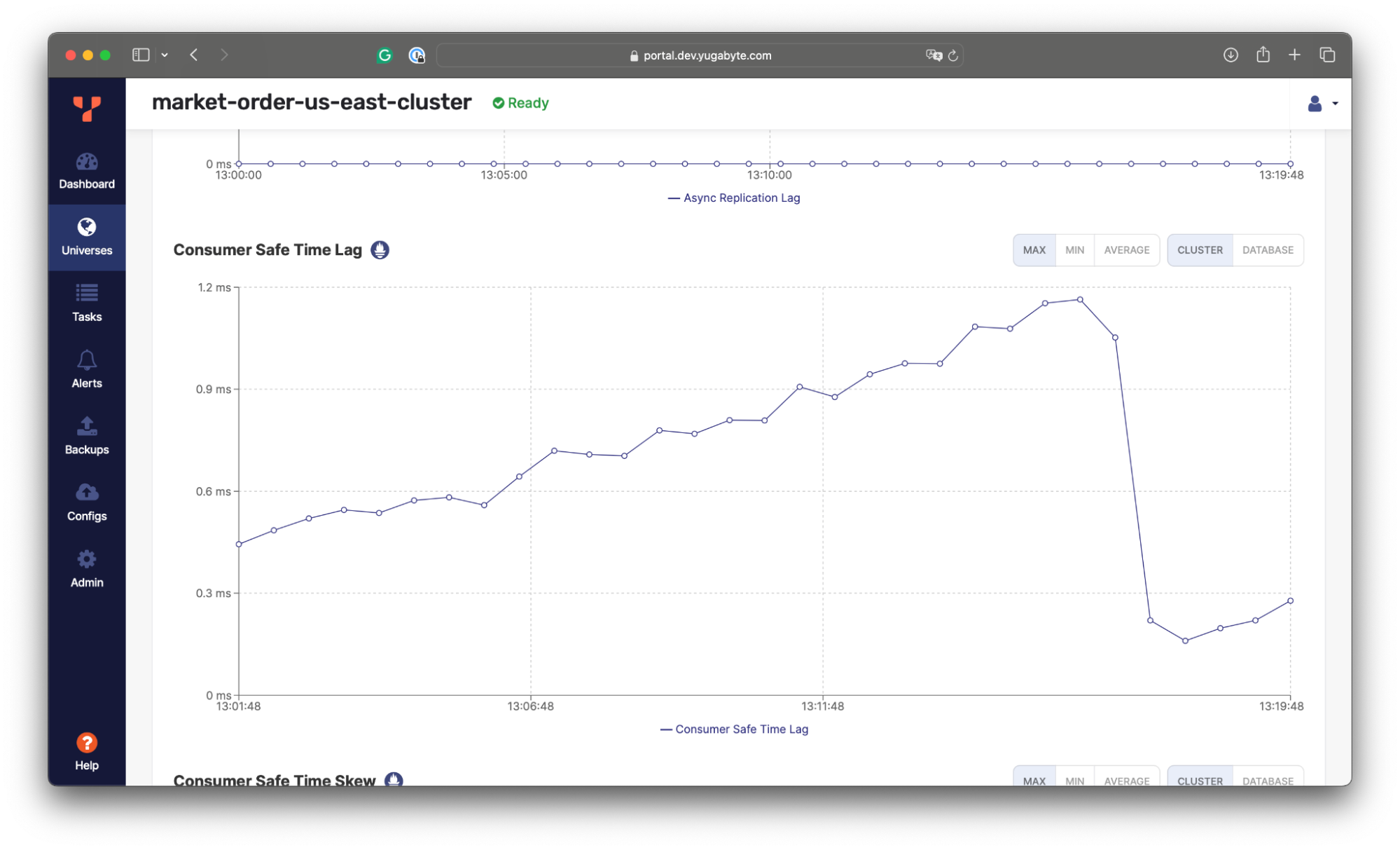
The xCluster DR also reports the current replication lag, which in turn depends on the network characteristics between the cluster.
Here, the replication lag is around 1ms, meaning that our trading application can lose up to 1ms of the latest changes (RPO=1ms) if the entire US East region goes down. However, the loss of 1ms of changes doesn’t lead to data inconsistency on the replica end. The changes are replicated transactionally, and the secondary cluster applies only to the transactions whose changes were fully replicated.Also, it’s worth noting that the replica cluster in the West can be used for read workloads. For example, we can connect to it and confirm that the initial copy of data was applied and that the changes are being streamed from the East:
 Here, the replication lag is around 1ms, meaning that our trading application can lose up to 1ms of the latest changes (RPO=1ms) if the entire US East region goes down. However, the loss of 1ms of changes doesn’t lead to data inconsistency on the replica end. The changes are replicated transactionally, and the secondary cluster applies only to the transactions whose changes were fully replicated.Also, it’s worth noting that the replica cluster in the West can be used for read workloads. For example, we can connect to it and confirm that the initial copy of data was applied and that the changes are being streamed from the East:
Here, the replication lag is around 1ms, meaning that our trading application can lose up to 1ms of the latest changes (RPO=1ms) if the entire US East region goes down. However, the loss of 1ms of changes doesn’t lead to data inconsistency on the replica end. The changes are replicated transactionally, and the secondary cluster applies only to the transactions whose changes were fully replicated.Also, it’s worth noting that the replica cluster in the West can be used for read workloads. For example, we can connect to it and confirm that the initial copy of data was applied and that the changes are being streamed from the East:yugabyte=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------------------+----------
public | buyer | table | yugabyte
public | buyer_id_seq | sequence | yugabyte
public | top_buyers_view | materialized view | yugabyte
public | trade | table | yugabyte
public | trade_id_seq | sequence | yugabyte
(5 rows)
yugabyte=# select count(*) from trade;
count
-------
1582
(1 row)
Simulating a Region-Level Outage
Next, let’s see the xCluster DR in action by simulating a region-level outage in the US East region that hosts the primary database instance.
We’ll simulate that outage by stopping all the database nodes in the region:
- Go to Azure portal and stop all the VMs running the database nodes in the US East:
- Jump back to YugabyteDB Anywhere to confirm the primary cluster is no longer available:
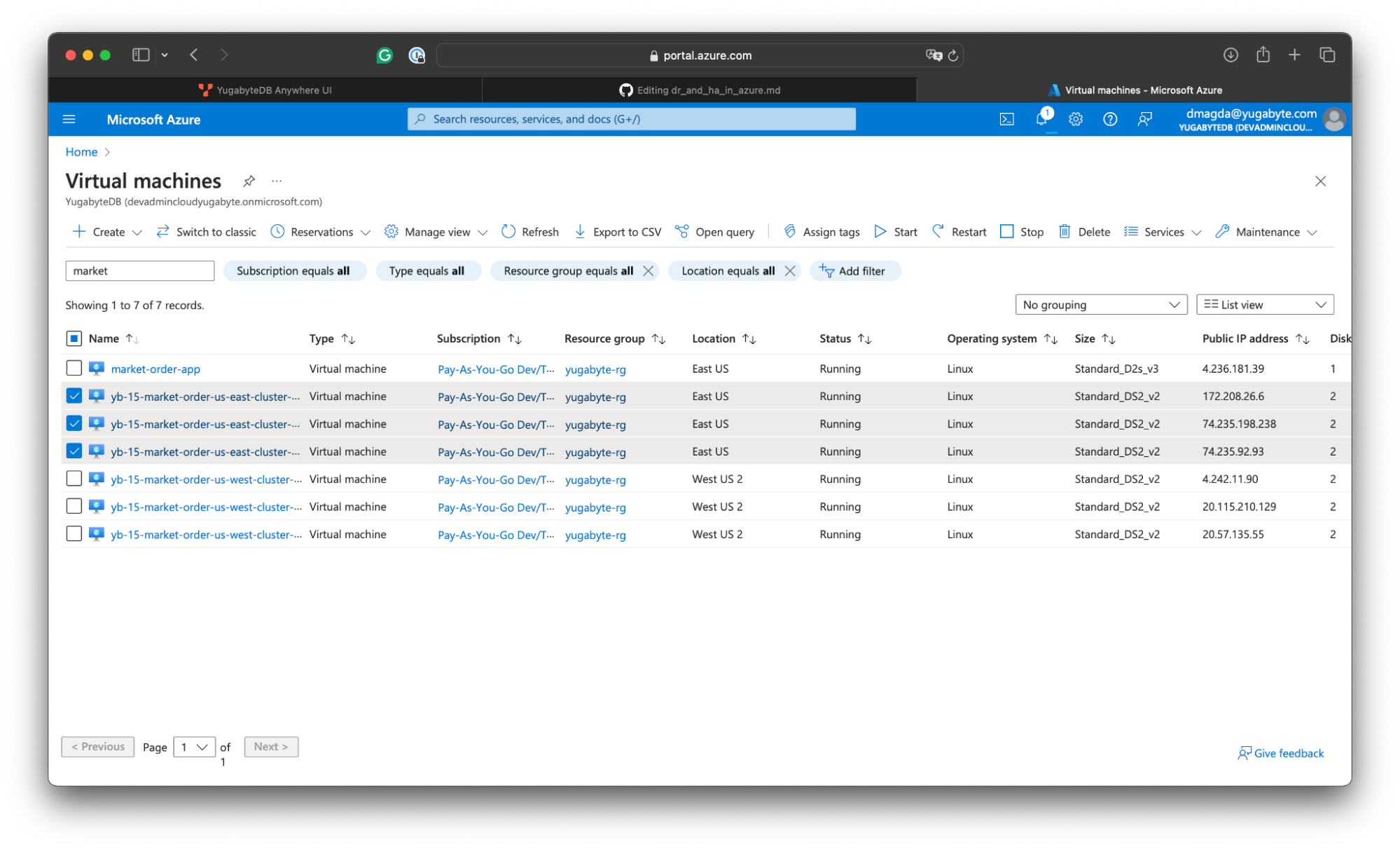
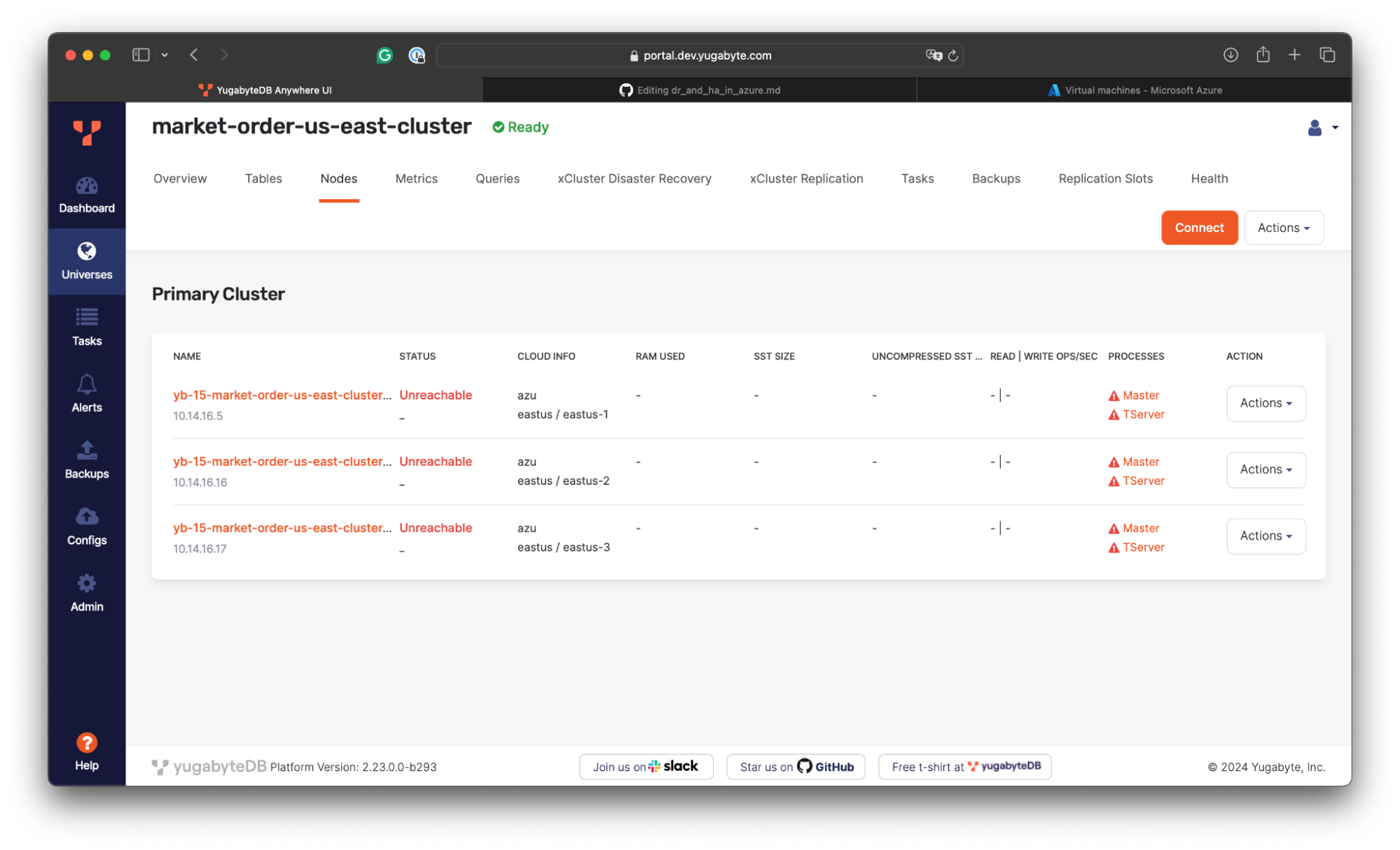
If you check the application logs, you’ll see that the trading app lost connection to the database and generates exceptions. Let’s perform the failover to the secondary region in the US West:
- On the xCluster DR tab, initiate the failover :According to the xCluster statistics, the potential data loss (or RPO) might be around 1ms.
- Wait for the failover to complete:
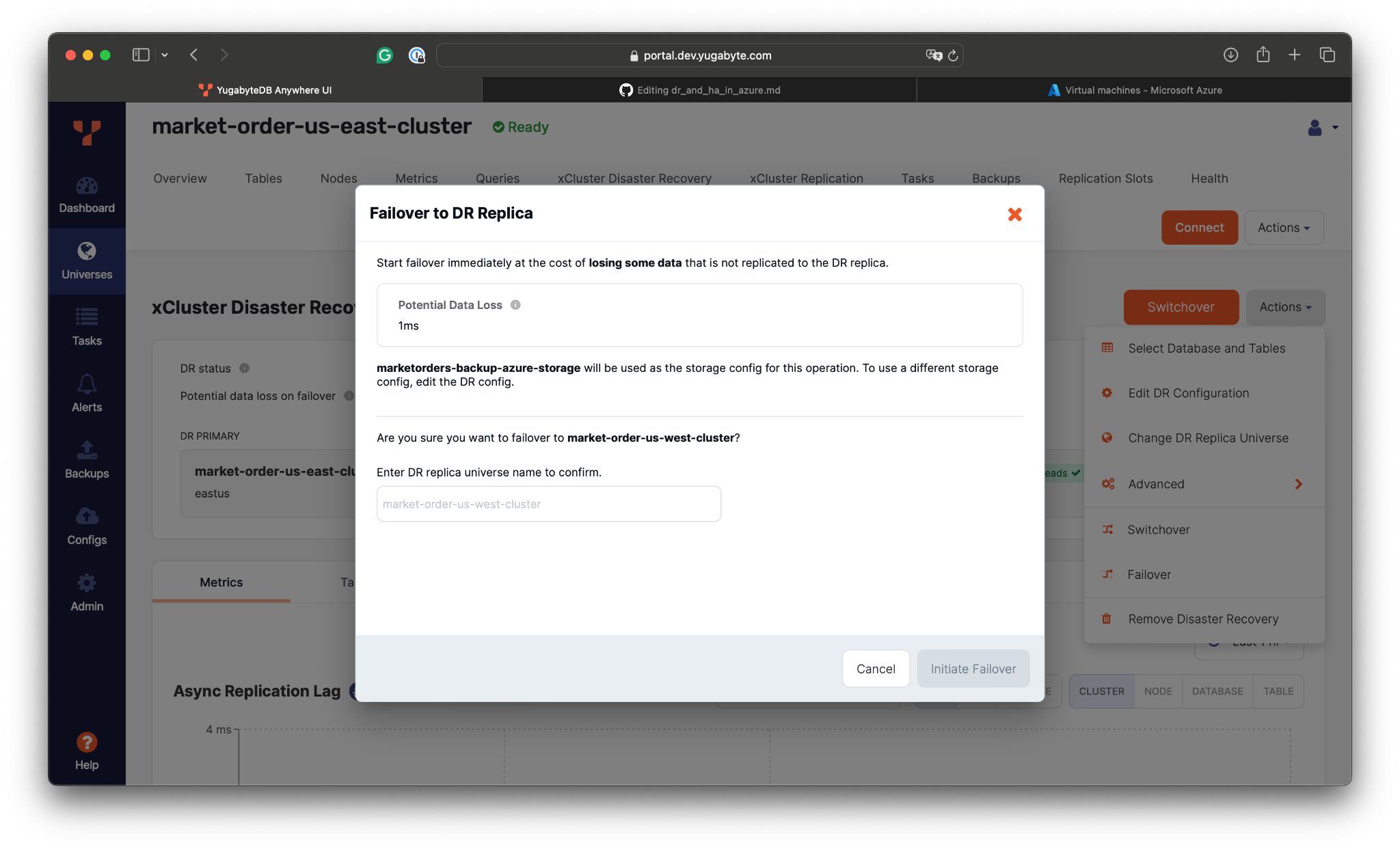 According to the xCluster statistics, the potential data loss (or RPO) might be around 1ms.
According to the xCluster statistics, the potential data loss (or RPO) might be around 1ms.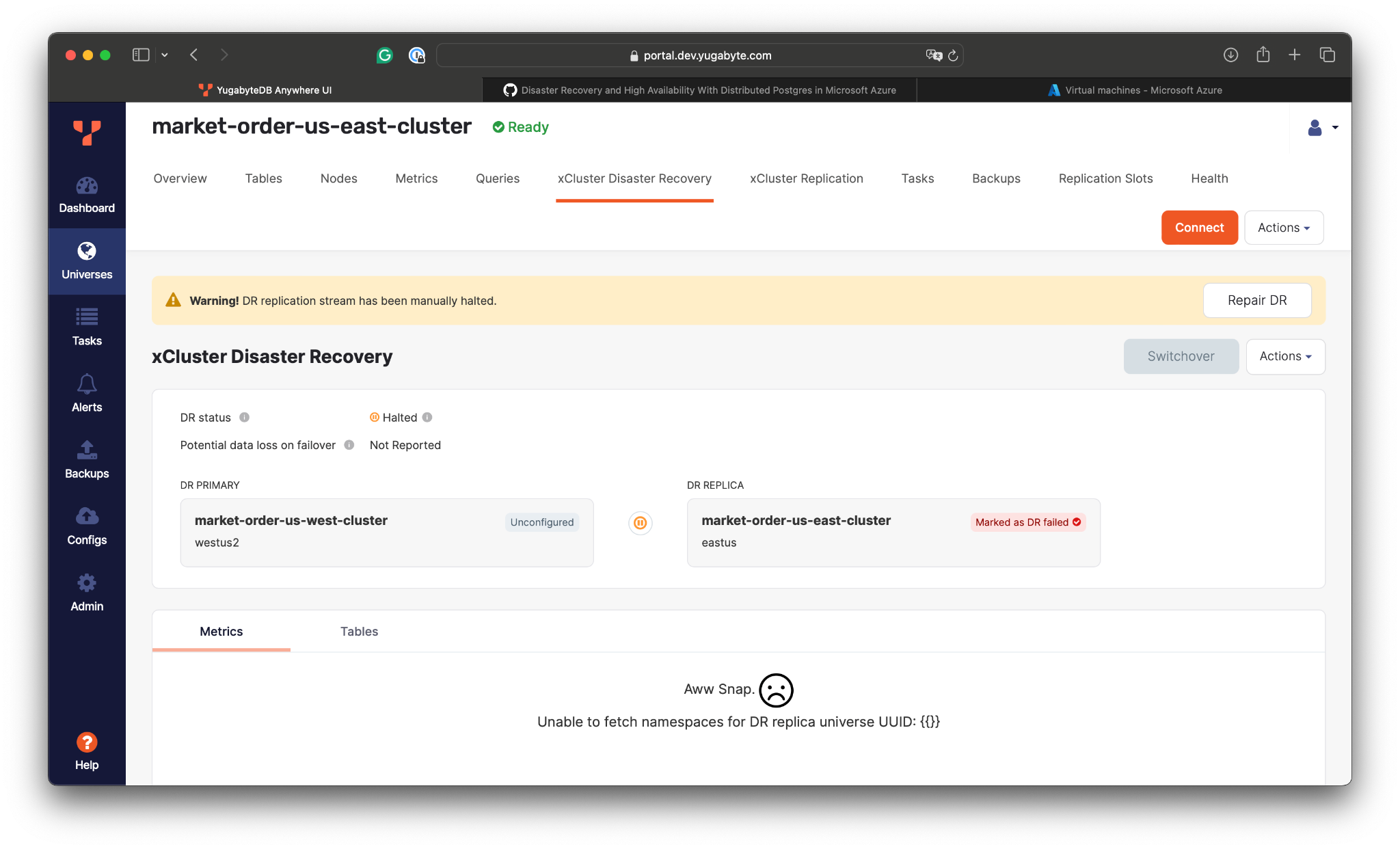
The xCluster DR will promote the cluster in the US West to the primary and will put replication on hold because, as of now, there is no secondary cluster to replicate changes to.
Next, let’s restart the trading application by connecting it to the US West database instance:
- The trading app uses a sequence to generate IDs for the trades. Currently, the sequence and DDL changes are not replicated between the clusters. Therefore, we need to connect to the US West database and restart the sequence with an ID that is larger than the ID of the latest trade:
yugabyte=# select max(id) from trade; max ------ 8025 (1 row) yugabyte=# alter sequence trade_id_seq restart with 8026; ALTER SEQUENCE yugabyte=# select last_value from trade_id_seq; last_value ------------ 8026 (1 row)Note, we use sequences here for educational purposes. You’re encouraged to use other ways for unique IDs generation for your distributed database deployments (such as UUIDs).
- Create the
properties\yugabyte-west.propertiesconfiguration file with the settings that let the application connect to the database in the US West:dataSourceClassName = com.yugabyte.ysql.YBClusterAwareDataSource maximumPoolSize = 5 dataSource.user=yugabyte dataSource.password=password dataSource.databaseName=yugabyte dataSource.portNumber=5433 dataSource.serverName=10.12.23.37 dataSource.additionalEndpoints = 10.12.23.42:5433,10.12.23.36:5433
- Restart the application using the new database connectivity settings:
java -jar target/market-orders-app.jar connectionProps=./properties/yugabyte-west.properties tradeStatsInterval=2000
The trading application will successfully connect to the database in the US West and will continue processing the market orders:
============= Trade Stats ============ Trades Count: 9455 Stock Total Proceeds Google 248102.734375 Linen Cloth 205001.031250 Bespin Gas 165442.531250 Apple 162154.828125 Elerium 118994.203125 Fill or kill trades: 805
Overall, using xCluster DR, we managed to tolerate region-level outages with an RPO of 1ms. The RTO for failover is very low and depends on how long it takes the application to switch the connections from one database cluster to another.
Restoring the Failed Region and Cluster
There is a calm after every storm. Imagine that the failed region in the US East is now restored, and we want to switch back to it.
First, let’s bring the failed cluster back to the fleet:
- Go to Azure Portal and enable all previously stopped VMs from the US East:
- Confirm the US East cluster became operational:
- Initiate the DR repair by using the US East cluster as a new replica:
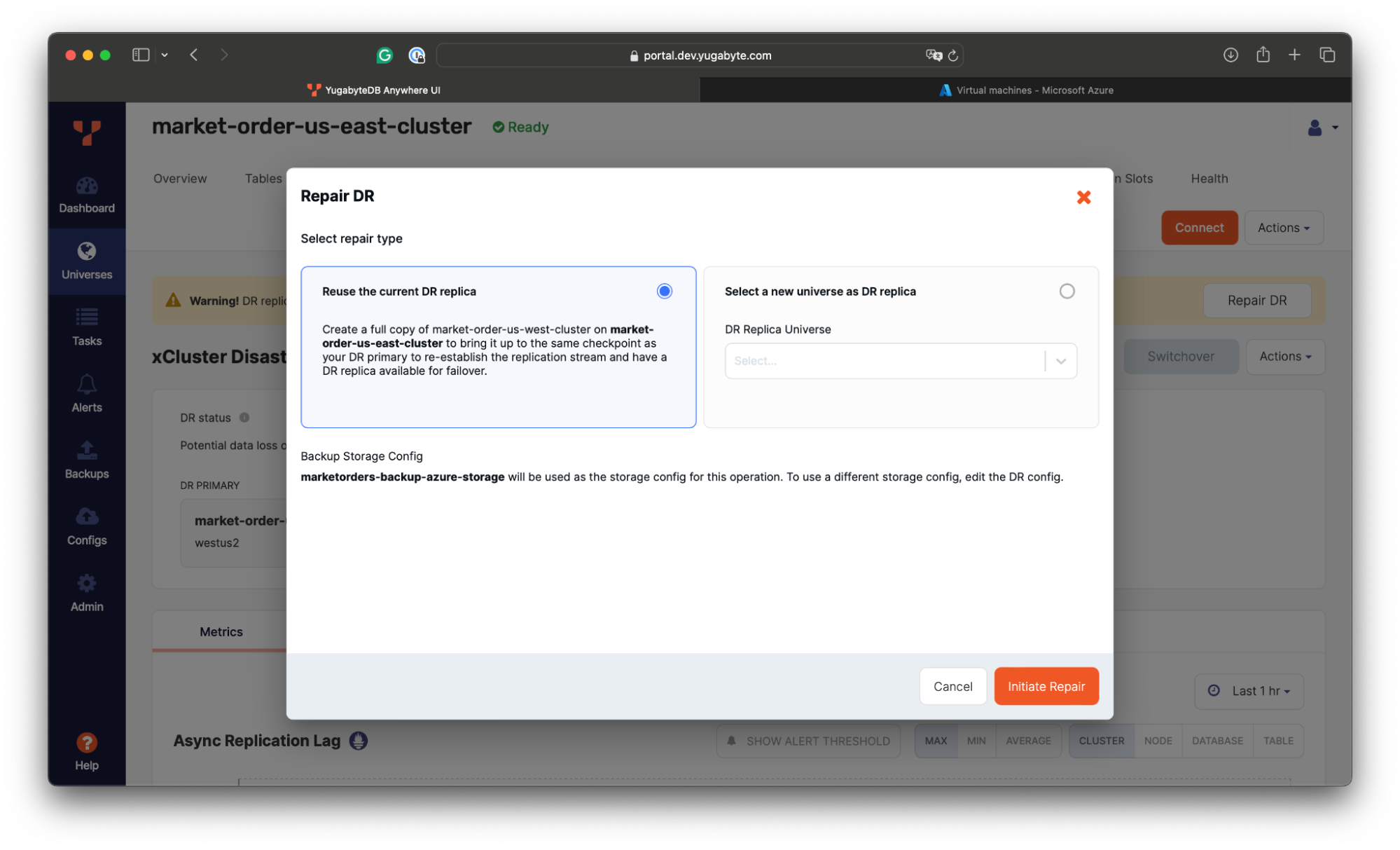
During the repair, the xCluster DR will take a full copy of data from the US West cluster and apply it to the database in the US East region. Then, it will enable replication from the West to the East.
 Note, the application workload is not impacted during the repair. The application will continue running normally.
Note, the application workload is not impacted during the repair. The application will continue running normally.
Performing the Switchover to US East
With the US East database cluster fully operational and receiving the latest changes, we’re ready to perform the switchover by promoting the US East cluster back to the primary.
As the switchover waits for all data to be committed on the DR replica before switching over, the RPO is 0, meaning no data loss. As for the RTO, it primarily depends on how quickly the application workload is switched between the database clusters.
- Stop the application
- Begin the switchover using the xCluster DR:
- Wait for the switchover to finish:
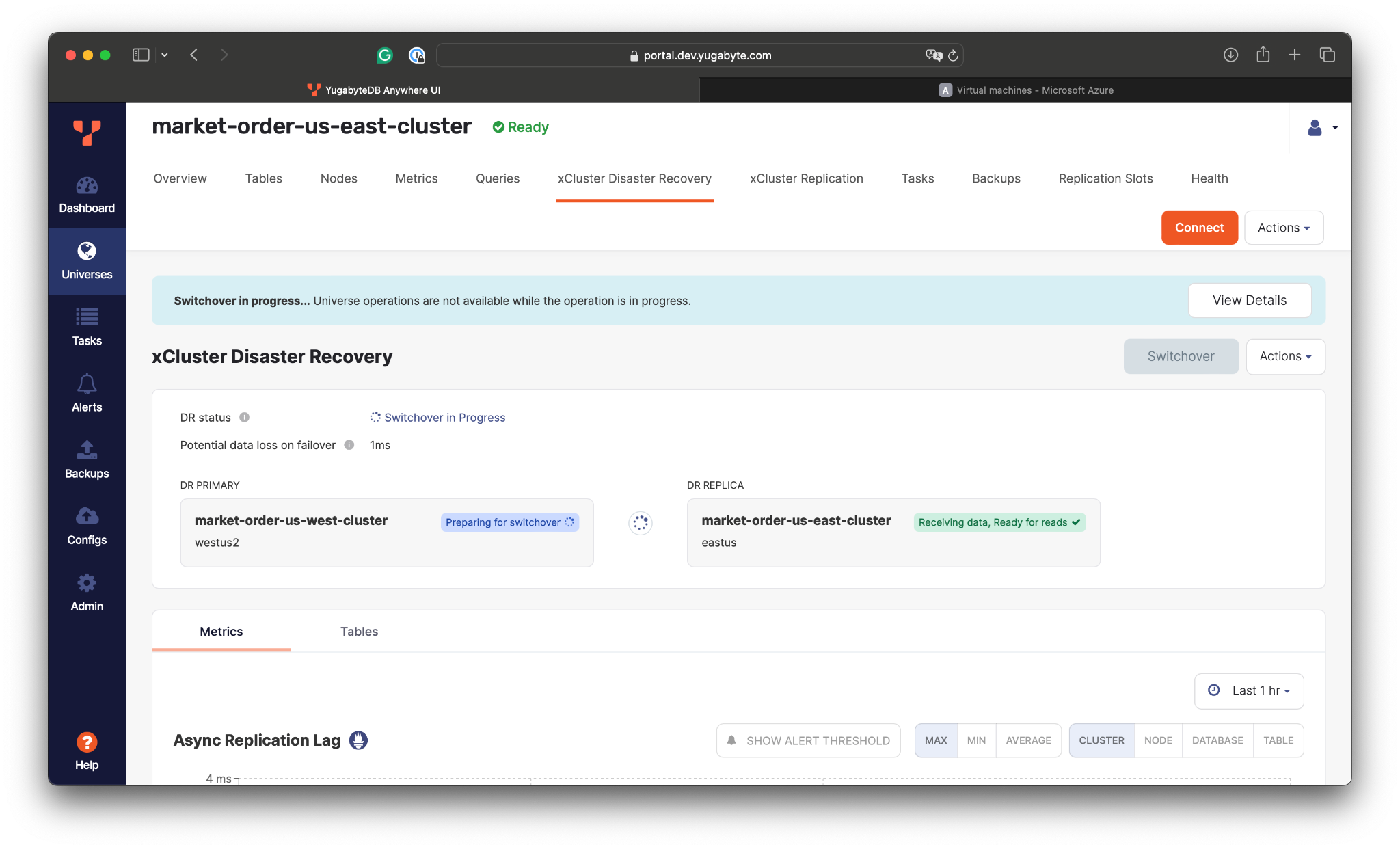
Once the US East cluster is promoted to the primary and the replication is set from the East to the West, connect to the cluster in the East and update the sequence counter for the trades:
select max(id) from trade; max ------- 13313 (1 row) alter sequence trade_id_seq restart with 13314; ALTER SEQUENCE
Finally, restart the application by connecting it to the primary database instance in the US East:
java -jar target/market-orders-app.jar connectionProps=./properties/yugabyte.properties tradeStatsInterval=2000
The application connects successfully and starts serving the market orders:
============= Trade Stats ============ Trades Count: 13345 Stock Total Proceeds Google 456707.875000 Linen Cloth 389887.812500 Bespin Gas 316923.781250 Apple 313840.500000 Elerium 239663.468750 Fill or kill trades: 1571
Conclusion
In this guide, we explored how to achieve disaster recovery for cloud-native PostgreSQL deployments using YugabyteDB. By leveraging YugabyteDB’s distributed SQL database and its xCluster disaster recovery (DR) feature, we demonstrated how to maintain high availability and ensure data integrity with a recovery point objective (RPO) of 1ms and a recovery time objective (RTO) of just a few seconds for a multi-region setting.
We configured and deployed primary and secondary YugabyteDB clusters in the US East and West regions, showing how xCluster DR manages failover and switchover processes seamlessly. This setup ensured the continued operation of a trading application even during outages.
Want to Learn More?
For further insight, watch our hands-on step-by-step video, which demonstrates how you can achieve and test disaster recovery by running YugabyteDB in a configuration with two cloud regions.
Plus, join our upcoming live stream on June 20th to see other multi-region deployment options in action, including configurations that achieve RPO=0 and RTO in a few seconds.


